1. 共享内存的引入
共享内存因为更靠近计算单元,所以访问速度更快
共享内存通常可以作为访问全局内存的缓存使用, 可以理解为每次需要内存都去全局内存里面拿,很费事情的,共享内存里面去拿
可以利用共享内存实现线程间的通信
通常与__syncthreads同时出现,这个函数是同步block内的所有线程,全部执行到这一行才往下走
常见的使用方式,通常是在线程id为0的时候从global memory取值,然后syncthreads,然后再使用
2. CU文件
#include <cuda_runtime.h>
#include <stdio.h>
//demo1 //
/*
demo1 主要为了展示查看静态和动态共享变量的地址
可以指定内存大小
*/
const size_t static_shared_memory_num_element = 6 * 1024; // 6KB 静态共享内存
__shared__ char static_shared_memory[static_shared_memory_num_element];
__shared__ char static_shared_memory2[2]; // 大小是两字节
__global__ void demo1_kernel()
{
// 无论写多少遍,动态共享内存的指针永远是一个值
extern __shared__ char dynamic_shared_memory[]; // 静态共享变量和动态共享变量在kernel函数内/外定义都行,大小不能指定的
extern __shared__ char dynamic_shared_memory2[];
printf("static_shared_memory = %p\n", static_shared_memory); // 静态共享变量,定义几个地址随之叠加
printf("static_shared_memory2 = %p\n", static_shared_memory2);
printf("dynamic_shared_memory = %p\n", dynamic_shared_memory); // 动态共享变量,无论定义多少个,地址都一样
printf("dynamic_shared_memory2 = %p\n", dynamic_shared_memory2);
if (blockIdx.x == 0 && threadIdx.x == 0) // 第一个thread
printf("Run kernel.\n");
}
/demo2//
/*
demo2 主要是为了演示的是如何给 共享变量进行赋值
*/
// 定义共享变量,但是不能给初始值,必须由线程或者其他方式赋值
__shared__ int shared_value1;
__global__ void demo2_kernel()
{
__shared__ int shared_value2;
// 两个block第一个thread都是0
if (threadIdx.x == 0)
{
// 在线程索引为0的时候,为shared value赋初始值
if (blockIdx.x == 0)
{
shared_value1 = 123;
shared_value2 = 55;
}
else
{
shared_value1 = 331;
shared_value2 = 8;
}
}
// 等待block内的所有线程执行到这一步
__syncthreads();
printf("%d.%d. shared_value1 = %d[%p], shared_value2 = %d[%p]\n",
blockIdx.x, threadIdx.x,
shared_value1, &shared_value1,
shared_value2, &shared_value2);
}
void launch()
{
// 第三个参数 12 是用来动态的指定共享内存的
demo1_kernel<<<1, 1, 12, nullptr>>>(); // 启动1个线程,分配12个字节共享内存,使用默认流
// 两个block, 每个block5个线程,十个线程被划分成两个快
demo2_kernel<<<2, 5, 0, nullptr>>>();
}
3. cpp文件
#include <cuda_runtime.h>
#include <stdio.h>
#define checkRuntime(op) __check_cuda_runtime((op), #op, __FILE__, __LINE__)
bool __check_cuda_runtime(cudaError_t code, const char* op, const char* file, int line){
if(code != cudaSuccess){
const char* err_name = cudaGetErrorName(code);
const char* err_message = cudaGetErrorString(code);
printf("runtime error %s:%d %s failed. \n code = %s, message = %s\n", file, line, op, err_name, err_message);
return false;
}
return true;
}
void launch();
int main(){
// 越近越快
// 越近越贵,所以为啥共享内存在现实中这么小
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
printf("prop.sharedMemPerBlock = %.2f KB\n", prop.sharedMemPerBlock / 1024.0f);
launch();
checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaDeviceSynchronize());
printf("done\n");
return 0;
}
4. 代码解析解析
从main函数看起
int main(){
// 越近越快
// 越近越贵,所以为啥共享内存在现实中这么小
// 储存当前设备信息
cudaDeviceProp prop;
checkRuntime(cudaGetDeviceProperties(&prop, 0));
printf("该设备上共享内存大小为: %f\n", prop.sharedMemPerBlock / 1024.f);
launch();
// checkRuntime(cudaPeekAtLastError());
checkRuntime(cudaDeviceSynchronize());
printf("done\n");
return 0;
}
定义一个cudaDeviceProp类型的变量,是一个结构体类型,它用于描述一个 CUDA 设备的属性信息,比如支持的 CUDA 版本、硬件信息、内存信息、线程块大小、寄存器文件等等。
用cudaGetDeviceProperties的API来获取当前设备的信息,返回的指针指向结构体
prop.sharedMemPerBlock 表示每个线程块可以使用的共享内存的大小,单位是字节(byte)。而在这行代码中,除以 1024.0f 的目的是将其转换为千字节(kilobyte)。因此,这行代码的输出结果表示每个线程块可以使用的共享内存大小,以千字节为单位。
cudaPeekAtLastError() 用于获取最后一个执行的CUDA Runtime API调用的错误码,如果没有错误发生则返回 cudaSuccess。
cudaDeviceSynchronize() 则是等待CUDA设备上的所有操作完成。在CUDA程序中,内核启动是异步的,也就是说在内核启动之后,主机线程会继续执行,而不会等待内核完成。
cudaDeviceSynchronize() 就是用来等待内核完成的。
5. demo1
#include <cuda_runtime.h>
#include <stdio.h>
//demo1 //
/*
demo1 主要为了展示查看静态和动态共享变量的地址
静态可以指定内存大小
*/
// 静态共享内存, 可以指定大小,定义多了,指针也会随之增加
