DQN算法原理
一、DQN算法是什么
DQN,即深度Q网络(Deep Q-network),是指基于深度学习的Q-Learing算法。
回顾一下Q-Learing:强化学习——Q-Learning算法原理
Q-Learing算法维护一个Q-table,使用表格存储每个状态s下采取动作a获得的奖励,即状态-价值函数Q(s,a),这种算法存在很大的局限性。在现实中很多情况下,强化学习任务所面临的状态空间是连续的,存在无穷多个状态,这种情况就不能再使用表格的方式存储价值函数。
为了解决这个问题,我们可以用一个函数Q(s,a;w)来近似动作-价值Q(s,a),称为价值函数近似Value Function Approximation,我们用神经网络来生成这个函数Q(s,a;w),称为Q网络(Deep Q-network),w是神经网络训练的参数。
二、DQN训练过程
神经网络的的输入是状态s,输出是对所有动作a的打分
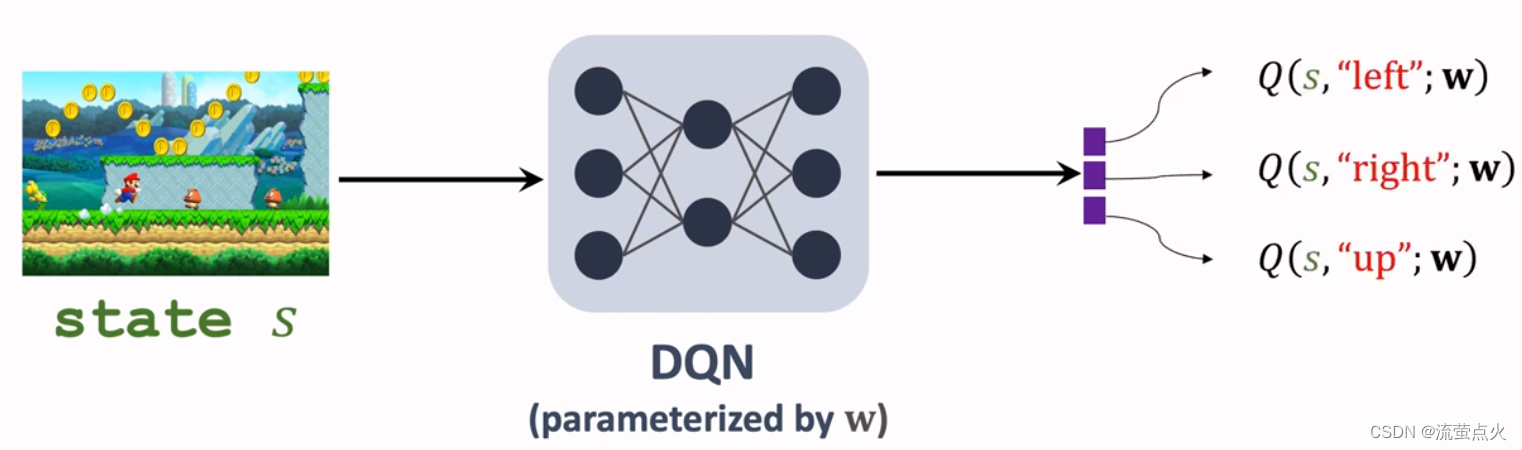
图源于:Shusen Wang深度强化学习课程
神经网络的训练是一个最优化问题,我们需要表示网络输出和标签值之间的差值,作为损失函数,目标是让损失函数最小化,手段是通过反向传播使用梯度下降的方法来更新神经网络的参数。
那么Q网络的标签值/目标值是什么呢?
就是TD target : y t = r t + γ ⋅ max a Q ( s t + 1 , a ; w ) {\color{Red}y_t = r_t + \gamma \cdot \max_aQ(s_{t+1},a;w)} yt=rt+γ⋅maxaQ(st+1,a;w)
我们先介绍最原始的DQN算法,后面会加入经验回放、目标函数等技巧。
具体过程:
1、初始化网络,输入状态 s t s_t st,输出 s t s_t st下所有动作的Q值;
2、利用策略(例如 ε − g r e d d y \varepsilon-greddy ε−greddy),选择一个动作 a t a_t at,把 a t a_t at输入到环境中,获得新状态 s t + 1 s_{t+1} st+1 和 r;
3、计算TD target: y t = r t + γ ⋅ max a Q ( s t + 1 , a ; w ) y_t = r_t + \gamma \cdot \max_aQ(s_{t+1},a;w) yt=rt+γ⋅maxaQ(st+1,a;w)
4、计算损失函数: L = 1 / 2 [ y t − Q ( s , a ; w ) ] 2 L = 1/2[y_t - Q(s,a;w)]^2 L=1/2[yt−Q(s,a;w)]2
5、更新Q参数,使得Q( s t s_t st, a t a_t at) 尽可能接近 y t y_t yt,可以把它当做回归问题,利用梯度下降做更新工作;
6、从以上步骤我们得到一个四元组transition: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1),用完之后丢弃掉;
7、输入新的状态,重复更新工作
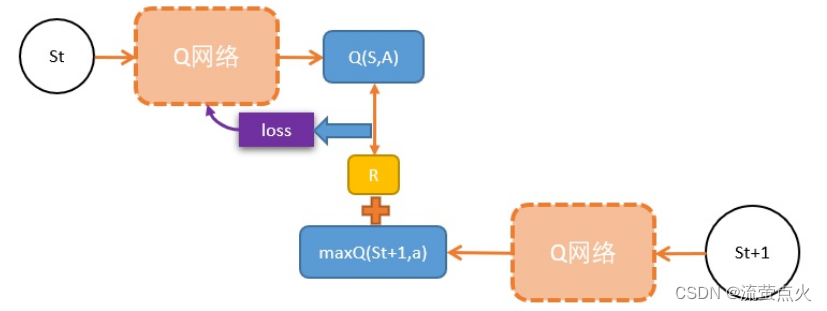
图源于:[知乎.张斯俊] https://zhuanlan.zhihu.com/p/110620815
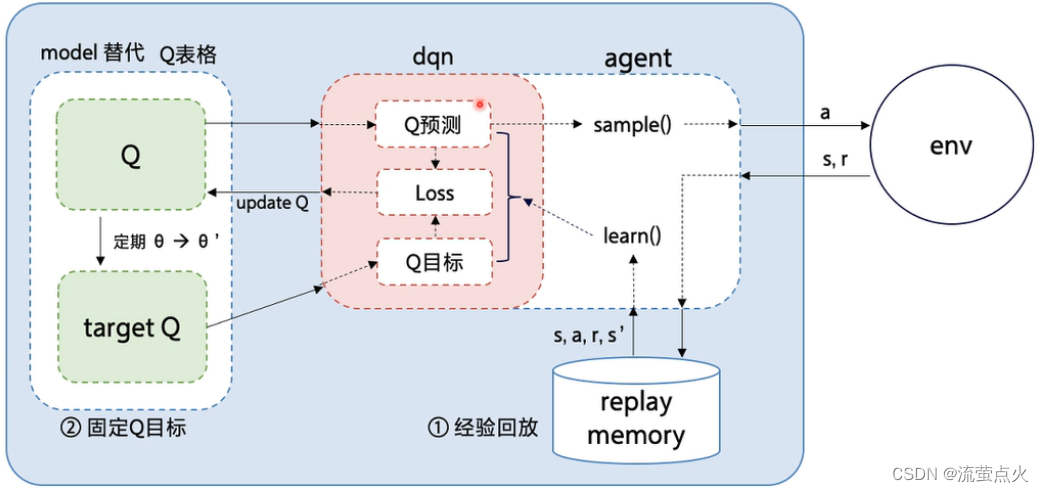
三、经验回放 (Experience Replay)
在理解经验回放之前,先看看原始DQN算法的缺点:
1、用完一个transition: ( s t , a t , r t , s t + 1 ) (s_t,a_t,r_t,s_{t+1}) (st,at,rt,st+1)就丢弃,会造成对经验的浪费;
2、之前,我们按顺序使用transition,前一个transition和后一个transition相关性很强,这种相关性对学习Q网络是有害的。
经验回放可以克服上面两个缺点:
1.把序列打散,消除相关性,使得数据满足独立同分布,从而减小参数更新的方差,提高收敛速度。
2.能够重复使用经验,数据利用率高,对于数据获取困难的情况尤其有用。
在进行强化学习的时候,往往最花时间的步骤是与环境交互,训练网络反而是比较快的,因为我们用GPU训练很快。用回放缓冲区可以减少与环境交互的次数,经验不需要统统来自某一个策略,一些由过去的策略所得到的经验可以再回放缓冲区被使用多次,反复地再利用。
经验回放会构建一个回放缓冲区(replay buffer),存储n条transition,称为经验
某一个策略 π \pi π与环境交互,收集很多条transition,放入回放缓冲区,回放缓冲区中的经验transition可能来自不同的策略。
回放缓冲区只有在它装满的时候才会吧旧的数据丢掉
