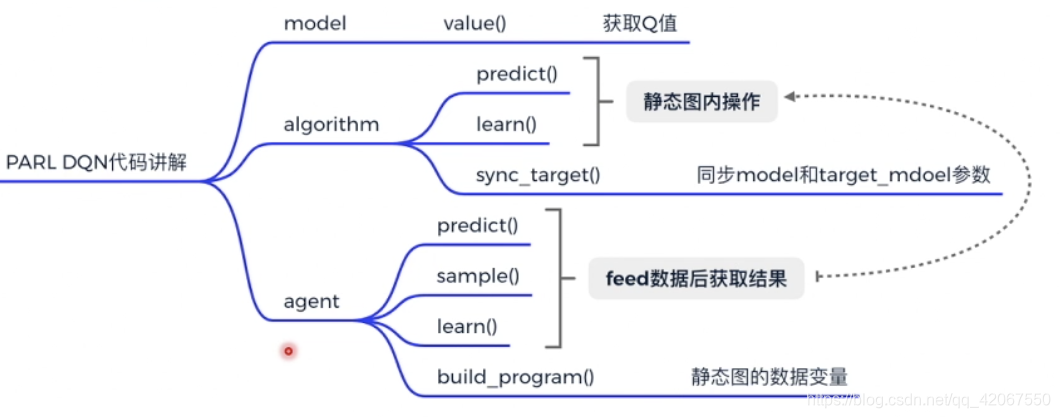
本文内容源自百度强化学习 7 日入门课程学习整理
感谢百度 PARL 团队李科浇老师的课程讲解
强化学习算法 DQN 解决 CartPole 问题,移动小车使得车上的摆杆保持直立。
-
这个游戏环境可以说是强化学习中的 “Hello World”
-
大部分的算法都可以先利用这个环境来测试下是否可以收敛
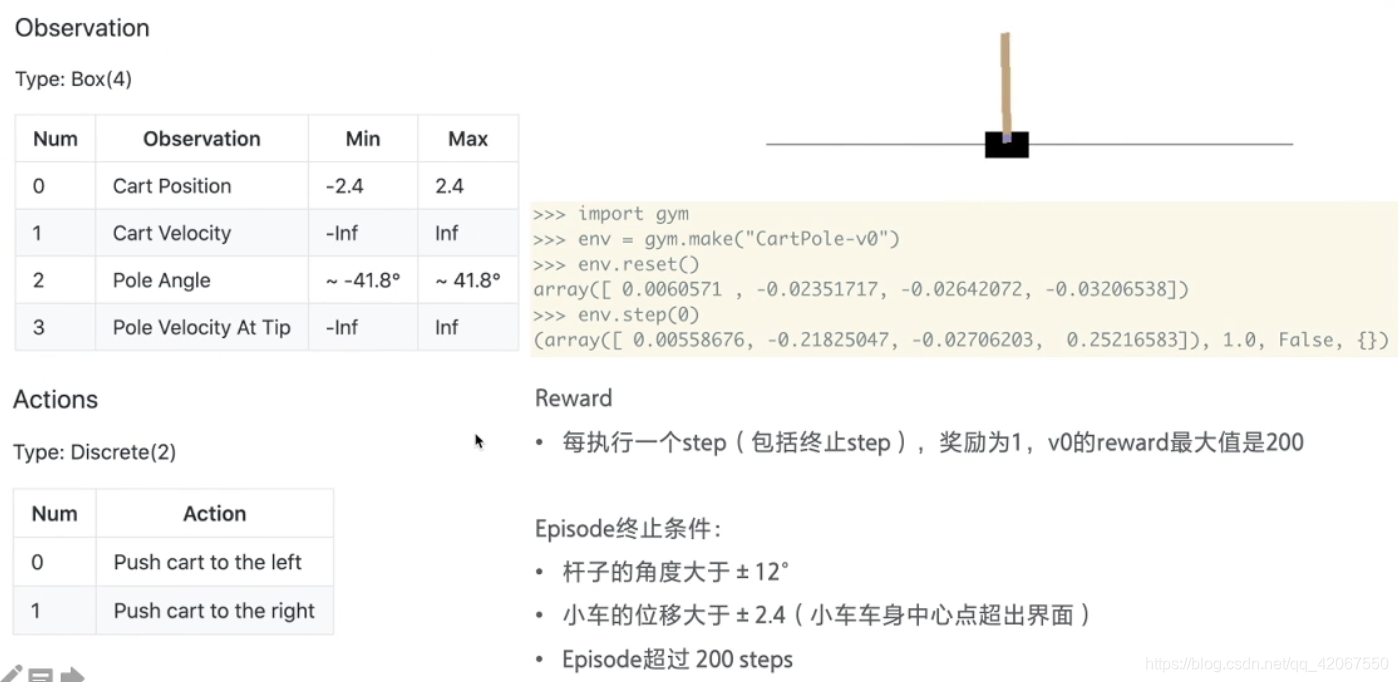
环境介绍:
小车在一个导轨上,无摩擦地来回移动,车上有一根杆子,可以绕着小车上的一个点旋转,所以我们要做的是,通过推动小车往左或者往右,来确保杆子不倒
终止条件:
- 杆子角度大于 +/-12度
- 车子位移大于 +/-2.4(车子移出了界面外)
- Episode 超出 200 steps
奖励:
- 每执行一个 step 拿到 1分
- 所以最高是 200 分
环境重置 env.reset()
- 返回状态值:[小车的位置,小车的速度,杆子的角度,杆子顶端的速度]
每走一步 env.step(0)
- 返回:[当前状态,奖励,是否结束]
文章目录
一、安装依赖
pip install gym
pip install paddlepaddle==1.6.3
pip install parl==1.3.1
二、导入依赖
import parl
from parl import layers
# parl 封装了 paddle.fluid.layers 的 API,官网可查询使用方式
import paddle.fluid as fluid
import copy
import numpy as np
import os
import gym
from parl.utils import logger
三、设置超参数
LEARN_FREQ = 5 # 训练频率,不需要每一个step都learn,攒一些新增经验后再learn,提高效率
MEMORY_SIZE = 20000 # replay memory的大小,越大越占用内存
MEMORY_WARMUP_SIZE = 200 # replay_memory 里需要预存一些经验数据,再开启训练
BATCH_SIZE = 32 # 每次给agent learn的数据数量,从replay memory随机里sample一批数据出来
LEARNING_RATE = 0.001 # 学习率
GAMMA = 0.99 # reward 的衰减因子,一般取 0.9 到 0.999 不等
四、Model
Model用来定义前向(Forward)网络,用户可以自由的定制自己的网络结构。
class Model(parl.Model):
# 这里的 model 利用 parl.Model 作为基类,后面会用到一些基类下的方法
def __init__(self, act_dim):
hid1_size = 128
hid2_size = 128
# 3层全连接网络
self.fc1 = layers.fc(size=hid1_size, act='relu')