// 静态共享内存是可以在kernel函数外面定义的,而共享内存是不可以的
const size_t static_shared_memory_num_element = 6 * 1024; // 6kb
__shared__ char static_shared_memory[static_shared_memory_num_element];
__shared__ char static_shared_memory2[2];
// 定义动态共享内存, 这个也能够在kernel函数外部进行的
// 而且还没有办法定义大小,这个大小的调用的第三个参数
// 无论定义多少个,地址都是一样
extern __shared__ char dynaminc_shared_memory[];
extern __shared__ char dynaminc_shared_memory1[];
__global__ void demo1_kernel()
{
// 打印静态共享内存的指针,这里指针式不同的
printf("static_shared_memory = %p\n", static_shared_memory);
printf("static_shared_memory2 = %p\n", static_shared_memory2);
// 要使用这个global的目的就是为了分配共享内存的大小,普通函数不行
printf("第1个定义的动态共享内存指针: %p\n", dynaminc_shared_memory);
printf("第2个定义的动态共享内存指针: %p\n", dynaminc_shared_memory1);
}
void launch()
{
// 启动一个block, 一个线程, 分配12个字节的内存,是用默认流nullptr
// 12这个参数是用来指定动态共享内存的
demo1_kernel<<<1, 1, 12, nullptr>>>();
}
这个demo主要是查看静态共享和动态共享内存地址的
静态共享内存和动态共享内存都是可以在kernel函数外部去定义的
使用extern __shared__来声明共享内存是为了让编译器知道这是一段共享内存,并且在编译时动态分配内存。因此,这种方式声明的共享内存也被称为动态共享内存。需要注意的是,extern __shared__不能用于静态共享内存,因为静态共享内存的大小在编译时就已经确定了,不能动态分配。
静态是可以指定内存大小的,因为可以指定内存大小,其实用普通函数调用也是可以的
但是动态共享内存的大小是靠kernel函数去非陪的,普通函数是不行的
demo1_kernel<<<1, 1, 12, nullptr>>>(); 一个block, 一个线程,分配12个字节的动态内存,使用默认stream(nullptr)
定义多个静态共享内存,地址也会增加,但是定义多少个动态共享内存,他们都是一个地址
6. demo2
/demo2//
/*
demo2 主要是为了演示的是如何给 共享变量进行赋值
这个经典的使用场景,在第0个线程赋予共享变量,然后其他的线程也可以去使用这个定义的共享变量
*/
// 定义共享变量,但是不能给初始值,必须由线程或者其他方式赋值
__shared__ int shared_value1;
__shared__ int shared_value2;
__global__ void demo2_kernel()
{
// 两个block的第一个threadIdx.x 都是0
if (threadIdx.x ==0)
{
// 0号block的共享变量
if (blockIdx.x == 0)
{
shared_value1 = 111;
shared_value2 = 222;
}
else // 1号block的共享变量
{
shared_value1 = 333;
shared_value2 = 444;
}
}
// 等待block所有线程执行到这一步
__syncthreads();
printf("%d.%d. shared_value1 = %d[%p], shared_value2 = %d[%p]\n",