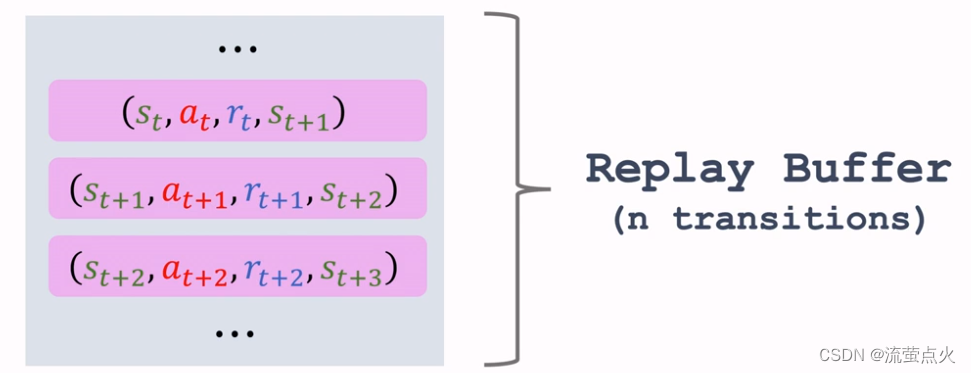 图源于:Shusen Wang深度强化学习课程
图源于:Shusen Wang深度强化学习课程
每次随机抽出一个batch大小的transition数据训练网络,算出多个随机梯度,用梯度的平均更新Q网络参数w
对经验回放的改进:
优先经验回放 (Prioritized Experience Replay):区别在于用非均匀抽样代替均匀抽样。详细的这里就不赘述了。
四、目标网络(Target Network)
为什么要用目标网络?
我引用https://blog.csdn.net/weixin_46133643/article/details/121845874这篇博客的描述:
我们在训练网络的时候,动作价值估计和权重w有关。当权重变化时,动作价值的估计也会发生变化。在学习的过程中,动作价值试图追逐一个变化的回报,容易出现不稳定的情况。
这部分我在有些书上也看到有类似的描述,虽然直觉上认为这样训练的确是不稳定的,但是这种不稳定的具体表现或者说严谨的内部逻辑是怎样的不太理解。
Shusen Wang课程视频中对目标网络这部分讲的比较清楚,这里面存在一个高估(Overestimation) 问题
1、自举(Bootstrapping)
这里引入自举(Bootstrapping) 概念:
Bootstrapping本意是“解鞋带”,来自《吹牛大王历险记》中拔靴自助的典故,是指通过拔鞋带把自己举起来。
在强化学习中,自举是指用后继的估算值,来更新现在状态的估算值。
我们计算的 TD target : y t = r t + γ ⋅ max a Q ( s t + 1 , a ; w ) {\color{Red}y_t = r_t + \gamma \cdot \max_aQ(s_{t+1},a;w)} yt=rt+γ⋅maxaQ(st+1,a;w)
r t {\color{Red} r_t } rt 是根据实际观测得到的值
max a Q ( s t + 1 , a ; w ) {\color{Red}\max_aQ(s_{t+1},a;w)} maxaQ(st+1,a;w) 是根据Q网络在 s t + 1 s_{t+1} st+1时做出的估计值
因此 y t y_t yt有部分是来自Q网络的估算,而我们用 y t y_t yt来更新Q网络本身,所以这属于自举。
我们计算TD target的时候,是最大化Q值的: max a Q ( s t + 1 , a ; w ) \max_aQ(s_{t+1},a;w) maxaQ(st+1,a;w)
这里的最大化和上面的Bootstrapping过程都会引起高估的问题,利用目标网络可以一定程度避免自举,减缓高估问题。具体分析过程这里就不展开叙述了。
2、目标网络:
Target Network是在2015年论文 Mnih et al.Human-level control through deep reinforcement learning. Nature, 2015 中提出的,地址:https://www.nature.com/articles/nature14236/
我们使用第二个网络,称为目标网络, Q ( s , a ; w − ) Q(s,a;{\color{Red} w^-}) Q(s,a;w−),网络结构和原来的网络 Q ( s , a ; w ) Q(s,a; w) Q(s,a;w)一样,只是参数不同 w − ≠ w w^- \neq w w−=w,原来的网络称为评估网络
