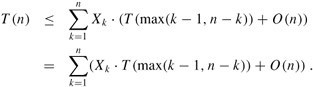分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
程序员编程艺术:第三章、寻找最小的k个数
作者:July。
时间:二零一一年四月二十八日。
致谢:litaoye, strugglever,yansha,luuillu,Sorehead,及狂想曲创作组。
微博:http://weibo.com/julyweibo。
出处:http://blog.csdn.net/v_JULY_v。
----------------------------------
前奏
@July_____:1、当年明月:“我写文章有个习惯,由于早年读了太多学究书,所以很痛恨那些故作高深的文章,其实历史本身很精彩,所有的历史都可以写得很好看,...。”2、IT技术文章,亦是如此,可以写得很通俗,很有趣,而非故作高深。希望,我可以做到。
下面,我试图用最清晰易懂,最易令人理解的思维或方式阐述有关寻找最小的k个数这个问题(这几天一直在想,除了计数排序外,这题到底还有没有其它的O(n)的算法? )。希望,有任何问题,欢迎不吝指正。谢谢。
寻找最小的k个数
题目描述:5.查找最小的k个元素
题目:输入n个整数,输出其中最小的k个。
例如输入1,2,3,4,5,6,7和8这8个数字,则最小的4个数字为1,2,3和4。
第一节、各种思路,各种选择

-
0、 咱们先简单的理解,要求一个序列中最小的k个数,按照惯有的思维方式,很简单,先对这个序列从小到大排序,然后输出前面的最小的k个数即可。
-
1、 至于选取什么的排序方法,我想你可能会第一时间想到快速排序,我们知道,快速排序平均所费时间为n*logn,然后再遍历序列中前k个元素输出,即可,总的时间复杂度为O(n*logn+k)= O(n*logn)。
-
2、 咱们再进一步想想,题目并没有要求要查找的k个数,甚至后n-k个数是有序的,既然如此,咱们又何必对所有的n个数都进行排序列?
这时,咱们想到了用选择或交换排序,即遍历n个数,先把最先遍历到得k个数存入大小为k的数组之中,对这k个数,利用选择或交换排序,找到k个数中的最大数kmax(kmax设为k个元素的数组中最大元素),用时O(k)(你应该知道,插入或选择排序查找操作需要O(k)的时间),后再继续遍历后n-k个数,x与kmax比较:如果x<kmax,则x代替kmax,并再次重新找出k个元素的数组中最大元素kmax‘( 多谢kk791159796 提醒修正);如果x>kmax,则不更新数组。这样,每次更新或不更新数组的所用的时间为O(k)或O(0),整趟下来,总的时间复杂度平均下来为:n*O(k)= O(n*k)。 -
3、 当然,更好的办法是维护k个元素的最大堆,原理与上述第2个方案一致,即用容量为k的最大堆存储最先遍历到的k个数,并假设它们即是最小的k个数,建堆费时O(k)后,有k1<k2<...<kmax(kmax设为大顶堆中最大元素)。继续遍历数列,每次遍历一个元素x,与堆顶元素比较,x<kmax,更新堆(用时logk),否则不更新堆。这样下来,总费时O(k+(n-k)*logk)= O(n*logk)。此方法得益于在堆中,查找等各项操作时间复杂度均为logk(不然,就如上述思路2所述:直接用数组也可以找出前k个小的元素,用时O(n*k))。
-
4、 按编程之美第141页上解法二的所述,类似快速排序的划分方法,N个数存储在数组S中,再从数组中随机选取一个数X( 随机选取枢纽元,可做到线性期望时间O(N)的复杂度,在第二节论述),把数组划分为Sa和Sb俩部分,Sa<=X<=Sb,如果要查找的k个元素小于Sa的元素个数,则返回Sa中较小的k个元素,否则返回Sa中 所有元素+Sb中小的k-|Sa|个元素。 像上述过程一样,这个运用类似快速排序的partition的快速选择SELECT算法寻找最小的k个元素,在最坏情况下亦能做到O(N)的复杂度。不过值得一提的是,这个快速选择SELECT算法是选取数组中“中位数的中位数”作为枢纽元,而非随机选取枢纽元。
-
5、 RANDOMIZED-SELECT,每次都是 随机选取数列中的一个元素作为主元,在0(n)的时间内找到第k小的元素,然后遍历输出前面的k个小的元素。 如果能的话,那么总的时间复杂度为线性期望时间:O(n+k)= O(n)(当k比较小时)。
Ok,稍后第二节中,我会具体给出RANDOMIZED-SELECT(A, p, r, i)的整体完整伪码。在此之前,要明确一个问题:我们通常所熟知的快速排序是以固定的第一个或最后一个元素作为主元,每次递归划分都是不均等的,最后的平均时间复杂度为:O(n*logn),但RANDOMIZED-SELECT与普通的快速排序不同的是,每次递归都是随机选择序列从第一个到最后一个元素中任一一个作为主元。
-
6、 线性时间的排序,即计数排序,时间复杂度虽能达到 O(n),但限制条件太多,不常用。
-
7、 updated: huaye502在本文的评论下指出:“可以用最小堆初始化数组,然后取这个优先队列前k个值。复杂度O(n)+k*O(log n)”。huaye502的意思是针对整个数组序列建最小堆,建堆所用时间为O(n)(算法导论一书上第6章第6.3节已经论证,在线性时间内,能将一个无序的数组建成一个最小堆),然后取堆中的前k个数,总的时间复杂度即为: O(n+k*logn)。
关于上述第7点思路的继续阐述:至于思路7的O(n+k*logn)是否小于上述思路3的O(n*logk),即O(n+k*logn)?< O(n*logk)。粗略数学证明可参看如下第一幅图,我们可以这么解决:当k是常数,n趋向于无穷大时,求(n*logk)/(n+k*logn)的极限T,如果T>1,那么可得O(n*logk)>O(n+k*logn),也就是O(n+k*logn)< O(n*logk)。虽然这有违我们惯常的思维,然事实最终证明的确如此,这个极值T=logk>1,即采取建立n个元素的最小堆后取其前k个数的方法的复杂度小于采取常规的建立k个元素最大堆后通过比较寻找最小的k个数的方法的复杂度。但,最重要的是,如果建立n个元素的最小堆的话,那么其空间复杂度势必为O(N),而建立k个元素的最大堆的空间复杂度为O(k)。所以,综合考虑,我们一般还是选择用建立k个元素的最大堆的方法解决此类寻找最小的k个数的问题。
思路3准确的时间复杂度表述为:O(k+(n-k)*logk),思路7准确的时间复杂度表述为:O(n+k*logn),也就是如gbb21所述粗略证明:
要证原式k+n*logk-n-k*logn>0,等价于证(logk-1)n-k*logn+k>,要证思路3的时间复杂度大于思路7的时间复杂度,等价于要证原式k+n*logk-klogk-n-k*logn>0,即证(logk-1)n - k*logn + k - klogk > 0。当when n -> +/inf(n趋向于正无穷大)时,logk-1-0-0>0,即只要满足logk-1>0即可。原式得证。即O(k+n*logk)>O(n+k*logn) =>O(n+k*logn)< O(n*logk),与上面得到的结论一致。事实上,是建立最大堆还是建立最小堆,其实际的程序运行时间相差并不大,运行时间都在一个数量级上。因为后续,我们还专门写了个程序进行测试,即针对1000w的数据寻找其中最小的k个数的问题,采取两种实现,一是采取常规的建立k个元素最大堆后通过比较寻找最小的k个数的方案,一是采取建立n个元素的最小堆,然后取其前k个数的方法,发现两相比较,运行时间实际上相差无几。结果可看下面的第二幅图。

-
8、 @lingyun310:与上述思路7类似,不同的是在对元素数组原地建最小堆O(n)后,然后提取K次, 但是每次提取时,换到顶部的元素只需要下移顶多k次就足够了,下移次数逐次减少( 而上述思路7每次提取都需要logn,所以提取k次,思路7需要k*logn。而本思路8只需要K^2)。此种方法的复杂度为O(n+k^2)。@July:对于这个O(n+k^2)的复杂度,我相当怀疑。因为据我所知,n个元素的堆,堆中任何一项操作的复杂度皆为logn,所以按理说,lingyun310方法的复杂度应该跟下述思路8一样,也为O(n+k*logn),而非O(n+k*k)。ok,先放到这,待时间考证 。06.02。
updated:
经过和几个朋友的讨论,已经证实,上述思路7lingyun310所述的思路应该是完全可以的。下面,我来具体解释下他的这种方法。
我们知道,n个元素的最小堆中,可以先取出堆顶元素得到我们第1小的元素,然后把堆中最后一个元素(较大的元素)上移至堆顶,成为新的堆顶元素(取出堆顶元素之后,把堆中下面的最后一个元素送到堆顶的过程可以参考下面的第一幅图。至于为什么是怎么做,为什么是把最后一个元素送到堆顶成为堆顶元素,而不是把原来堆顶元素的儿子送到堆顶呢?具体原因可参考相关书籍)。
此时,堆的性质已经被破坏了,所以此后要调整堆。怎么调整呢?就是一般人所说的针对新的堆顶元素shiftdown,逐步下移(因为新的堆顶元素由最后一个元素而来,比较大嘛,既然是最小堆,当然大的元素就要下沉到堆的下部了)。下沉多少步呢?即如lingyun310所说的,下沉k次就足够了。
下移k次之后,此时的堆顶元素已经是我们要找的第2小的元素。然后,取出这个第2小的元素(堆顶元素),再次把堆中的最后一个元素送到堆顶,又经过k-1次下移之后(此后下移次数逐步减少,k-2,k-3,...k=0后算法中断)....,如此重复k-1趟操作,不断取出的堆顶元素即是我们要找的最小的k个数。虽然上述算法中断后整个堆已经不是最小堆了,但是求得的k个最小元素已经满足我们题目所要求的了,就是说已经找到了最小的k个数,那么其它的咱们不管了。
我可以再举一个形象易懂的例子。你可以想象在一个水桶中,有很多的气泡,这些气泡从上到下,总体的趋势是逐渐增大的,但却不是严格的逐次大(正好这也符合最小堆的性质)。ok,现在我们取出第一个气泡,那这个气泡一定是水桶中所有气泡中最小的,把它取出来,然后把最下面的那个大气泡(但不一定是最大的气泡)移到最上面去,此时违反了气泡从上到下总体上逐步变大的趋势,所以,要把这个大气泡往下沉,下沉到哪个位置呢?就是下沉k次。下沉k次后,最上面的气泡已经肯定是最小的气泡了,把他再次取出。然后又将最下面最后的那个气泡移至最上面,移到最上面后,再次让它逐次下沉,下沉k-1次...,如此循环往复,最终取到最小的k个气泡。
ok,所以,上面方法所述的过程,更进一步来说,其实是第一趟调整保持第0层到第k层是最小堆,第二趟调整保持第0层到第k-1层是最小堆...,依次类推。但这个思路只是下述思路8中正规的最小堆算法(因为它最终对全部元素都进行了调整,算法结束后,整个堆还是一个最小堆)的调优,时间复杂度O(n+k^2)没有量级的提高,空间复杂度为O(N)也不会减少。
原理理解透了,那么写代码,就不难了,完整粗略代码如下(有问题烦请批评指正):
- //copyright@ 泡泡鱼
- //July、2010.06.02。
- //@lingyun310:先对元素数组原地建最小堆,O(n)。然后提取K次,但是每次提取时,
- //换到顶部的元素只需要下移顶多k次就足够了,下移次数逐次减少。此种方法的复杂度为O(n+k^2)。
- #include <stdio.h>
- #include <stdlib.h>
- #define MAXLEN 123456
- #define K 100
- //
- void HeapAdjust(int array[], int i, int Length)
- {
- int child,temp;
- for(temp=array[i];2*i+1<Length;i=child)
- {
- child = 2*i+1;
- if(child<Length-1 && array[child+1]<array[child])
- child++;
- if (temp>array[child])
- array[i]=array[child];
- else
- break;
- array[child]=temp;
- }
- }
- void Swap(int* a,int* b)
- {
- *a=*a^*b;
- *b=*a^*b;
- *a=*a^*b;
- }
- int GetMin(int array[], int Length,int k)
- {
- int min=array[0];
- Swap(&array[0],&array[Length-1]);
- int child,temp;
- int i=0,j=k-1;
- for (temp=array[0]; j>0 && 2*i+1<Length; --j,i=child)
- {
- child = 2*i+1;
- if(child<Length-1 && array[child+1]<array[child])
- child++;
- if (temp>array[child])
- array[i]=array[child];
- else
- break;
- array[child]=temp;
- }
- return min;
- }
- void Kmin(int array[] , int Length , int k)
- {
- for(int i=Length/2-1;i>=0;--i)
- //初始建堆,时间复杂度为O(n)
- HeapAdjust(array,i,Length);
- int j=Length;
- for(i=k;i>0;--i,--j)
- //k次循环,每次循环的复杂度最多为k次交换,复杂度为o(k^2)
- {
- int min=GetMin(array,j,i);
- printf("%d,", min);
- }
- }
- int main()
- {
- int array[MAXLEN];
- for(int i=MAXLEN;i>0;--i)
- array[MAXLEN-i] = i;
- Kmin(array,MAXLEN,K);
- return 0;
- }
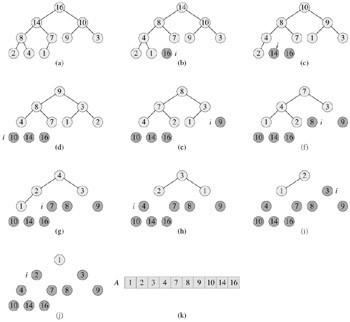
在算法导论第6章有下面这样一张图,因为开始时曾一直纠结过这个问题,“取出堆顶元素之后,把堆中下面的最后一个元素送到堆顶”。因为算法导论上下面这张图给了我一个假象,从a)->b)中,让我误以为是取出堆顶元素之后,是把原来堆顶元素的儿子送到堆顶。而事实上不是这样的。因为在下面的图中,16被删除后,堆中最后一个元素1代替16成为根结点,然后1下沉(注意下图所示的过程是最大堆的堆排序过程,不再是上面的最小堆了,所以小的元素当然要下移),14上移到堆顶。所以,图中小图图b)是已经在小图a)之和被调整过的最大堆了,只是调整了logn次,非上面所述的k次。
ok,接下来,咱们再着重分析下上述思路4。或许,你不会相信上述思路4的观点,但我马上将用事实来论证我的观点。这几天,我一直在想,也一直在找资料查找类似快速排序的partition过程的分治算法(即上述在编程之美上提到的第4点思路),是否能做到O(N)的论述或证明,
然找了三天,不但在算法导论上找到了RANDOMIZED-SELECT,在平均情况下为线性期望时间O(N)的论证(请参考本文第二节),还在mark allen weiss所著的数据结构与算法分析--c语言描述一书(还得多谢朋友sheguang提醒)中,第7章第7.7.6节(本文下面的第4节末,也有关此问题的阐述)也找到了在最坏情况下,为线性时间O(N)(是的,不含期望,是最坏情况下为O(N))的快速选择算法(此算法,本文文末,也有阐述),请看下述文字(括号里的中文解释为本人添加):
Quicksort can be modified to solve the selection problem, which we have seen in chapters 1 and 6. Recall that by using a priority queue, we can find the kth largest (or smallest) element in O(n + k log n)(即上述思路7). For the special case of finding the median, this gives an O(n log n) algorithm.
Since we can sort the file in O(nlog n) time, one might expect to obtain a better time bound for selection. The algorithm we present to find the kth smallest element in a set S is almost identical to quicksort. In fact, the first three steps are the same. We will call this algorithm quickselect(叫做快速选择). Let |Si| denote the number of elements in Si(令|Si|为Si中元素的个数). The steps of quickselect are(快速选择,即上述编程之美一书上的,思路4,步骤如下):
1. If |S| = 1, then k = 1 and return the elements in S as the answer. If a cutoff for small files is being used and |S| <=CUTOFF, then sort S and return the kth smallest element.
2. Pick a pivot element, v (- S.(选取一个枢纽元v属于S)
3. Partition S - {v} into S1 and S2, as was done with quicksort.
(将集合S-{v}分割成S1和S2,就像我们在快速排序中所作的那样)4. If k <= |S1|, then the kth smallest element must be in S1. In this case, return quickselect (S1, k). If k = 1 + |S1|, then the pivot is the kth smallest element and we can return it as the answer. Otherwise, the kth smallest element lies in S2, and it is the (k - |S1| - 1)st smallest element in S2. We make a recursive call and return quickselect (S2, k - |S1| - 1).
(如果k<=|S1|,那么第k个最小元素必然在S1中。在这种情况下,返回quickselect(S1,k)。如果k=1+|S1|,那么枢纽元素就是第k个最小元素,即找到,直接返回它。否则,这第k个最小元素就在S2中,即S2中的第(k-|S1|-1)(多谢王洋提醒修正)个最小元素,我们递归调用并返回quickselect(S2,k-|S1|-1))。In contrast to quicksort, quickselect makes only one recursive call instead of two. The worst case of quickselect is identical to that of quicksort and is O(n2). Intuitively, this is because quicksort's worst case is when one of S1 and S2 is empty; thus, quickselect(快速选择) is not really saving a recursive call. The average running time, however, is O(n)(不过,其平均运行时间为O(N)。看到了没,就是平均复杂度为O(N)这句话). The analysis is similar to quicksort's and is left as an exercise.
The implementation of quickselect is even simpler than the abstract description might imply. The code to do this shown in Figure 7.16. When the algorithm terminates, the kth smallest element is in position k. This destroys the original ordering; if this is not desirable, then a copy must be made.
并给出了代码示例:
- //copyright@ mark allen weiss
- //July、updated,2011.05.05凌晨.
- //q_select places the kth smallest element in a[k]
- void q_select( input_type a[], int k, int left, int right )
- {
- int i, j;
- input_type pivot;
- if( left + CUTOFF <= right )
- {
- pivot = median3( a, left, right );
- //取三数中值作为枢纽元,可以消除最坏情况而保证此算法是O(N)的。不过,这还只局限在理论意义上。
- //稍后,除了下文的第二节的随机选取枢纽元,在第四节末,您将看到另一种选取枢纽元的方法。
- i=left; j=right-1;
- for(;;)
- {
- while( a[++i] < pivot );
- while( a[--j] > pivot );
- if (i < j )
- swap( &a[i], &a[j] );
- else
- break;
- }
- swap( &a[i], &a[right-1] ); /* restore pivot */
- if( k < i)
- q_select( a, k, left, i-1 );
- else
- if( k > i )
- q-select( a, k, i+1, right );
- }
- else
- insert_sort(a, left, right );
- }
- 与快速排序相比,快速选择只做了一次递归调用而不是两次。快速选择的最坏情况和快速排序的相同,也是O(N^2),最坏情况发生在枢纽元的选取不当,以致S1,或S2中有一个序列为空。
- 这就好比快速排序的运行时间与划分是否对称有关,划分的好或对称,那么快速排序可达最佳的运行时间O(n*logn),划分的不好或不对称,则会有最坏的运行时间为O(N^2)。而枢纽元的选取则完全决定快速排序的partition过程是否划分对称。
- 快速选择也是一样,如果枢纽元的选取不当,则依然会有最坏的运行时间为O(N^2)的情况发生。那么,怎么避免这个最坏情况的发生,或者说就算是最坏情况下,亦能保证快速选择的运行时间为O(N)列?对了,关键,还是看你的枢纽元怎么选取。
- 像上述程序使用三数中值作为枢纽元的方法可以使得最坏情况发生的概率几乎可以忽略不计。然而,稍后,在本文第四节末,及本文文末,您将看到:通过一种更好的方法,如“五分化中项的中项”,或“中位数的中位数”等方法选取枢纽元,我们将能彻底保证在最坏情况下依然是线性O(N)的复杂度。
至于编程之美上所述:从数组中随机选取一个数X,把数组划分为Sa和Sb俩部分,那么这个问题就转到了下文第二节RANDOMIZED-SELECT,以线性期望时间做选择,无论如何,编程之美上的解法二的复杂度为O(n*logk)都是有待商榷的。至于最坏情况下一种全新的,为O(N)的快速选择算法,直接跳转到本文第四节末,或文末部分吧)。
不过,为了公正起见,把编程之美第141页上的源码贴出来,由大家来评判:
- Kbig(S, k):
- if(k <= 0):
- return [] // 返回空数组
- if(length S <= k):
- return S
- (Sa, Sb) = Partition(S)
- return Kbig(Sa, k).Append(Kbig(Sb, k – length Sa)
- Partition(S):
- Sa = [] // 初始化为空数组
- Sb = [] // 初始化为空数组
- Swap(s[1], S[Random()%length S]) // 随机选择一个数作为分组标准,以
- // 避免特殊数据下的算法退化,也可
- // 以通过对整个数据进行洗牌预处理
- // 实现这个目的
- p = S[1]
- for i in [2: length S]:
- S[i] > p ? Sa.Append(S[i]) : Sb.Append(S[i])
- // 将p加入较小的组,可以避免分组失败,也使分组
- // 更均匀,提高效率
- length Sa < length Sb ? Sa.Append(p) : Sb.Append(p)
- return (Sa, Sb)
你已经看到,它是随机选取数组中的任一元素为枢纽的,这就是本文下面的第二节RANDOMIZED-SELECT的问题了,只是要修正的是,此算法的平均时间复杂度为线性期望O(N)的时间。而,稍后在本文的第四节或本文文末,您还将会看到此问题的进一步阐述(SELECT算法,即快速选择算法),此SELECT算法能保证即使在最坏情况下,依然是线性O(N)的复杂度。
updated:
1、为了照顾手中没编程之美这本书的friends,我拍了张照片,现贴于下供参考(提醒:1、书上为寻找最大的k个数,而我们面对的问题是寻找最小的k个数,两种形式,一个本质(该修改的地方,上文已经全部修改)。2、书中描述与上文思路4并无原理性出入,不过,勿被图中记的笔记所误导,因为之前也曾被书中的这个n*logk复杂度所误导过。ok,相信,看完本文后,你不会再有此疑惑):
2、同时,在编程之美原书上此节的解法五的开头提到,“上面类似快速排序的方法平均时间复杂度是线性的”,我想上面的类似快速排序的方法,应该是指解法(即如上所述的类似快速排序partition过程的方法),但解法二得出的平均时间复杂度却为O(N*logk),明摆着前后矛盾(参见下图)。
3、此文创作后的几天,已把本人的意见反馈给邹欣等人,下面是编程之美bop1的改版修订地址的页面截图(本人也在参加其改版修订的工作),下面的文字是我的记录(同时,本人声明,此狂想曲系列文章系我个人独立创作,与其它的事不相干):



第二节、Randomized-Select,线性期望时间
下面是RANDOMIZED-SELECT(A, p, r)完整伪码(来自算法导论),我给了注释,或许能给你点启示。在下结论之前,我还需要很多的时间去思量,以确保结论之完整与正确。
PARTITION(A, p, r) //partition过程 p为第一个数,r为最后一个数
1 x ← A[r] //以最后一个元素作为主元
2 i ← p - 1
3 for j ← p to r - 1
4 do if A[j] ≤ x
5 then i ← i + 1
6 exchange A[i] <-> A[j]
7 exchange A[i + 1] <-> A[r]
8 return i + 1RANDOMIZED-PARTITION(A, p, r) //随机快排的partition过程
1 i ← RANDOM(p, r) //i 随机取p到r中个一个值
2 exchange A[r] <-> A[i] //以随机的 i作为主元
3 return PARTITION(A, p, r) //调用上述原来的partition过程RANDOMIZED-SELECT(A, p, r, i) //以线性时间做选择,目的是返回数组A[p..r]中的第i 小的元素
1 if p = r //p=r,序列中只有一个元素
2 then return A[p]
3 q ← RANDOMIZED-PARTITION(A, p, r) //随机选取的元素q作为主元
4 k ← q - p + 1 //k表示子数组 A[p…q]内的元素个数,处于划分低区的元素个数加上一个主元元素
5 if i == k //检查要查找的i 等于子数组中A[p....q]中的元素个数k
6 then return A[q] //则直接返回A[q]
7 else if i < k
8 then return RANDOMIZED-SELECT(A, p, q - 1, i)
//得到的k 大于要查找的i 的大小,则递归到低区间A[p,q-1]中去查找
9 else return RANDOMIZED-SELECT(A, q + 1, r, i - k)
//得到的k 小于要查找的i 的大小,则递归到高区间A[q+1,r]中去查找。
写此文的目的,在于起一个抛砖引玉的作用。希望,能引起你的重视及好的思路,直到有个彻底明白的结果。
updated:算法导论原英文版有关于RANDOMIZED-SELECT(A, p, r)为O(n)的证明。为了一个彻底明白的阐述,我现将其原文的证明自个再翻译加工后,阐述如下:
此RANDOMIZED-SELECT最坏情况下时间复杂度为Θ(n2),即使是要选择最小元素也是如此,因为在划分时可能极不走运,总是按余下元素中的最大元素进行划分,而划分操作需要O(n)的时间。
然而此算法的平均情况性能极好,因为它是随机化的,故没有哪一种特别的输入会导致其最坏情况的发生。
算法导论上,针对此RANDOMIZED-SELECT算法平均时间复杂度为O(n)的证明,引用如下,或许,能给你我多点的启示(本来想直接引用第二版中文版的翻译文字,但在中英文对照阅读的情况下,发现第二版中文版的翻译实在不怎么样,所以,得自己一个一个字的敲,最终敲完修正如下),分4步证明:
1、当RANDOMIZED-SELECT作用于一个含有n个元素的输入数组A[p ..r]上时,所需时间是一个随机变量,记为T(n),我们可以这样得到线性期望值E [T(n)]的下界:程序RANDOMIZED-PARTITION会以等同的可能性返回数组中任何一个元素为主元,因此,对于每一个k,(1 ≤k ≤n),子数组A[p ..q]有k个元素,它们全部小于或等于主元元素的概率为1/n.对k = 1, 2,...,n,我们定指示器Xk,为:
Xk = I{子数组A[p ..q]恰有k个元素} ,
我们假定元素的值不同,因此有
E[Xk]=1/n
当调用RANDOMIZED-SELECT并且选择A[q]作为主元元素的时候,我们事先不知道是否会立即找到我们所想要的第i小的元素,因为,我们很有可能需要在子数组A[p ..q - 1], 或A[q + 1 ..r]上递归继续进行寻找.具体在哪一个子数组上递归寻找,视第i小的元素与A[q]的相对位置而定.
2、假设T(n)是单调递增的,我们可以将递归所需时间的界限限定在输入数组时可能输入的所需递归调用的最大时间(此句话,原中文版的翻译也是有问题的).换言之,我们断定,为得到一个上界,我们假定第i小的元素总是在划分的较大的一边,对一个给定的RANDOMIZED-SELECT,指示器Xk刚好在一个k值上取1,在其它的k值时,都是取0.当Xk =1时,可能要递归处理的俩个子数组的大小分别为k-1,和n-k,因此可得到递归式为
取期望值为:
为了能应用等式(C.23),我们依赖于Xk和T(max(k - 1,n - k))是独立的随机变量(这个可以证明,证明此处略)。
3、下面,我们来考虑下表达式max(k - 1,n -k)的结果.我们有:
如果n是偶数,从T(⌉
给我老师的人工智能教程打call!http://blog.csdn.net/jiangjunshow