版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Lin_wj1995/article/details/82769361
在看本文之前建议先看一下二叉树的删除过程,这里有一篇文章写得不错,可以看一下
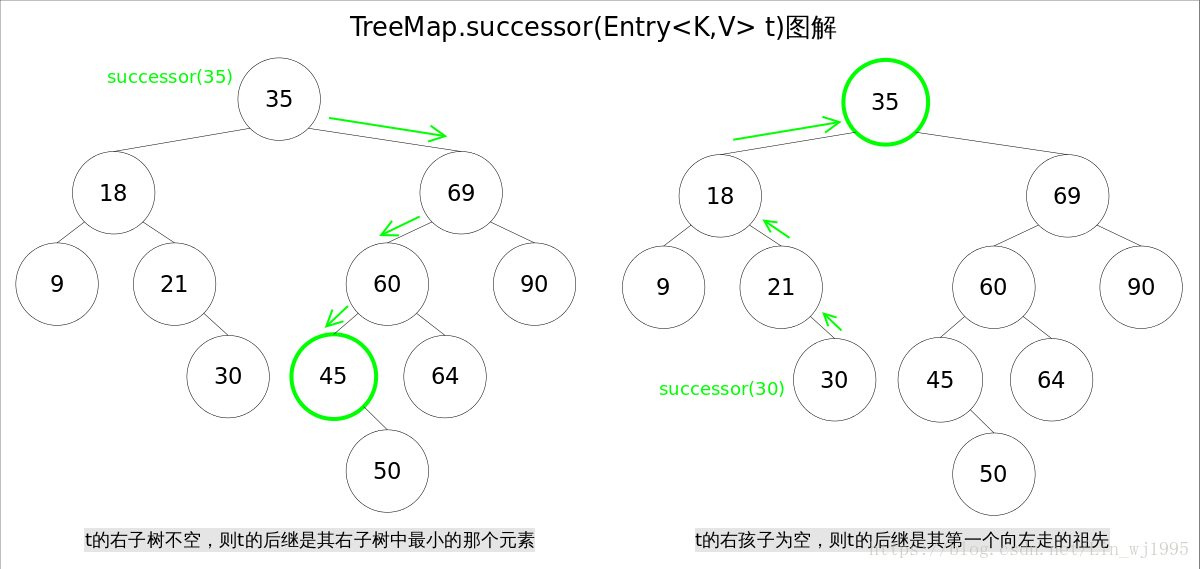
1、后继节点
在看源码之前,先说说红黑树寻找 待删除节点t 的 后继节点 的过程:
- 如果待删除节点t有右节点,那么后继节点为该节点右子树中最左的节点,也就是右子树中值最小的节点
- 如果待删除节点t无右节点,那么后继节点是向上遍历过程中 第一个向左拐的父节点
图解过程如下:
注:图片来源
该过程对应的TreeMap的源码如下:
/**
* Returns the successor of the specified Entry, or null if no such.
* 源码很好理解就不加注释了
*/
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) {
if (t == null)
return null;
else if (t.right != null) {
Entry<K,V> p = t.right;
while (p.left != null)
p = p.left;
return p;
} else {
Entry<K,V> p = t.parent;
Entry<K,V> ch = t;
while (p != null && ch == p.right) {
ch = p;
p = p.parent;
}
return p;
}
}
2、删除过程
写一个简单的单元测试方法:
@Test
public void remove(){
TreeMap<String, String> map = new TreeMap();
map.put("aa","aa");
map.remove("aa");
}
进入remove方法:
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
点击进入deleteEntry(核心操作)方法:
/**
* 删掉p节点,然后对TreeMap进行rebalance
* 英文的注释都是官方的注释
*/
private void deleteEntry(Entry<K,V> p) {
modCount++; //记录修改次数
size--; //size减1
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {//如果待删除的节点p左右节点都有
Entry<K,V> s = successor(p);//得到p的后继节点,注意,根据前面我们对后继节点的了解后知道,
//该操作得到的肯定是p的右子树的最左节点!
p.key = s.key; //这里对key、value的设置看似很普通,其实很关键。该操作实际上已经把p节点删除掉了,但是注意颜色没有改变
p.value = s.value;
p = s; //然后把后继节点的指针赋值给p,注意,这时修改p的指针是没有问题的,因为经过上面的操作已经把节点删掉了
} // p has 2 children
//下面的p节点要不就只有左节点、要不就只有右节点、要不就没有子节点
//因为有左右节点的p经过上面的操作后已经指向了后继节点,这里的后继节点一定是没有左节点的
//如果p有经过上面操作,那么实际上已经把需要删除的节点已经删除了,而且经过操作后需要删除的节点上的key、value已经变成了后继节点的key、value。
//操作后的p已经指向了后继节点,也就是说现在的p引用的node跟需要删除的node的key和value是一样的。所以该p指向的node也是要删除的,
//经过上面的方法就把删除过程转换成下面统一的操作
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK) //只有node为黑色时tree才需要fix
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK) //只有node为黑色时tree才需要fix
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
最后就是fixAfterDeletion方法了,这个方法总结起来就是如下操作:
针对的节点:当前节点x、父节点p、兄弟节点sib、兄弟节点的左子节点ch_l、兄弟节点的右子节点ch_r,如果满足一定情况就进行左旋或者右旋、改色,最后fix完成。
3、讨论
在文章最后来说一下我学习红黑树之前的疑惑:为什么已经有了二叉树和平衡二叉树,还需要红黑树?红黑树有什么优点?
我的个人看法是:
普通二叉树插入很快,但是如果树节点很多,那么就很容易造成树的“倾斜”,就是树的左节点很深,而右节点很浅。这样查找节点时跟链表查找的时间复杂度就差别不大。也就是说普通二叉树适合对于插入性能要求很高而基本不怎么查询的场景。
平衡二叉树则有点跟普通二叉树相反,它可以时时刻刻保持左右子树的平衡,这样对于查找就很友好。但是对于插入操作就不是很友好,每次插入很大概率会触发树的rebalance,影响插入性能(当然,这个性能是相对的,对于指针的修改操作是很快的)。
于是乎红黑树出现了,一种兼顾于插入和查找的树,插入时不会为了时时刻刻保持平衡而进行rebalance,也不会让左右子树的高度差非常大~
如果有更好的想法,可以交流讨论哈~~