洛谷试炼场---提高历练地
搜索Ex
1.NOIP 2004 提高组 复赛 alpha 虫食算
//P1092 虫食算//读完题目,第一直觉,要用高精度算法。
//N进制,该题处理,对理解进制很有帮助。
//为何要从高位往低位搜索,这篇文章写得不错http://blog.sina.com.cn/s/blog_918b1f910100zuzr.html摘抄如下:
// 仔细考虑过后,因为我们是从最低位开始搜的,而且,3个数全都是N位,所以高位数组一般较小,低位较大,所以 应该从n-1倒过来搜(隐藏得好深啊),这样的话,10组数据,每组都不到100Ms
//在洛谷题解中,找了代码量较小,并且思路比较接近回溯,深度优先遍历的算法进行研究。弄明白后,自己编码,样例通过后
//提交,测试点3 WA,下载测试点进行研究
//发现如下错误:for(j=n-1;j>=0;j--)////1 错写成for(j=n;j>=1;j--) 2错写成 for(j=n-1;j>0;j--)
//因为忙,该题从入手到,编写成功。历时三天
#include <stdio.h>
#include <string.h>
#include <stdlib.h>//exit(0);需要的头文件
int n,b[100],c[100],vis[30],d[30];
char a[5][30];
int judge1(){//初判断
int i;
for(i=n-1;i>=0;i--)////1 错写成for(i=n;i>=1;i--) 2 错写成for(i=n-1;i>0;i--)
if(c[a[1][i]]!=-1&&c[a[2][i]]!=-1&&c[a[3][i]]!=-1&&
(c[a[1][i]]+c[a[2][i]])%n!=c[a[3][i]]&&
(c[a[1][i]]+c[a[2][i]]+1)%n!=c[a[3][i]])
return 0;
return 1;
}
int judge2(){
int i,k=0;
for(i=n-1;i>=0;i--){//1 错写成for(i=n;i>=1;i--) 2 错写成 for(i=n-1;i>0;i--)
k=c[a[1][i]]+c[a[2][i]]+k;
if(k%n!=c[a[3][i]])//剪枝2
return 0;
k/=n;
}
return 1;
}
void print(){
int i;
printf("%d",c['A']);
for(i='A'+1;i<'A'+n;i++)
printf(" %d",c[i]);
printf("\n");
}
void dfs(int step){
int i;
if(judge1()==0)//剪枝1
return ;
if(step==n+1){
if(judge2()==1){
print();
exit(0);//只有一个答案
}else//剪枝2
return ;
}
for(i=n-1;i>=0;i--){
if(vis[i]==0){
vis[i]=1;
c[d[step]]=i;
dfs(step+1);
vis[i]=0;
c[d[step]]=-1;
}
}
}
int main(){
int i,j,k=1;
memset(b,0,sizeof(b));
memset(vis,0,sizeof(vis));
memset(c,-1,sizeof(c));
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%s",a[i]);
for(j=n-1;j>=0;j--)////1 错写成for(j=n;j>=1;j--) 2错写成 for(j=n-1;j>0;j--)
for(i=1;i<=3;i++)
if(b[a[i][j]]==0){
b[a[i][j]]=1;
d[k++]=a[i][j];//d[]对应ascii值
}
dfs(1);
return 0;
}
2.
3.
4.
5.
动态规划TG.lv(1)
1.//P1005 矩阵取数游戏
NOIP2007 提高组 复赛 game 矩阵取数游戏
1.审题,弄懂样例。
2 3 1 2 3 3 4 2取数如下:第1次1 2;第2次2 3;第3次3 4。
求和如下:1*2+2*2+2*4+3*4+3*8+4*8=82
感觉是贪心算法,但又感觉,贪心算法很可能只能得40分。存在反例,中间的数特别小,靠近行首行尾的数特别大。
2.动态规划,关键是找状态,以及状态转移方程,试试。
3.翻看他人做法,https://wenku.baidu.com/view/9db8950190c69ec3d5bb750c.html该篇写得不错,摘抄如下:
分析:此题为区间动归,做了田忌赛马后,此题的动态转移一点也不难,
f【i,j】表示区间(i,j)所能取得的最大值,取数时必取i或j
所以,转移方程式为f【i,j】=max(f【i+1,j】+a【i】,f【i,j-1】+a【j】)*2
边界为f【i,i】=a【i】*2
此题要用高精度,可以只写加法,把乘以二看做两个相加。还有一个高精度比较大小,为了不超时可把进制设为10000或更大。
注意输出的时候要进行补位。
4.http://blog.csdn.NET/kingzone_2008/article/details/12589993该篇代码长度比较短,适合研究。
5.
