本文是基于智东西公开课《零算法基础的百度EasyDL定制化图像识别揭秘》整理的学习笔记
本文非广告,标注单纯是出于尊重智东西和EasyDL的知识产权
如若涉及侵权,请联系本人
作者:李皮皮
谢绝任何不标注原出处的转载以及百度百家号抄袭
本次公开课为期一小时,涉及四个方面:
1. AI赋能行业的的痛点
2. EasyDL服务端和设备端技术解析
3. GPU集群加速EasyDL训练与推理
4. EasyDL赋能行业案例分享
AI赋能行业的痛点
在目前的AI行业中,需求大致可以分为两种:通用需求和定制需求。
对于通用需求,我们可以用通用模型解决。例如语音识别,图像识别,OCR,人脸识别等。
对于定制需求,则是一些通用模型解决不了的问题。例如辅助医药工作者对中草药进行鉴定,生物研究辅助研究员对生物品种进行分类……在本科阶段,北京邮电大学经管院的陈霞老师曾告诉过我们,电子商务做的就是抓用户的痛点,这一点也同样适用于互联网行业。根据百度AI技术生态部高级算法工程师赵鹏昊老师的介绍,AI定制需求的核心诉求大概有三个:
(1)客户往往需要使用自己的数据训练自己特有的模型
(2)客户通常对自己领域都有很强的专业知识,但是并不了解深度学习(以下简称DL),也不愿意去做复杂的模型训练、服务部署和运维
(3)客户的需求往往比较急切,希望快速验证模型效果(并直接获得可集成的定制化服务API和私有化部署能力)
根据这些痛点,百度的EasyDL应运而生,大致服务流程如下:
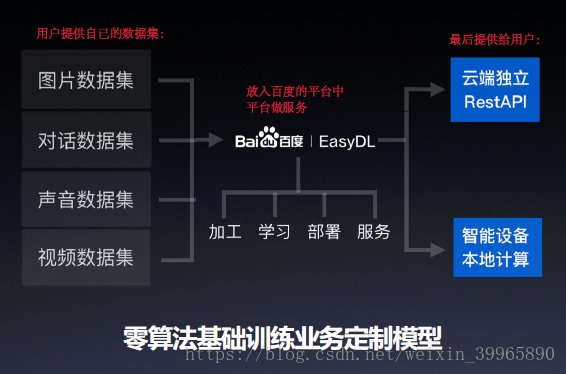
——图片摘自智东西公开课课件
这款产品的亮点是,它不仅提供云端的API服务,更提供了离线SDK的服务,能让用户在线下部署自己的私有化定制。
EasyDL服务端和设备端技术解析
在EasyDL的服务端,有下面几种核心技术:AI Workflow分布式引擎,百度自创PaddlePaddle深度学习框架,迁移学习,Auto Model Search机制, early stoopping机制,模型效果评估机制。下面来一一了解一下。
对于一个DL建模,大致工作流程如下:
(1)在数据仓库提取数据
(2)ETL*进行数据清洗,特征提取,验证集的切分
(3)分布式训练
(4)模型评估
(5)自动服务(auto serving)
* ETL(以下解释摘自百度百科《ETL》【1】):
ETL,是英文 Extract-Transform-Load 的缩写,用来描述将数据从来源端经过抽取(extract)、交互转换(transform)、加载(load)至目的端的过程。ETL一词较常用在数据仓库,但其对象并不限于数据仓库。
ETL是构建数据仓库的重要一环,用户从数据源抽取出所需的数据,经过数据清洗,最终按照预先定义好的数据仓库模型,将数据加载到数据仓库中去。
信息是现代企业的重要资源,是企业运用科学管理、决策分析的基础。目前,大多数企业花费大量的资金和时间来构建联机事务处理OLTP的业务系统和办公自动化系统,用来记录事务处理的各种相关数据。据统计,数据量每2~3年时间就会成倍增长,这些数据蕴含着巨大的商业价值,而企业所关注的通常只占在总数据量的2%~4%左右。因此,企业仍然没有最大化地利用已存在的数据资源,以至于浪费了更多的时间和资金,也失去制定关键商业决策的最佳契机。于是,企业如何通过各种技术手段,并把数据转换为信息、知识,已经成了提高其核心竞争力的主要瓶颈。而ETL则是主要的一个技术手段。
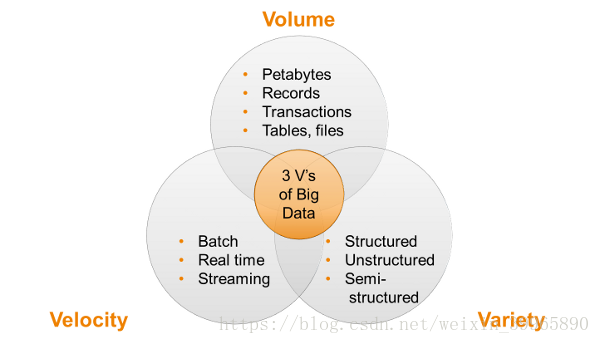
这里需要注意,可能我们会有一个误区——AI训练集不需要太大。其实,AI的训练集往往都符合大数据的经典3V原则*,所以我们需要用MongoDB,Hadoop的DFS做数据存储、用spark集群做分布式预处理和模型评估、使用百度的PaddlePaddle调用框架建模,最后把训练好的模型通过Docker技术做AI平台服务。个人认为这是一个很好的学习指南,让大数据工程师能够很好查漏补缺。
大数据经典3V原则(摘自动点科技文章【2】):
如果你问人们,大数据是什么?比较样板化的答案通常是三个 V:数量(volume),效率(velocity)和广阔性(variety)。接下来他们会开始讨论,他们的数据到底有多大才能被定义为“大数据”。当你开始看到实际技术的时候,事情开始变得比较复杂。这些主要的挑战使事情发展到,今天已经没有单一的一种科技可以一次性处理有关于大数据的三个 V 的所有问题——数量。效率和广阔性。
刚才提到了的核心技术除去AI workflow, 还有百度自创PaddlePaddle深度学习框架。PaddlePaddle全名叫做PArallel Distributed Deep Learning, “是一个深度学习框架/语言”。在EasyDL中,Paddle有如下应用示例:
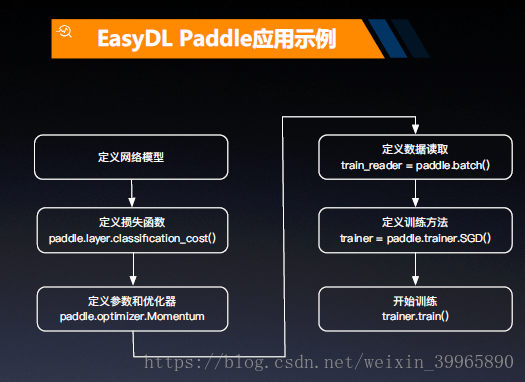
——摘自智东西公开课课件
可以看到,它可能是一个类TensorFlow的框架,具体我也没有了解过,就过了。
下面重点讲一下迁移学习(transfer learning)*。在我看来,迁移学习在百度这个产品中占据的是核心地位,为什么呢?因为普通的机器学习不能很好满足客户需求。一般来说有定制化需求的客户的标注数据都是很有限的,甚至其领域内的数据标注成本非常高。在这样的情况下,客户的需求确实通过较少的数据快速获得可用且准确率较高的模型。一般来说,从开头开始搭建神经网络显然不符合这样的客户需求。为了解决这个矛盾,百度使用了迁移学习。举个栗子,做中草药识别模型时,EasyDL会将已有的植物识别模型运用到中草药识别当中去:将百度大规模标注的数据集在深度神经网络上做预训练,将预训练参数加入神经网络中做调解(迁移学习),从而大大提高效率。这样可以将几十个小时的训练降低到几小时甚至几分钟量级。此外,EasyDL还支持多点预训练,持续闭环等机制,使得工作流实现配置化和自动化。
迁移学习(摘自知乎用户“刘诗昆”关于《什么是迁移学习(Transfer Learning)?这个领域历史发展前景如何?》的回答【3】)
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
这里不禁想感叹一下当时学《电子商务概论》课程时,就觉得百度和腾讯是紧紧抓住了流量入口的。现在百度的搜索引擎产生的数据量真是奠定了其数据霸主的地位啊。
此外,EasyDL还使用了Auto Model Search 和 Early stopping机制,让少两样本就能有用高精度。Auto Model Search就是对模型结构和超参数做自动搜索,更好匹配不同类型数据,做最佳模型。而early stopping呢,能够降低过拟合风险。做过DL的同学应该都有体会,DL是能分分钟过拟合的,对于这种风险,early stopping能很好抑制过拟合和欠拟合。目前EasyDL的模型绝大多数准确率都在80%以上。
技术本身是一方面,学统计的同学肯定有体会,模型的评估也是至关重要的。在呈现评估结果时,EasyDL就非常好的利用了混淆矩阵的各个指标和F1-score,做了尽可能精细的结果展示。这里我觉得有一个亮点,就是bad case的展示。一般可能大家是不愿意把拟合的不好的结果放出来的,但是百度这里把badcase放出来,让客户对预测结果有了一个感性的认知。再结合其领域内专业知识,说不定可以很好解决错误分类的问题,而且也有利于他们专门对错误分类的数据做一个训练集的补充。
下面来学习一下EasyDL设备端计算(Edge Computing)。据赵鹏昊老师说,这个设备端的实现是谷歌目前都没有的。这个创意我觉得超级好,现在真的有一点资源浪费严重了,上云就是高大上,但是并不是所有开发都需要云端才能完成的,够用就可以了。EasyDL在自己的设备上就可以完成,如果算力不够,就会进入雾计算;如果雾计算也不能满足需求,才会启动云计算。这样的多层计算结构很好的抑制了浪费(就是不知道真实情况如何了)。然后放一个云计算和设备端计算的对比课件:
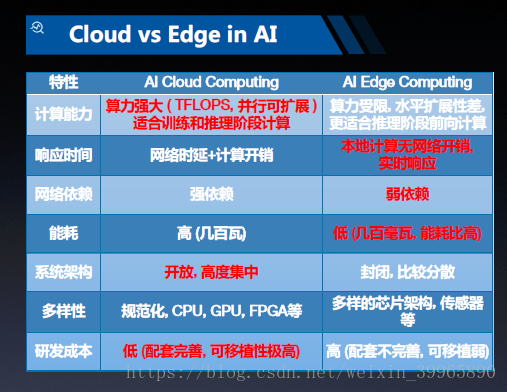
服务器集群训练的机器学习模型通常大小都在200MB-500MB,其本质原因是模型含有上千万的单精度浮点参数。显然对于手机这样的设备端是不可能给这么多内存来计算的。所以就需要对模型进行体积压缩,通常目标体积为20MB-30MB。采用的压缩技术有:参数剪枝(Pruning),将浮点数量化成8bit或者4bit的数值,轻量网络(SqueezeNet, MobileNet)。
除去压缩问题,还有设备加速问题,这里通过异构芯片实现加速。还有一个小知识点,对于IOS的游戏开发,MPS库是一个常用的加速手段,更好利用IOS上的GPU做加速。还有使用ARM芯片通过NEON技术加速。
GPU集群加速EasyDL训练与推理
这一趴老师主要讲了一下英伟达GPU*集群的构成。通常使用的是英伟达特斯拉系列搭建平台,有P4, P40, V100这三个版。P4显存8G, P40显存24G, 所以通常用P4做部署,P40和V100做训练。结论就是GPU集群在做图像分类和物体检测时,性能远超CPU集群。EasyDL用户最快五分钟就可以使用小规模数据集训练,完成定制化模型并获得服务。并且GPU集群的分布式架构能够确保任何单节点的故障都不会影响整体的服务能力。
其实有一个细思极恐的问题,百度的EasyDL能够在短时间内完成如此快速的计算,一方面是算法等百度自身开发的功劳,但是有一个大功劳是英伟达的(“P4提升吞吐量高达30倍,同时延迟降低75%”)。不禁让人想起了中兴的惨案。核心的技术还是掌握在别人手里。
GPU与CPU的区别与联系(摘自CSDN用户“JackZhangNJU”的文章【4】)
从硬件来分析,CPU和GPU似乎很像,都有内存、cache、ALU、CU,都有着很多的核心,但是二者是有区别的。
但以核心为例,CPU的核心比较重,可以用来处理非常复杂的控制逻辑,预测分支、乱序执行、多级流水等等CPU做得非常好,这样对串行程序的优化做得非常好;
但是GPU的核心就是比较轻,用于优化具有简单控制逻辑的数据并行任务,注重并行程序的吞吐量。
简单来说就是CPU的核心擅长完成多重复杂任务,重在逻辑,重在串行程序;GPU的核心擅长完成具有简单的控制逻辑的任务,重在计算,重在并行。
另外,并行和并发的概念是不一样的,并行就是大家一起干,同时去做,并发就是多线程竞争资源
EasyDL赋能行业案例分享
这一部分是我觉得最有意思的了。目前EasyDL能解决的问题有三类,图像分类、物体检测和定制声音识别,还在开发别的功能(文字分类,情绪情感分析,视频监控)。给出了四个案例:
(1)蝶鱼科技:使用3000张图片训练,在制造和组装键盘流水线中,识别键盘组装后的合格性,将键盘图片分类。每条生产流水线每年节省12万人工检测员人力成本,准确率高达99%【科技是第一生产力啊。。。真是可怕】
(2)checkpoint零售安防:这是美国的一家连锁超市,用于识别购物车下层是否有未付款商品,需求是精准排除残疾人购物车和儿童购物车。之前该公司使用的是传感器,准确率极差,使用了DL后,准确率高达95%。据老师说,目前该公司计划全部更新店铺设备,使其能与百度EasyDL全面接轨。
(3)惠合科技e店佳:这个也非常有意思,是通过拍摄视频来识别超市的物品陈列是否符合要求。在以往,需要专人到店铺挨个检查,不但耗时耗力,还有很多作弊情况。使用DL后,审核效率提升了30%。这让我想到了除去法律和道德,科技也可以做到约束人性丑恶,减少作弊。
(4)CELLA(百度合作伙伴):CELLA为圣象地板做木地板瑕疵检测木星,并且发布生成离线SDK.检测率高达95%,提高了产能——处理单片木板原料的单位时间仅为原来的四分之一。
当然EasyDL也存在很多问题,我能想到的一个就是目前的数据标注问题,老师也提到目前是用户自己标注,后面可能会有众包。
真是该好好关注一下各大互联网公司的AI部署了,感觉自己好落后~~
参考文献:
【1】https://baike.baidu.com/item/ETL/1251949?fr=aladdin