self.fc2 = layers.fc(size=hid2_size, act='relu')
self.fc3 = layers.fc(size=act_dim, act=None)
def value(self, obs):
# 定义网络
# 输入state,输出所有action对应的Q,[Q(s,a1), Q(s,a2), Q(s,a3)...]
h1 = self.fc1(obs)
h2 = self.fc2(h1)
Q = self.fc3(h2)
return Q # 输出的 Q 是一个向量,维度是动作的维度
五、Algorithm
Algorithm 定义了具体的算法来更新前向网络(Model),也就是通过定义损失函数来更新Model,和算法相关的计算都放在algorithm中。

这里的核心是 learn() 函数,其中分为 3 部分:
- 获取 Q 目标值
- 注意点:在 target_Q 的计算中,有个判断条件,是否游戏结束,计算公式不同
- terminal:即是否为 done,是的话为 true(1),否的话为 false(0)
- 所以用
作为系数就可以达到 “判断” 语句的效果(之前要先用 layers.cast 将 terminal 转化为浮点数)
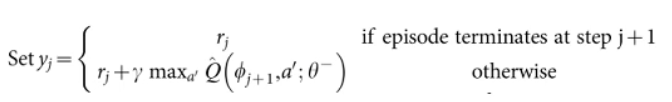
- 注意点:best_v.stop_gradient = True 阻止梯度传递
- 我们在通过 神经网络获得 target_Q 的时候,并不希望去更新 target_model 神经网络参数,所以要阻止梯度传递
- 注意点:在 target_Q 的计算中,有个判断条件,是否游戏结束,计算公式不同
- 获取 Q 预测值
- 注意点:从 Q 值列表中取得对应 动作的 Q 值
- 首先把 action 转为 one-hot 向量
- 然后用两个向量元素相乘的方法 layers.elementwise_mul 只保留对应的值,其他变为 0
- 然后用元素累加的方法 layers.reduce_sum 就得到了最终的值 (这里是 “第 2 维” 的累加,所以 dim=1)
- 注意点:从 Q 值列表中取得对应 动作的 Q 值
- 计算 loss
这里 learn() 函数的输入 obs, action, reward, next_obs, terminal
由于每次传入一个 batch ,所以每一个参数都是一个数组
# from parl.algorithms import DQN # 也可以直接从parl库中导入DQN算法
class DQN(parl.Algorithm):
def __init__(self, model, act_dim=None, gamma=None, lr=None):
""" DQN algorithm
Args:
model (parl.Model): 定义Q函数的前向网络结构
act_dim (int): action空间的维度,即有几个action
gamma (float): reward的衰减因子
lr (float): learning rate 学习率.
"""
self.model = model # 传入之前定义好的 model 结构
self.target_model = copy.deepcopy(model) # 把模型硬拷贝一份,作为 target_model(固定)
assert isinstance(act_dim, int) # 断言,确认动作维度,是 int
assert isinstance(gamma, float) # 断言,确认衰减因子,是 float
assert isinstance(lr, float) # 断言,确定学习速率,是 float
self.act_dim = act_dim #传入
self.gamma = gamma #传入
self.lr = lr #传入
def predict(self, obs):
""" 使用self.model的value网络来获取 [Q(s,a1),Q(s,a2),...]
"""
return self.model.value(obs) # 把 obs 传入前向网络,得到当前状态下,所有可执行动作的 Q 值(预测值)
def learn(self, obs, action, reward, next_obs, terminal):
""" 使用DQN算法更新self.model的value网络
"""
# 1. 从target_model中获取 max Q' 的值,用于计算target_Q(目标值)
next_pred_value = self.target_model.value(next_obs)
# 获得下一步状态下,所以可执行动作的 Q 值
best_v = layers.reduce_max(next_pred_value, dim=1)
# 求最大 Q 值
best_v.stop_gradient = True # 阻止梯度传递
terminal = layers.cast(terminal, dtype='float32')
# 把 terminal 转化为 float32 类型
target = reward + (1.0 - terminal) * self.gamma * best_v
#
# 2. 获取 Q (预测值)
pred_value = self.model.value(obs) # 正向传播,即获得了该状态下,所有动作对应的 Q 值
# 将action转onehot向量,比如:3 => [0,0,0,1,0]
action_onehot = layers.one_hot(action, self.act_dim)
# 输入的动作值,比如 4,根据 depth 即动作维度,转化为对应的 one-hot
action_onehot = layers.cast(action_onehot, dtype='float32')
# 设定 one-hot 中的值为 float32 类型
# 下面一行是逐元素相乘,拿到action对应的 Q(s,a)
# 比如:pred_value = [[2.3, 5.7, 1.2, 3.9, 1.4]], action_onehot = [[0,0,0,1,0]]
# ==> pred_action_value = [[3.9]]
pred_action_value = layers.reduce_sum(
layers.elementwise_mul(action_onehot, pred_value), dim=1)
# 当前状态下,执行该 action 得到的 Q 值(预测值)
# 3. 计算 Q(s,a) 与 target_Q的均方差,得到loss
cost = layers.square_error_cost(pred_action_value, target)
# 损失函数为旧的 Q 和 目标 Q 之间的差别(均方差)
cost = layers.reduce_mean(cost)
# 均值
optimizer = fluid.optimizer.Adam(learning_rate=self.lr) # 使用Adam优化器
optimizer.minimize(cost) # 目标是最小化损失函数
return cost
def sync_target(self):
""" 把 self.model 的模型参数值同步到 self.target_model
"""
self.model.sync_weights_to(self.target_model)
# 这是 parl.Model 这个基类下的方法,用于定时为target_model做参数同步
六、Agent
Agent 负责算法与环境的交互,在交互过程中把生成的数据提供给Algorithm来更新模型(Model),数据的预处理流程也一般定义在这里。
-
这里 learn() 函数的输入也是从经验池中拿到的一个 batch 的数据,然后进行对应的变量赋值
-
变量的定义是在 build_program() 中(计算图)完成,包括变量的 类型 dtype,结构 shape,名字 name
-
然后每执行一次 learn() 就是把数据通过 feed 传入 program,然后获取 fetch_list 中的 self.cost
-
每一次执行 run 就是完成了一次网络的更新
-
-
这里还有一个计算图 pred_program 用于获取最大的 Q 值(预测值)下的 action
- 首先通过 predict() 函数,调用 alg 中的 predict() 计算最大的 Q 值
- 然后获取对应的 action,仅需使用 np.argmax 函数
- 然后通过 sample() 函数决定是利用还是探索,选择具体执行的动作
class Agent(parl.Agent):
# 继承了 parl.Agent 这个基类
# 其实基类下只有一个 save 和 restore 方法
# 其他的方法:build_program,learn,predict,sample 都是空的
def __init__(self,
algorithm, # 算法
obs_dim, # 状态的维度
act_dim, # 动作的维度
e_greed=0.1, # 10% 的随机探索概率
e_greed_decrement=0): # 概率递减为 0
assert isinstance(obs_dim, int) # 断言,状态维度,为 int
assert isinstance(act_dim, int) # 断言,动作维度,为 int
self.obs_dim = obs_dim # 初始化赋值
self.act_dim = act_dim # 初始化赋值
super(Agent, self).__init__(algorithm)
#
self.global_step = 0 #
