一、如何选择RabbitMQ的消息保存方式?
RabbitMQ对queue中message的保存有两种方式:disc和ram。
如果采用disc,则需要对exchange/queue/delivery mode都要设置成durable模式。
disc方式的好处是当RabbitMQ失效了,message仍然可以在重启之后恢复;而使用ram方式,RabbitMQ处理message的效率要高很多,ram和disc两种方式的效率比大概是3:1。
所以如果在有其它HA手段保障的情况下,选用ram方式是可以提高消息队列的工作效率的。
二、当消息发送的速率超过了RabbitMQ的处理能力时该怎么办?
RabbitMQ会自动减慢这个连接的速率,让client端以为网络带宽变小了,发送消息的速率会受限,从而达到流控的目的。 使用“rabbitmqctl list_connections”查看连接,如果状态为“flow”,则说明这个连接处于flow-control 状态。
三、RabbitMQ集群结构
RabbitMQ基于Erlang编写,天然支持clustering。集群是保证可靠性的一种方式,同时可以通过水平扩展以达到增加消息吞吐能力的目的。
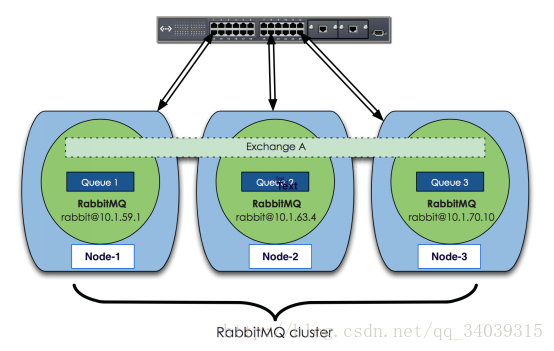
上图中是三个节点的RabbitMQ集群,Exchange A的metadata信息在所有节点上是一致的,queue的完整信息则只在它创建的那个节点上。每个RabbitMQ节点通常以“rabbit@”表示,所以hostname在运行RabbitMQ的节点中很重要。注意:如果更改了hostname,需要重置RabbitMQ内部的数据库,否则服务无法工作。
四、数据流动
RabbitMQ维护着四种类型的metadata: queue/exchange/binding/vhost,在集群中这些信息被同步到每个节点,因此当用户访问任何一个节点时,通过rabbitmqctl查询到的queue/user/exchange等信息都是相同的。
通常我们将这些信息保存到磁盘上,也就是查询RabbitMQ状态时的“disc”方式,以便集群重启时可以根据保存的metadata信息重建exchange等。
对于exchange来讲,它的所有信息就是一个exchange名字加上一个查询表。查询表中记录了所有的queue binding。当message被发送到exchange时,client连接的channel对routing key进行比对,根据binding进行正确的转发。
对于Queue来讲,虽然它的metadata在每个节点上都有,但只有在它被创建的那个RabbitMQ节点上才具有完整的信息:比如state/contents等,这个node被称为此queue的owner node。其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
如果一个client访问RabbitMQ的节点上没有所需要queue的完整信息,RabbitMQ将根据这个指针将请求转发到owner node。所以一个客户端最好一直只和一个节点连接,这样效率高一点。
Mnesia是RabbitMQ中的数据库,它是内嵌在Erlang中的no-SQL数据库。Exchange/Queue/Binding等的metadata信息都保存在mnesia的数据库文件中。关于RabbitMQ的集群信息也保存在这里。Rabbitmqctl的reset操作实际上就是清空了mnesia数据库所在目录的内容。
参考: