效果
先看效果吧

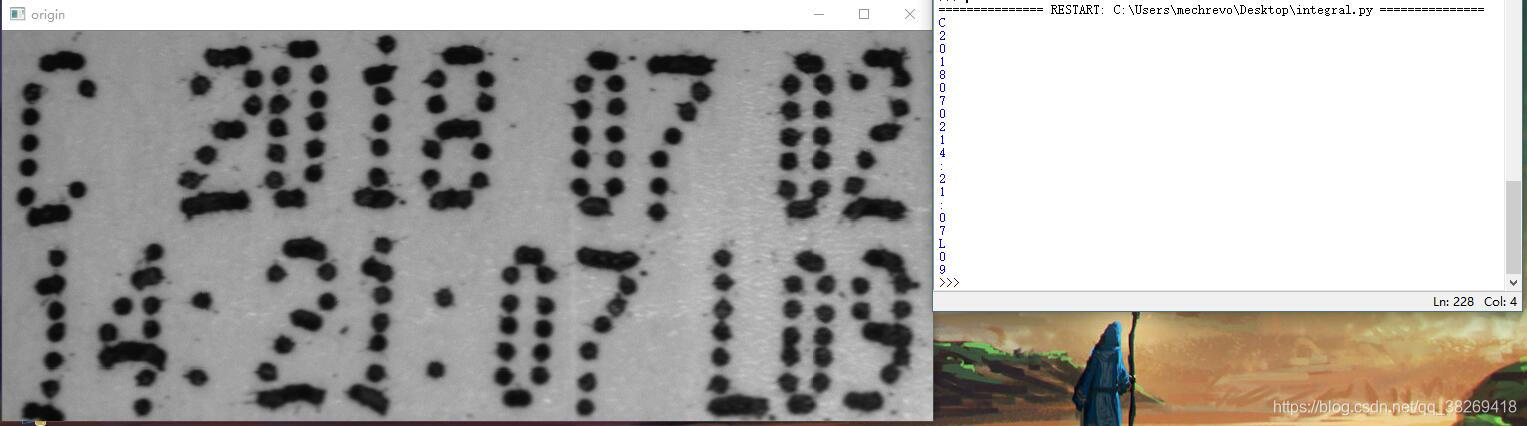

效果极佳,
方法
1.制作模板
将分割出来的数字,效果很不错的当作我们的模板,后面用作匹配,C L :都当作数字处理

2.读入模板,
这里我通过建立三维数组,采用for循环读入
注意,读取时候,要加0参数,不然会以三通道方式读取。
templatepath="C:\\Users\\mechrevo\\Desktop\\template\\" #模板
template=np.zeros([dsize,dsize,13],np.uint8) #注意uint8为1通道,默认为 3通道
for i in range(13):
#print(i)
template[:,:,i] = cv2.imread(templatepath + "%d.png" %i, 0)
3.读入分割出来的图片
将上一节分割出来的20张图片,都读入进去,同样构建三维数组,for循环读入
img=np.zeros([dsize,dsize,20],np.uint8)
for i in range(20):
# print(i)
img[:,:,i] = cv2.imread(root + "%d.png" %i, 0) #记住参数 0
#cv2.imshow("s"+ "%d" %i, img[:,:,i])
4.逐一匹配
采用嵌套for循环,使得每个分割的图像与模板匹配,算出来的rez值最大的,就是最有可能的字符,这里采用cv2.TM_CCOEFF_NORMED标准相关匹配方法,这是 OpenCV 支持的最复杂的一种相似度算法。这里的相关运算就是数理统计学科的相关系数计算方法。
总之,越复杂,占用cpu越多,越耗时,但是越准确。
res=np.zeros([13],np.float16)
for i in range(20):
for j in range(13):
res[j] = cv2.matchTemplate(img[:,:,i],template[:,:,j],cv2.TM_CCOEFF_NORMED) #注意逻辑
maxindex = np.argmax(res)
if (maxindex<10 and maxindex >=0):
print(maxindex)
elif (maxindex == 10):
print("C")
elif (maxindex == 11):
print("L")
elif (maxindex == 12):
print(":")
#print(res)
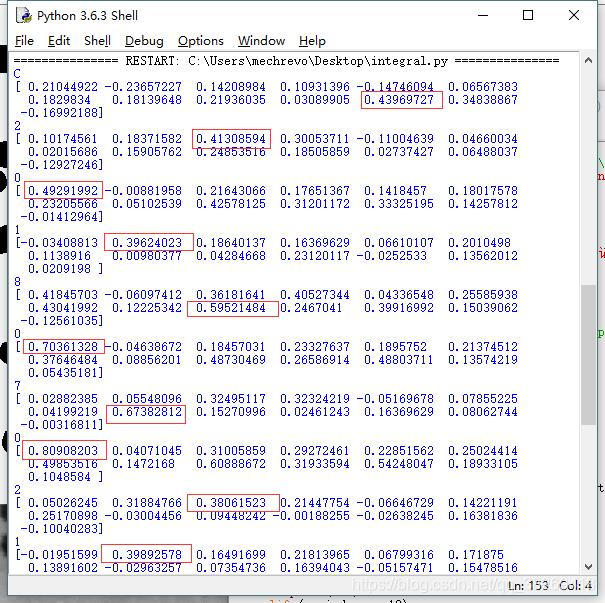
看看谁最大,使用np.argmax直接得出答案,在等于10,11,12加入判断即可
效果如顶部那样,统计了50张图,也就是1000个数字,准确率为95.2%
不足
当然算法还有一些不足之处:
比如:
1.如果字符不为20的话,算法会出错,只不过我的数据集90%的图都是20个字符的,要改进,可以使用文件操作相关函数
2.对于0和8,或扭曲数字,很容易出错,有机会我会尝试卷积神经网络。
3.对于一些扭曲的图片,两行直接没有白色像素,有很小几率会无法切割行。
总之,这只是一门选修课,我也不愿太费心思去继续改进,有什么问题可以评论区交流.
等结课后公布完整代码,供大家学习交流。