self.update_target_steps = 200 # 每隔200个training steps再把model的参数复制到target_model中
self.e_greed = e_greed # 有一定概率随机选取动作,探索
self.e_greed_decrement = e_greed_decrement # 随着训练逐步收敛,探索的程度慢慢降低
def build_program(self):
self.pred_program = fluid.Program() # 初始化一个 paddle.fluid 框架下的程序
self.learn_program = fluid.Program() # 初始化一个 paddle.fluid 框架下的程序
with fluid.program_guard(self.pred_program): # 搭建计算图用于 预测动作,定义输入输出变量
# 把下面的语句添加到 self.pred_program 程序中
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
# 将 obs 设定为数据变量
self.value = self.alg.predict(obs)
#
with fluid.program_guard(self.learn_program): # 搭建计算图用于 更新Q网络,定义输入输出变量
# 把下面的语句添加到 self.learn_program 程序中
obs = layers.data(
name='obs', shape=[self.obs_dim], dtype='float32')
# 将 obs 设定为数据变量
action = layers.data(name='act', shape=[1], dtype='int32')
# 将 action 设定为数据变量
reward = layers.data(name='reward', shape=[], dtype='float32')
# 将 reward 设定为数据变量
next_obs = layers.data(
name='next_obs', shape=[self.obs_dim], dtype='float32')
# 将 next_obs 设定为数据变量
terminal = layers.data(name='terminal', shape=[], dtype='bool')
# 将 terminal 设定为数据变量
self.cost = self.alg.learn(obs, action, reward, next_obs, terminal)
#
def sample(self, obs): # 采样动作
sample = np.random.rand() # 产生0~1之间的小数
if sample < self.e_greed: # 小于 0.1,即 10% 的概率
act = np.random.randint(self.act_dim) # 探索:每个动作都有概率被选择
else:
act = self.predict(obs) # 选择最优动作
self.e_greed = max(
0.01, self.e_greed - self.e_greed_decrement) # 随着训练逐步收敛,探索的程度慢慢降低
return act
def predict(self, obs): # 选择最优动作
obs = np.expand_dims(obs, axis=0) # 将数字转化为一维向量
pred_Q = self.fluid_executor.run(
self.pred_program,
feed={'obs': obs.astype('float32')},
fetch_list=[self.value])[0]
# 执行定义好的程序,获取 obs 状态下的,所有动作的 Q 值
pred_Q = np.squeeze(pred_Q, axis=0)
# 压缩一个维度
act = np.argmax(pred_Q) # 选择Q最大的下标,即对应的动作
return act
def learn(self, obs, act, reward, next_obs, terminal):
# 每隔200个training steps同步一次model和target_model的参数
if self.global_step % self.update_target_steps == 0:
self.alg.sync_target()
#
self.global_step += 1
# 步数+1
act = np.expand_dims(act, -1) # 将数字转化为一维向量
feed = {
'obs': obs.astype('float32'),
'act': act.astype('int32'),
'reward': reward,
'next_obs': next_obs.astype('float32'),
'terminal': terminal
}
# 定义所有传入的数据
cost = self.fluid_executor.run(
self.learn_program, feed=feed, fetch_list=[self.cost])[0] # 训练一次网络
return cost
七、ReplayMemory
经验池:用于存储多条经验,实现 经验回放。
import random
import collections
import numpy as np
class ReplayMemory(object):
def __init__(self, max_size):
self.buffer = collections.deque(maxlen=max_size)
# 初始化一个双向列表,长度为 max_size
# 增加一条经验到经验池中
def append(self, exp):
self.buffer.append(exp)
# 在列表尾部增加一条经验
# 从经验池中选取N条经验出来
def sample(self, batch_size):
mini_batch = random.sample(self.buffer, batch_size)
# 从缓存列表中,随机去除 batch_size 条经验
obs_batch, action_batch, reward_batch, next_obs_batch, done_batch = [], [], [], [], []
# 初始化列表
for experience in mini_batch:
s, a, r, s_p, done = experience # 从 mini_batch 中去取得对应元素
# 加入各自的列表中
obs_batch.append(s)
action_batch.append(a)
reward_batch.append(r)
next_obs_batch.append(s_p)
done_batch.append(done)
# 转化为 numpy 的数组进行返回
return np.array(obs_batch).astype('float32'), \
np.array(action_batch).astype('float32'), np.array(reward_batch).astype('float32'),\
np.array(next_obs_batch).astype('float32'), np.array(done_batch).astype('float32')
def __len__(self):
return len(self.buffer) # 设定一个参数 len 是缓存的长度
八、Training && Test(训练&&测试)
训练的时候,需要先填满经验池才开始
- 采用 sample 方式,有探索概率
评估的时候,这里设定为 5 个 episode 求平均分
- 这是因为强化学习有一定不确定性
- 环境也有随机选
- 所以哪怕是一个训练好的 agent,单次的 episode 的分数也可能特别差/特别好
- 所以多跑几组求平均这样的评估比较客观
# 训练一个episode
def run_episode(env, agent, rpm):
total_reward = 0 # 累计奖励初始化
obs = env.reset() # 初始化一个环境,返回值是初始状态 obs
step = 0 # 初始化步数
while True:
step += 1
action = agent.sample(obs) # 采样动作,所有动作都有概率被尝试到
next_obs, reward, done, _ = env.step(action)
rpm.append((obs, action, reward, next_obs, done))
# train model
if (len(rpm) > MEMORY_WARMUP_SIZE) and (step % LEARN_FREQ == 0):
(batch_obs, batch_action, batch_reward, batch_next_obs,
batch_done) = rpm.sample(BATCH_SIZE)
train_loss = agent.learn(batch_obs, batch_action, batch_reward,
batch_next_obs,
batch_done) # s,a,r,s',done
total_reward += reward
obs = next_obs
if done:
break
return total_reward
# 评估 agent, 跑 5 个episode,总reward求平均
def evaluate(env, agent, render=False):
eval_reward = []
for i in range(5):
obs = env.reset()
episode_reward = 0
while True:
action = agent.predict(obs) # 预测动作,只选最优动作
obs, reward, done, _ = env.step(action)
episode_reward += reward
if render:
env.render()
if done:
break
eval_reward.append(episode_reward)
return np.mean(eval_reward)
九、创建环境和Agent,创建经验池,启动训练,保存模型
env = gym.make('CartPole-v0') # CartPole-v0: 预期最后一次评估总分 > 180(最大值是200)
action_dim = env.action_space.n # CartPole-v0: 2
obs_shape = env.observation_space.shape # CartPole-v0: (4,)
rpm = ReplayMemory(MEMORY_SIZE) # DQN的经验回放池实例化
# 根据parl框架构建agent
model = Model(act_dim=action_dim) # 模型实例化
algorithm = DQN(model, act_dim=action_dim, gamma=GAMMA, lr=LEARNING_RATE) # 算法实例化(传入模型)
# agent 实例化(传入算法)
agent = Agent(
algorithm,
obs_dim=obs_shape[0],
act_dim=action_dim,
e_greed=0.1, # 有一定概率随机选取动作,探索
e_greed_decrement=1e-6) # 随着训练逐步收敛,探索的程度慢慢降低
# 加载模型
# save_path = './dqn_model.ckpt'
# agent.restore(save_path)
# 先往经验池里存一些数据,避免最开始训练的时候样本丰富度不够
while len(rpm) < MEMORY_WARMUP_SIZE: # 当经验池不满的时候(这里小于 200 条)
run_episode(env, agent, rpm) # 持续添加到经验池(没有开始进行训练)
max_episode = 2000
# 开始训练
episode = 0
while episode < max_episode: # 训练max_episode个回合,test部分不计算入episode数量
# train part
for i in range(0, 50):
total_reward = run_episode(env, agent, rpm)
episode += 1
# test part
eval_reward = evaluate(env, agent, render=False) # render=True 查看显示效果
logger.info('episode:{} e_greed:{} test_reward:{}'.format(
episode, agent.e_greed, eval_reward))
# 训练结束,保存模型
save_path = './dqn_model.ckpt'
agent.save(save_path)
十、总结