两个网络的作用不一样:评估网络 Q ( s , a ; w ) Q(s,a; w) Q(s,a;w)负责控制智能体,收集经验;目标网络 Q ( s , a ; w − ) Q(s,a;{\color{Red} w^-}) Q(s,a;w−)用于计算TD target: y t = r t + γ ⋅ max a Q ( s t + 1 , a ; w − ) {\color{Red}y_t = r_t + \gamma \cdot \max_aQ(s_{t+1},a;w^-)} yt=rt+γ⋅maxaQ(st+1,a;w−)
在更新过程中,只更新评估网络 Q ( s , a ; w ) Q(s,a; w) Q(s,a;w)的权重w,目标网络 Q ( s t + 1 , a ; w − ) Q(s_{t+1},a;w^-) Q(st+1,a;w−)的权重 w − w^- w−保持不变。在更新一定次数后,再将更新过的评估网络的权重复制给目标网络,进行下一批更新,这样目标网络也能得到更新。由于在目标网络没有变化的一段时间内回报的目标值是相对固定的,因此目标网络的引入增加了学习的稳定性。
图源于:博客园.jsfantasy强化学习 7——Deep Q-Learning(DQN)公式推导
五、Double DQN
引入目标网络可以一定程度减缓高估问题,但是还是有最大化操作,高估问题还是很严重,而Double DQN可以更好地缓解高估问题(但也没有彻底根除高估问题)。
Double DQN做的改进其实很简单:
我们用原始网络 Q ( s , a ; w ) Q(s,a; w) Q(s,a;w),选出使Q值最大化的那个动作,记为 a ∗ {\color{Red}a^*} a∗,再用目标网络使用这个 a ∗ {\color{Red}a^*} a∗计算目标值:
y t = r t + γ ⋅ Q ( s t + 1 , a ∗ ; w − ) y_t = r_t + \gamma \cdot Q(s_{t+1},{\color{Red}a^*};w^-) yt=rt+γ⋅Q(st+1,a∗;w−),
由于:
Q ( s t + 1 , a ∗ ; w − ) ≤ max a Q ( s t + 1 , a ; w − ) Q(s_{t+1},{\color{Red}a^*};w^-) \leq \max_{\color{Red}a}Q(s_{t+1},{\color{Red}a};w^-) Q(st+1,a∗;w−)≤maxaQ(st+1,a;w−)
所以进一步减缓了最大化带来的高估问题。
 图源于:Shusen Wang深度强化学习课程
图源于:Shusen Wang深度强化学习课程
六、总结
伪代码:

整体来说,深度Q网络与Q学习的目标价值以及价值的更新方式都非常相似。主要的不同在于:深度Q网络将Q学习与深度学习结合,用深度网络来近似动作价值函数,而Q学习则是采用表格存储;深度Q网络采用经验回放的训练方式,从历史数据中随机采样,而Q学习直接采用下一个状态的数据进行学习。
参考:
[1] https://www.bilibili.com/video/BV1rv41167yx?p=10&vd_source=a433a250e74c87c3235dea6a203f8a29
[2] 王琦.强化学习教程[M]
[3] https://zhuanlan.zhihu.com/p/110620815
文章图源于:百度飞桨AlStudio、Shusen Wang深度强化学习课程等*