blockIdx.x, threadIdx.x,
shared_value1, &shared_value1,
shared_value2, &shared_value2);
}
void launch()
{
// 启动一个block, 一个线程, 分配12个字节的内存,是用默认流nullptr
// 12这个参数是用来指定动态共享内存的
demo1_kernel<<<1, 1, 12, nullptr>>>();
// 2个block, 每个block5个线程,10个线程被划分成两块
demo2_kernel<<<2, 5, 0, nullptr>>>();
}
共享内存也是kernel函数内外都可以实现的
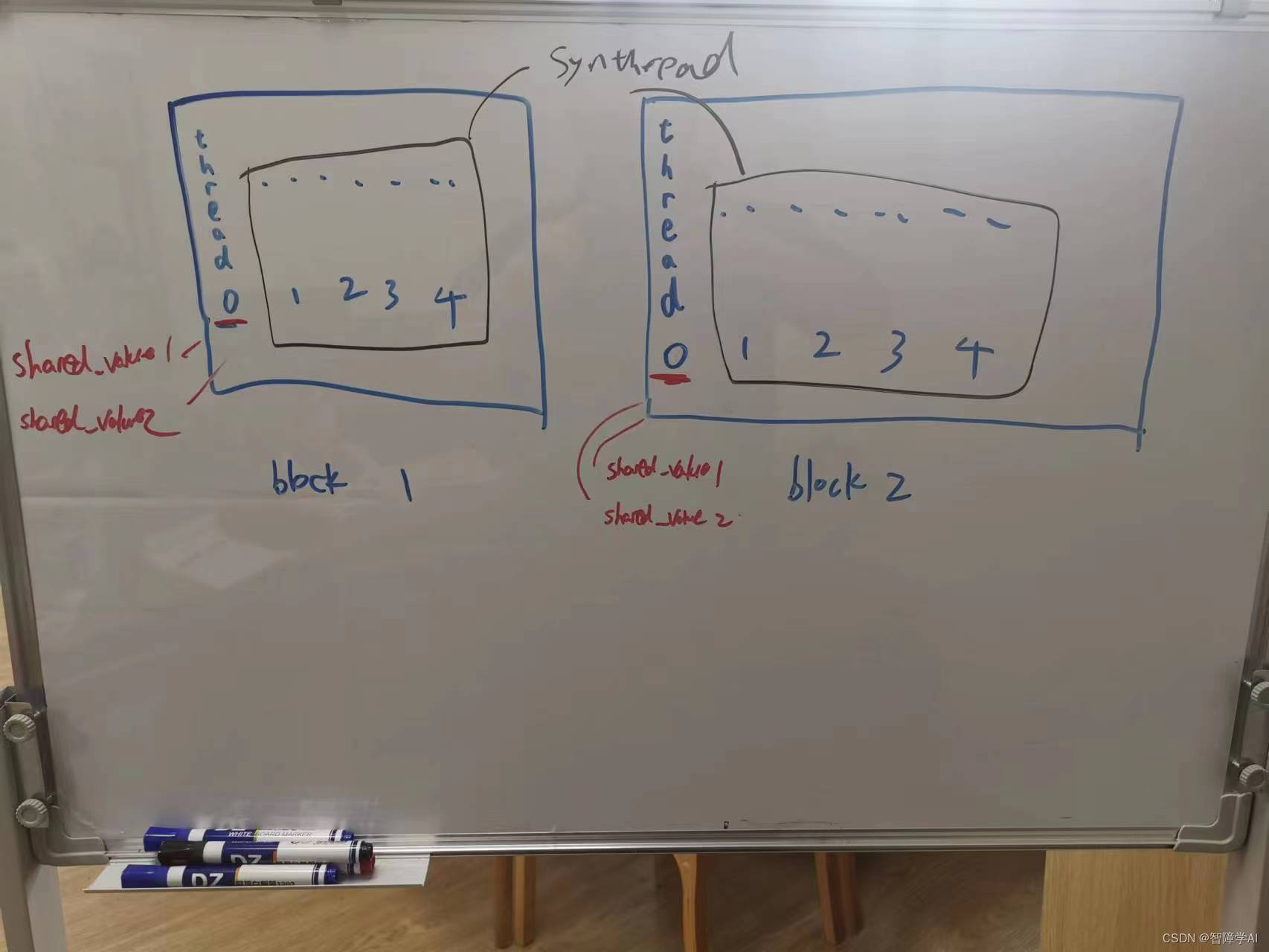
这是一个经典的共享内存的应用场景,在0号的thread给了共享变量,其他的thread都可以使用
两个block的0号thread进入第一个if() 然后根据blockId分配不一样的共享变量
其他的八个thread走到__synthreads()等待两个thread0被赋予共享变量然后一起走下去打印共享变量
如图所示
运行结果如下:
该设备上共享内存大小为: 48.000000
static_shared_memory = 0x7f6292000000
static_shared_memory2 = 0x7f6292001800
第1个定义的动态共享内存指针: 0x7f6292001810
第2个定义的动态共享内存指针: 0x7f6292001810
0.0. shared_value1 = 111[0x7f6292000000], shared_value2 = 222[0x7f6292000004]
0.1. shared_value1 = 111[0x7f6292000000], shared_value2 = 222[0x7f6292000004]
0.2. shared_value1 = 111[0x7f6292000000], shared_value2 = 222[0x7f6292000004]
0.3. shared_value1 = 111[0x7f6292000000], shared_value2 = 222[0x7f6292000004]
0.4. shared_value1 = 111[0x7f6292000000], shared_value2 = 222[0x7f6292000004]
1.0. shared_value1 = 333[0x7f6292000000], shared_value2 = 444[0x7f6292000004]
1.1. shared_value1 = 333[0x7f6292000000], shared_value2 = 444[0x7f6292000004]
1.2. shared_value1 = 333[0x7f6292000000], shared_value2 = 444[0x7f6292000004]
1.3. shared_value1 = 333[0x7f6292000000], shared_value2 = 444[0x7f6292000004]
1.4. shared_value1 = 333[0x7f6292000000], shared_value2 = 444[0x7f6292000004]
done
爱情故事
有一个很漂亮的女孩,我曾经以为我于她而言,是唯一一个执行流程的线程,她给我发的每一条消息都不敷衍,很详细。有一天我在其他男生手机里看到了一样的消息,我开始慌了,我去检查我自己的身份,警察叔叔说,你的心脏长了一个第二个block里面的第三个thread。有一天晚上我趁着她不注意,从她的钱包偷看了她的身份证,她的真实身份是一个可以被多个线程同时执行的kernel函数,而且还可以分布在多个block上。
记得那天晚上的雨很大,我没有想到我可以独自拥有她,我只求能够成为她的第0个thread, 那样,她在分配shared_value的时候,是分配给我的。然后其他的thread都只能在__synthread()的地方等待我一起走下