http://www.cnblogs.com/Neptune-/p/5546711.html对上文有进一步的解释:
需要注意的地方:1.M和N给的范围略坑啊,2^80只有悄悄不说话了,所以直接上了100000的压位,感觉比高精好使多了
2.2的次方多次用到,所以预先处理出来待用
6.//NOIP2007 提高组 复赛 game 矩阵取数游戏
//该题搁置有些久了,今天重新拿起进行处理2017-8-23
//同以往,弄明白样例,还是比较重要的。
//样例1,解析如下:
//第一行 1*2^1+2*2^2+3*2^3=34
//第二行 2*2^1+3*2^2+4*2^3=48
//最大得分 34+48=82
//由上述样例可得思路,每次取出该行,行首或行尾的最小值。
//上述思路,属贪心算法,估计只能过30%的数据,试试看。提交,测试点1,3AC 测试点2,4-10WA
//理解贪心算法为什么错,关键是找一个反例。
//搜索网络,发现一个比较好的贪心的反例http://blog.sina.com.cn/s/blog_5ef211b10100cr25.html
//样例2
//输入:
//1 4
//4 5 0 5
//输出:
//122
//样例2分析如下:

//样例2动态规划,手动模拟如下:
f[1][4]=max(f[2][4]+a[1],f[1][3]+a[4])*2;
f[2][4]=max(f[3][4]+a[2],f[2][3]+a[4])*2;
f[1][3]=max(f[2][3]+a[1],f[1][2]+a[3])*2;
f[3][4]=max(f[4][4]+a[3],f[3][3]+a[4])*2;
f[2][3]=max(f[3][3]+a[2],f[2][2]+a[3])*2;
f[1][2]=max(f[2][2]+a[1],f[1][1]+a[2])*2;
f[1][1]=a[1]*2;
f[2][2]=a[2]*2;
f[3][3]=a[3]*2;
f[4][4]=a[4]*2;
计算如下:
f[1][1]=a[1]*2; f[1][1]=8
f[2][2]=a[2]*2; f[2][2]=10
f[3][3]=a[3]*2; f[3][3]=0
f[4][4]=a[4]*2; f[4][4]=10
f[1][2]=max(f[2][2]+a[1],f[1][1]+a[2])*2; f[1][2]=max(14,13)*2=28
f[2][3]=max(f[3][3]+a[2],f[2][2]+a[3])*2; f[2][3]=max(5,10)*2=20
f[3][4]=max(f[4][4]+a[3],f[3][3]+a[4])*2; f[3][4]=max(10,5)*2=20
f[1][3]=max(f[2][3]+a[1],f[1][2]+a[3])*2; f[1][3]=max(24,28)*2=56
至此,应该可以说,掌握了区间动态规划。
//接下来,采用非高精度算法,进行动态规划,估计能拿60分。
//高精度算法,动态规划,提交,测试点2-10 WA 采用之前编好的非高精度算法,与当前程序,进行数据对比
//查了整整两天,程序的最大问题找到,memset(x,0,30*sizeof(int));//13 该函数的问题查了整整两天,在函数内传入的是x的收地址,x元素的个数在该函数体内未知,故函数体内memset要慎用memset(x,0,sizeof(x)); 4 漏了该句 初始化
//提交AC,2017-8-26 终于AC,虽然代码写得很乱,但正是宣告,贪心,动态规划,高精度算法,上了一个新台阶,有独立完成的能力。
总结:考试时,提交程序时,为了保证得分,非高精度算法更好,程序简单,不容易错,通常都能得到60分以上。
附上动态规划,高精度算法,AC代码。
#include <stdio.h>
#include <string.h>
int a[85][85];
int f[85][85][30],z1[30],z2[30],ans[30];//4 改进写法 z1[85][85][30],z2[85][85][30]
void add1(int *x,int y,int *z){//pass //x+y=z 每个元素表示4位,x[][][0]表示数据长度
int i;
memset(x,0,30*sizeof(int));//13 该函数的问题查了整整两天,在函数内传入的是x的收地址,x元素的个数在该函数体内为止,故函数体内memset要慎用memset(x,0,sizeof(x)); 4 漏了该句 初始化
for(i=z[0];i>=0;i--)//12漏了两句
x[i]=z[i];
x[1]+=y;//10 x[i]=z[i]+y;此句原来写在for循环内部
for(i=1;i<=z[0];i++){
x[i+1]+=x[i]/10000;//9 此处写成 x[i+1]+=z[i]/10000; 查了好久好久
x[i]%=10000;
}
if(x[i])//5 此处写成 if(z[s][e][i]) 程序改了后,需要修改的地方很多,牵一发动全身
