它的实现也是极其容易的。
Its implementation is extremely easy aswell.
sigmoid函数将节点的输出范围限制为单位1,没有考虑输入值的大小。
The sigmoid function limits the node’soutputs to the unity regardless of the input’s magnitude.
相反,ReLU函数不受这样的限制。
In contrast, the ReLU function does notexert such limits.
如此简单的变化导致了深度神经网络学习性能的急剧提高,难道不是很有意思吗?
Isn’t it interesting that such a simplechange resulted in a drastic improvement of the learning performance of thedeep neural network?
反向传播算法中需要的另一个元素是ReLU函数的导数。
Another element that we need for the back-propagationalgorithm is the derivative of the ReLU function.
根据ReLU函数的定义,它的导数为:
By the definition of the ReLU function, itsderivative is given as:
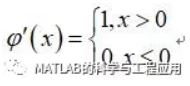
此外,交叉熵驱动的学习规则可以改善性能,如第3章所述。
In addition, the cross entropy-drivenlearning rules may improve the performance, as addressed in Chapter 3.
此外,先进的梯度下降法是一种较好的实现最优值的数值方法,对深度神经网络的训练也有一定的意义。
Furthermore, the advanced gradient descent,which is a numerical method that better achieves the optimum value, is alsobeneficial for the training of the deep neural network.
过度拟合(Overfitting)
深度神经网络特别容易过拟合的原因是模型变得更加复杂,因为模型中包含更多的隐藏层,以及更多的权值。
The reason that the deep neural network isespecially vulnerable to overfitting is that the model becomes more complicatedas it includes more hidden layers, and hence more weight.
如第1章所述,一个复杂的模型更容易被过度拟合。
As addressed in Chapter 1, a complicatedmodel is more vulnerable to overfitting.
可能会陷入两难的境地——为了更高的性能而加深神经网络的层数,但使得神经网络面临机器学习的挑战。
Here is the dilemma—deepening the layersfor higher performance drives the neural network to face the challenge ofMachine Learning.
最具代表性的解决方案是dropout,它只训练随机选择的一些节点,而不是整个网络。
The most representative solution is thedropout, which trains only some of the randomly selected nodes rather than theentire network.
这是非常有效的,而它的实现并不十分复杂。
It is very effective, while itsimplementation is not very complex.
图5-4解释了dropout的概念。
Figure 5-4 explains the concept of thedropout.
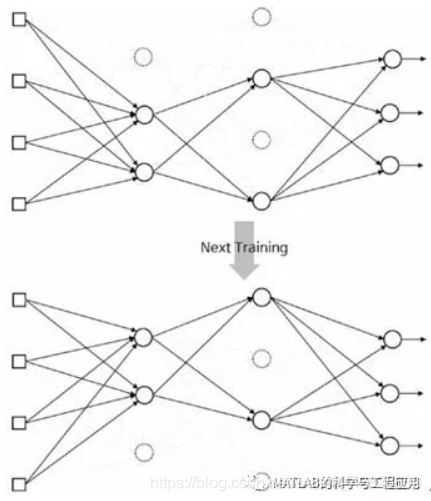
图5-4 dropout是随机选择一些节点并将它们的输出设置为零(即这些被选择的节点不参与网络的训练运算)Dropout is where some nodes are randomly selected and their outputsare set to zero to deactivate the nodes
随机选择一些节点并将它们的输出设置为零。
Some nodes are randomly selected at acertain percentage and their outputs are set to be zero to deactivate thenodes.
dropout有效地防止过度拟合,因为它不断地改变训练过程中的节点和权重。
The dropout effectively preventsoverfitting as it continuously alters the nodes and weights in the trainingprocess.
对于隐藏层和输入层,dropout的合适比例分别约为50%和25%。
The adequate percentages of the dropout areapproximately 50% and 25% for hidden and input layers, respectively.
用于防止过拟合的另一种流行方法是将正则化项添加到代价函数中,其中正则化项提供权重的幅度大小。
Another prevailing method used to preventoverfitting is adding regularization terms, which provide the magnitude of theweights, to the cost function.
——本文译自Phil Kim所著的《Matlab Deep Learning》
更多精彩文章请关注微信号: