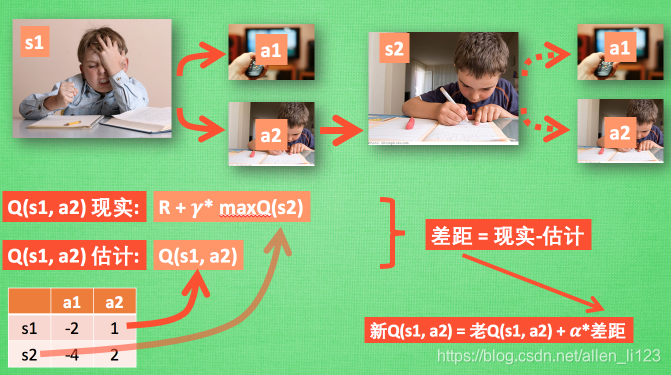
标签(): 机器学习
当学习状态空间很大,例如围棋的学习中,由于状态空间过大导致Q表远远超过内存,所以在复杂学习情况下Q表更新并不适用。
取而代之的是用神经网络当做Q表使用,第一种神经网络是输入状态和动作,输出动作的评价值,第二种神经网络是输入状态输出所有动作和该动作的评价值,再从中选取评价高的动作进行决策。
算法更新:
为什么需要DQN
一般的强化学习例如Q学习相当于不断进行仿真获取数据并从表中寻找最优解进行选取,但是现实情况中例如连续控制问题状态空间是无限的,所以一般的Q学习并不能满足问题的求解
一方面神经网络能拟合参数,能够自主学习数据,但是极其依赖数据集
另一方面,强化学习不能拟合参数,能够自主仿真,数据集由仿真所得
所以在没有数据集的情况又需要数据集进行拟合的问题上应当选用深度强化学习
DQN与Q学习?
在引入DQN之前我们看一个DQN解决的一个连续控制的问题。(后附代码)
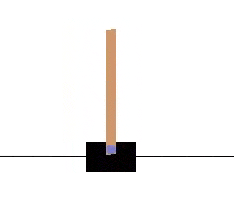
我们通过控制小车向左向右移动,使棒子始终保持竖立状态
通过对gym环境的查询,我们知道该游戏有四个信息,但是我们并不知道信息所代表的含义
我们的输入有两种,向左或者向右
基于以上信息建立一种输入使棍子始终保持平衡
在此,我们使用深度强化学习中的DQN解决此问题
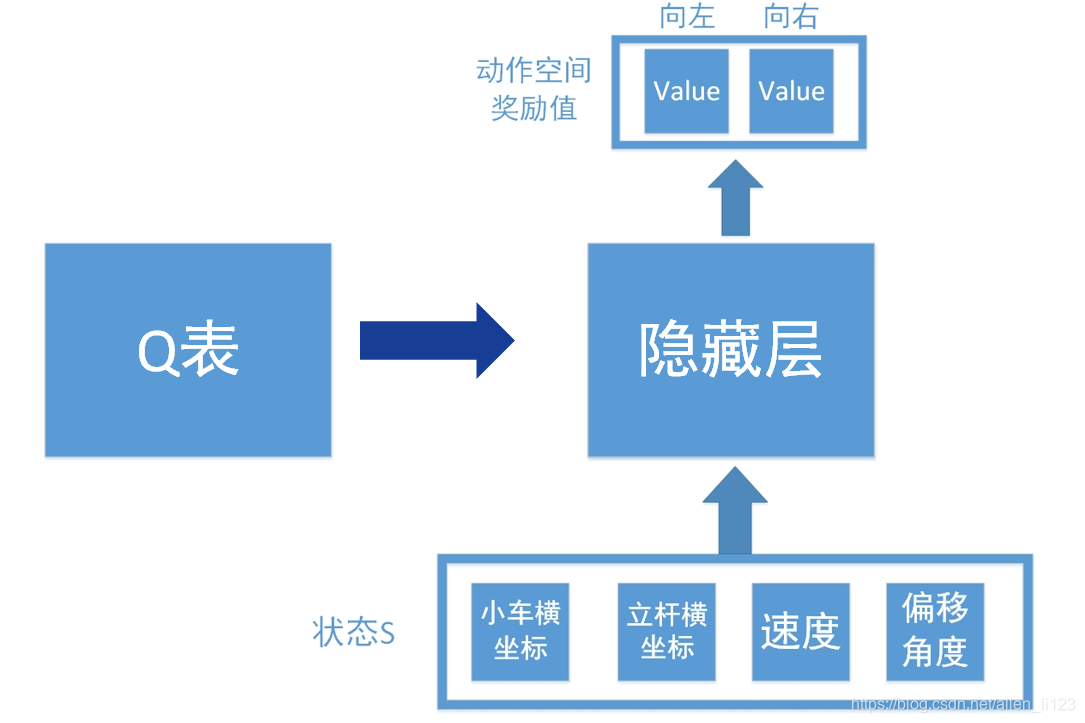
假设我们如果使用Q学习解决此类问题,则结构图如下
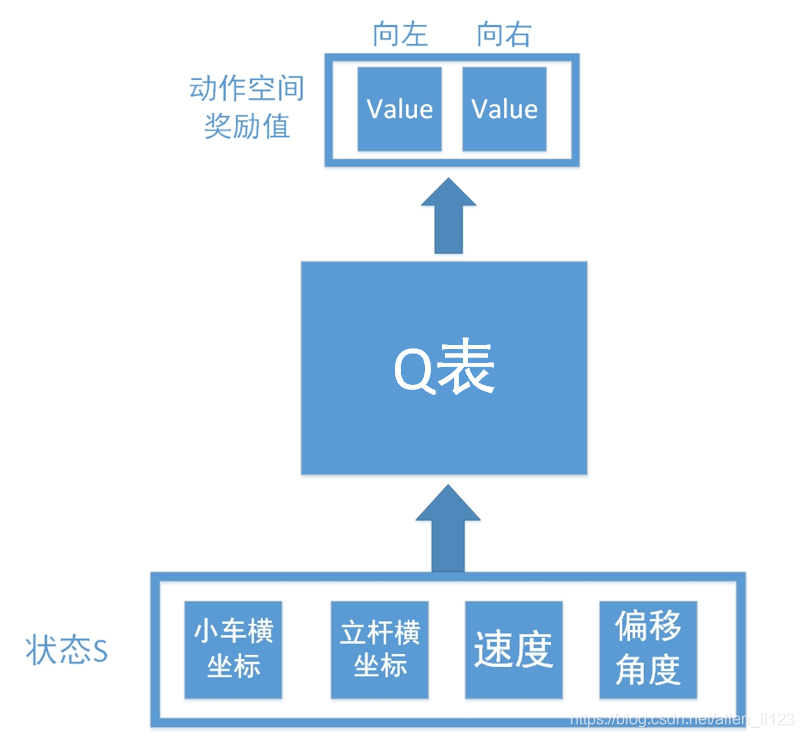
输入为环境反馈的四个信息,输出为向左向右查找得到的数值。但是正如之前说的,连续控制存在无限可能,如果不能拟合数据很难学出效果,所以我们加入了神经网络如下:
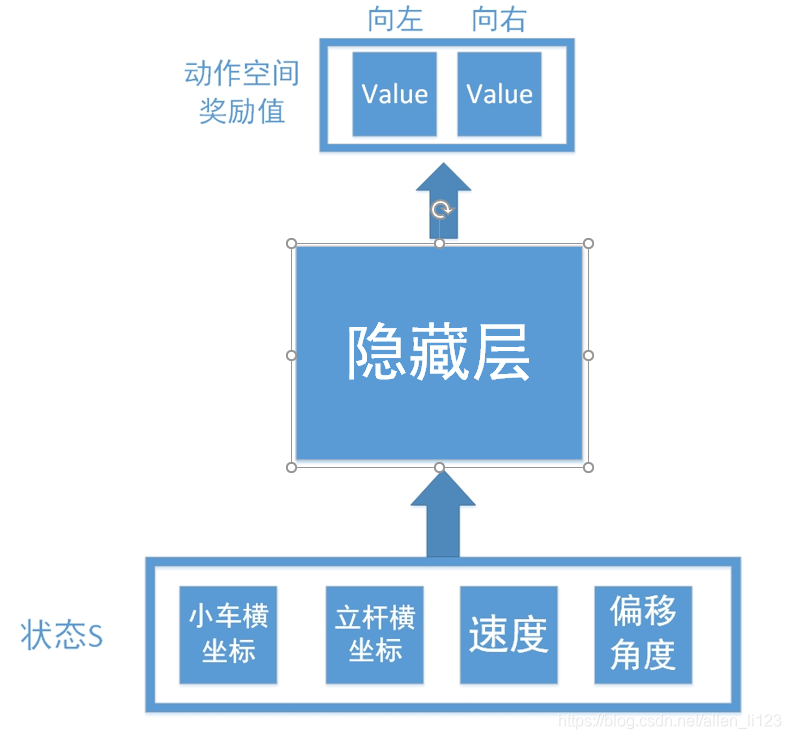
将Q表换为隐藏层,这样就相当于一个输入层为4个节点,输出层为2个节点的神经网络。
将获得的数据放入神经网络进行拟合而不是放入Q表存储就是DQN与Q学习的不同之处
此外为了消除数据集之间的关联性以及提高数据集的利用效率,需要将仿真数据放入Q表中,在每次拟合时随机抽取一个batch进行拟合。
另外在改进的DQN中,Q表也是用神经网络进行存储,在一定时间后,右侧所训练的神经网络完全赋值给与左侧神经网络实现数据更新
DQN算法更新