x[0]=z[0]+1;//2 低级错误,查了有点久,z[s][e][0]=x[s][e][0]++;x[s][e][0]先赋值,再自加
}
void add2(int *x,int *y){
int i,len;
x[0]=x[0]>y[0]?x[0]:y[0];//6 此处写成 ans[0]=ans[0]>y[s][e][0]?ans[0]:y[s][e][0];
len=x[0]>y[0]?y[0]:x[0];//取小的
for(i=1;i<=len;i++)//12漏了两句
x[i]+=y[i];
for(i=1;i<=x[0];i++){
x[i+1]+=x[i]/10000;//6 此处写成 ans[i+1]+=ans[i]/10000;
x[i]%=10000;//6 此处写成 ans[i]%=10000;
}
if(x[i])//6 此处写成 if(ans[i])
x[0]=x[0]+1;//6 此处写成 ans[0]=y[s][e][0]+1;2 低级错误,查了有点久,ans[0]=y[s][e][0]++;y[s][e][0]先赋值,再自加
}
void mul(int *x,int y,int *z){//x+y=z 每个元素表示4位,x[][][0]表示数据长度
int i;
z[0]=x[0];//1 漏了该句
for(i=1;i<=x[0];i++)//11 漏了两句,对乘法运算理解不深刻
z[i]=x[i]*y;
for(i=1;i<=x[0];i++){
z[i+1]+=z[i]/10000;
z[i]%=10000;
}
if(z[i])
z[0]=x[0]+1;//2 低级错误,查了有点久,z[s2][e2][0]=x[s1][e1][0]++; x[s1][e1][0]先赋值,再自加
}
int cmp(int *x,int *y){//x>y 1 x<y -1 x=y 0
int i;
if(x[0]>y[0])return 1;
else if(x[0]<y[0])return -1;
else{
for(i=x[0];i>=1;i--)
if(x[i]>y[i])
return 1;
else if(x[i]<y[i])
return -1;
return 0;
}
}
int main(){
int i,j,n,m,s,e,k,p;
memset(f,0,sizeof(f));
memset(ans,0,sizeof(ans));
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)//1 此处写成 for(j=1;j<=n;j++)
scanf("%d",&a[i][j]);
for(i=1;i<=n;i++){
memset(f,0,sizeof(f));//8 漏了初始化
for(k=1;k<=m;k++)
f[k][k][0]=1,f[k][k][1]=a[i][k]*2;
for(k=1;k<=m;k++)
for(j=1;j<=m;j++)
if(j+k<=m){
add1(z1,a[i][j],f[j+1][j+k]);
add1(z2,a[i][j+k],f[j][j+k-1]);
if(cmp(z1,z2)==1)
mul(z1,2,f[j][j+k]);
else
mul(z2,2,f[j][j+k]);
}else
break;
add2(ans,f[1][m]);
}
printf("%d",ans[ans[0]]);
for(i=ans[0]-1;i>=1;i--)
printf("%04d",ans[i]);//3 printf("%05d",ans[i]); 低级错误 10000 四位即可进位
return 0;
}
//非高精度,动态规划 得分60分 测试点7-10WA 如果是考试,这个得分,应该比较满意了。
#include <stdio.h>
int a[85][85];
long long f[85][85];
long long max(long long a,long long b){
return a>b?a:b;
}
int main(){
int i,j,n,m,s,e,k;
long long ans=0;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)//1 此处写成 for(j=1;j<=n;j++)
scanf("%d",&a[i][j]);
for(i=1;i<=n;i++){
for(k=1;k<=m;k++)
f[k][k]=a[i][k]*2;
for(k=1;k<=m;k++)
for(j=1;j<=m;j++)
if(j+k<=m){
f[j][j+k]=max(f[j+1][j+k]+a[i][j],f[j][j+k-1]+a[i][j+k])*2;
}else
break;
ans+=f[1][m];
}
printf("%lld\n",ans);
return 0;
}
//附上贪心算法,得分20
#include <stdio.h>int a[85][85];
long long mul(int k){
long long ret=1,i;
for(i=1;i<=k;i++)
ret*=2;
return ret;
}
int main(){
int i,j,n,m,s,e,k;
long long ans=0;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)//1 此处写成 for(j=1;j<=n;j++)
scanf("%d",&a[i][j]);
for(i=1;i<=n;i++){
s=1,e=m,k=0;
while(s<=e){
k++;
if(a[i][s]<a[i][e]){
ans+=a[i][s]*mul(k);
s++;
}
else{
ans+=a[i][e]*mul(k);
e--;
}
}
}
printf("%lld\n",ans);
return 0;
}
2.//P1373 小a和uim之大逃离
//http://m.blog.csdn.net/VSEJGFB/article/details/76598747此文思路介绍不错,摘抄如下:
//一看这题首先想到设d(i,j,k1,k2,0)表示在小a刚吸完i,j这个位置的魔液,小a和uim的魔瓶的魔液量分别为k1,k2时的方案数,d(i,j,k1,k2,1)表示在uim刚吸完……的方案数。
//但是这样明显会爆内存…于是我就一直卡着了。后来看到讨论区有差这个字,才想到把状态减少到d(i,j,k,0)和d(i,j,k,1)其中k为 小a的魔瓶量与uim的魔瓶量之差.
//另外我用的是顺推,感觉更好想。
//http://blog.csdn.net/hyj542682306/article/details/71442354【样例解释】摘抄如下:
//样例解释:四种方案是:(1,1)->(1,2),(1,1)->(2,1),(1,2)->(2,2),(2,1)->(2,2)。
//http://www.cnblogs.com/SilverNebula/p/5793810.html此文思路不错,摘抄如下:
//四维:f[x坐标][y坐标][两人魔液差][谁最后一个走]=方案数
//因为起终点任意,所以初始每个位置的f方案数都是1,最后计算总方案数也要累加每个位置的f[x][y][0][1]
//http://blog.csdn.net/sinat_34943123/article/details/52809687思路不错,摘抄如下:
//首先最直接想到的思路是用f[i][j][k][l][0/1] k和l分别表示走到i,j点时两个人的分数。0、1表示谁吸魔液。
//但是这样需要枚举起点,4维再加两维,伤不起。。。。
//于是乎微调思路,题目只求方案数,而答案只和差值有关,把分数记下来管什么用。。?而且同一个差值对应着多种情况转移而来,枚举所有差值解就是完全的了,起点枚举也免了!直接降为O(n*m*k),可以过了。
//具体细节上,转移时差值可以是负的,这个问题让我头疼了很久(弱),平移数组?可是要模k的,不行。
//最后想到,只要在正的差值中找到和它等价的,也就是模完后加上k就好了。
//http://blog.csdn.net/lpno17/article/details/75090114此文思路介绍不错,摘抄如下:
//很水的DP啊!一眼秒。F[i][j][k]表示DP到(i,j)时,小明和小伙伴的差值为k的方案数,随便递推递推就是了。
//不过恶心的地方在这题卡内存。你必须知道一个性质:就是差值?k和k是等价的。因为你随时可以把两个人混着看。有这个性质在才能少开一半数组。否则就必须做两遍。做两遍的话就会有2个点T ……晕。
//http://blog.csdn.net/rlt1296/article/details/53072024此文思路介绍得相当棒,摘抄如下:
//f[i][j][p][q]表示他们走到(i,j),且两人魔瓶内魔液量的差为p时的方法数。q=0表示最后一步是小a走的,q=1表示最后一步是uim走的。题目中说魔瓶的容量为k,实际上就是动归时p需要对k+1取余数,即p只有0~k,k+1种可能。答案为所有f[i][j][0][1]的和。
//动归方程如下:(为了方便已经令k=k+1)
//f[i][j][p][0]+=f[i-1][j][(p-mapp[i][j]+k)%k][1] (i-1>=1)
//f[i][j][p][0]+=f[i][j-1][(p-mapp[i][j]+k)%k][1] (j-1>=1)
//f[i][j][p][1]+=f[i-1][j][(p+mapp[i][j])%k][0] (i-1>=1)
//f[i][j][p][1]+=f[i][j-1][(p+mapp[i][j])%k][0] (j-1>=1)
//还有每个格子都有可能作为小a的起始格子,所以初始时对于所有i、j,f[i][j][mapp[i][j]][0]=1。
//算法复杂度o(n*m*k)。
//评测机:BanG Dream! 测试点11、12 TLE 评测机:Yukikaze AC 还好再试了一次。
//该题中最难理解的是 差值,本人理解如下:
//f[i][j][g][0]+=f[i-1][j][(g-mp[i][j]+k)%k][1],f[i][j][g][0]%=mod; 中g-mp[i][j]+k理解:
//f[i][j][g][0] 当前 小a 吸收完毕, 小a魔液ka2,uim魔液ku2,差值ka2-ku2=g;之前一步,f[i-1][j][(g-mp[i][j]+k)%k][1],当前 uim 吸收完毕, 小a魔液ka1=ka2-mp[i][j],uim魔液ku1=ku2,差值ka1-ku1=ka2-ku2-mp[i][j]=g-mp[i][j],加k的原因是g-mp[i][j]可能为负
//f[i][j][g][1]+=f[i-1][j][(g+mp[i][j])%k][0],f[i][j][g][1]%=mod;中g+mp[i][j]理解:
//f[i][j][g][1] 当前uim 吸收完毕,小a魔液ka2,uim魔液ku2,差值ka2-ku2=g;之前一步,f[i-1][j][(g+mp[i][j])%k][0],当前小a吸收完毕,小a魔液ka1=ka2,uim魔液ku1=ku2-mp[i][j],差值ka1-ku1=ka2-ku2+map[i][j]=g+mp[i][j]
//再次提交 评测机:BanG Dream! AC 看来评测机 也有卡顿的时候。
//一直对最后循环有问题,重看题目,才发现有这么一句:从任一个格子结束。
//该题彻底弄懂了,动规还是需要一定时间的操练。
//该题比较容易错的地方,差值漏模了。2017-8-17 22:50 AC
#include <stdio.h>
#include <string.h>
#define mod 1000000007
int f[805][805][17][2],a[805][805];//f[][][][0] 小a最后吸液 f[][][][1] uim最后吸液
int main(){
int n,m,k,i,j,p,ans=0;
memset(f,0,sizeof(f));
scanf("%d%d%d",&n,&m,&k);
k++;
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
scanf("%d",&a[i][j]),f[i][j][a[i][j]][0]=1;//小a吸液ka=a[i][j],uim吸液ku=0,差值ka-ku=a[i][j]
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
for(p=0;p<=k-1;p++){
f[i][j][p][1]+=f[i][j-1][(p+a[i][j])%k][0],f[i][j][p][1]%=mod;//2 写成f[i][j][p][1]+=f[i][j-1][p+a[i][j]][0]
f[i][j][p][1]+=f[i-1][j][(p+a[i][j])%k][0],f[i][j][p][1]%=mod;//一直以为 f[i][j][p][1]+=f[i-1][j][p+a[i][j]][0]与 f[i][j][p][0]+=f[i][j-1][p-a[i][j]][1] 顺序不能颠倒 验证后可以颠倒
f[i][j][p][0]+=f[i][j-1][(p-a[i][j]+k)%k][1],f[i][j][p][0]%=mod;
f[i][j][p][0]+=f[i-1][j][(p-a[i][j]+k)%k][1],f[i][j][p][0]%=mod;
}
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
ans+=f[i][j][0][1],ans%=mod;
printf("%d\n",ans);
return 0;
}
3.//P2279 [HNOI2003]消防局的设立
//http://blog.csdn.net/kenxhe/article/details/53026536写得不错
//http://blog.csdn.net/qwsin/article/details/50954698写得也可以
//树形动规的写法,没人指导,确实看不懂,无奈,找能看懂得来研究。
//http://www.cnblogs.com/JSZX11556/p/5102075.html此文做法,摘抄如下:
//一个简单的贪心, 我们只要考虑2个消防局设立的距离为5时是最好的, 因为利用最充分. 就dfs一遍, 再对根处理一下就可以了. 这道题应该是SGU某道题的简化版...这道题距离只有2, 树型dp应该也是可以的
//http://blog.csdn.net/LOI_QER/article/details/52650170思路,摘抄如下:
//思路:考虑到 一个消防局可以扑灭与他距离 <= 2 的所有点。那么我们每隔4个点放一个消防局是最优的。
//在 dfs 中:我们用数组 f[] 标记每个点 某种程度上可以说 abs(f[x]-5) 就是 x 到消防局的距离。当 f[x] == 5 时 那我们另 f[x] == 0 即,把这个看为一个消防局 ans ++;
//还有一个地方就是处理一下边界,即开始的点,如果走到了这里而这里距离最近的消防局的距离大于等于3,也就是这里没有被消防局覆盖,那就只能在这里也加上一个消防局了。
//http://blog.csdn.net/zhouyuyang233/article/details/69941733代码写得不错
//http://blog.csdn.net/pbihao/article/details/52728013注释写得不错
//很无奈,最容易理解的,代码比较长,程序还是按好理解的来写,http://blog.csdn.net/qq_33728185/article/details/52496878摘抄如下:
//首先,该题树形DP可解,但是这里介绍贪心的做法。
//显然,对于目前深度最深的点,如果他的父亲、爷爷、他父亲的儿子和它自己上没有建消防局,那么该点不可能被覆盖。而在这些点中,讲消防局建在爷爷节点收益最大,因为爷爷节点建消防局覆盖的范围一定包括父亲结点与该节点发亲的儿子建消防局的范围。
//这样,我们按照深度把所有结点排一下序,然后每次重复在最深的节点的爷爷节点上建立消防局即可。
//为了更好的理解该题程序,编写了几组样例数据,并配图
//样例1:
配图:
输入:
6 1 2 3 4 5
输出:
2
//样例2
//配图:

//输入:
4
1
1
1
//输出:
1
//样例3:
//配图:

//输入:
16
1
2
2
3
3
4
4
5
5
6
6
7
7
8
8
//输出:
2
//编写测试数据过程中,深深的感觉到,该题的最小深度是以节点1为根节点的树。
//编写程序一蹴而就,2017-8-22 21:30 AC//树,图,(深度优先遍历)是少不了的。
#include <cstdio>
#include <cstring>
#include <algorithm>
using namespace std;
int head[1000+10],cnt=0,father[1000+10],vis[1000+10],ans=0;//father[x]节点x的父节点
struct node1{
int d,v;//d深度 v节点值
}q[1000+10];
struct node2{
int to,next;//to指向节点,next下一条边
}e[1000*2+10];//正向边,反向边
void addedge(int u,int v){//邻接表 存储方式
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt;
}
int cmp(node1 a,node1 b){//由大到小排序
return a.d>b.d;
}
void deep(int x,int f){//获取节点深度 u是子节点,f是父节点
int b,v;
father[x]=f;
q[x].d=q[f].d+1;//深度计算 父节点深度+1
q[x].v=x;
for(b=head[x];b;b=e[b].next){
v=e[b].to;
if(f==v)continue;//f深度以及值已被设置过,无需设置,故continue
deep(v,x);
}
}
void station(int x,int c){//标记能被扑灭的节点,c访问层数
int b;
if(c>2)return;
vis[x]=1;
for(b=head[x];b;b=e[b].next)
station(e[b].to,c+1);
}
int main(){
int n,i,j,v;
memset(head,0,sizeof(head));
memset(father,0,sizeof(father));
memset(vis,0,sizeof(vis));
q[0].d=0;
scanf("%d",&n);
for(i=2;i<=n;i++){
scanf("%d",&v);
addedge(i,v),addedge(v,i);//邻接表,正向边,反向边
}
deep(1,0);
sort(q+1,q+n+1,cmp);//按深度,由大到小进行排序
for(i=1;i<=n;i++){
if(vis[q[i].v])continue;
if(father[father[q[i].v]])v=father[father[q[i].v]];
else if(father[q[i].v])v=father[q[i].v];
else v=q[i].v;
station(v,0);//v是设置消防局的节点
ans++;
}
printf("%d\n",ans);
return 0;
}
4.//P1220 关路灯
//特色:一题多解
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1220关于区间动态规划的初步证明,摘抄如下:
//很类似lrj的紫书《算法竞赛入门经典》上面一个题目(P293)
//首先我们发现当前时刻已经关闭的灯在一个连续区间里面最划算。这很显然:如果a和b是不连续的两盏灯,被灯c分开,那么我关了a再去关b的时候完全可以顺带把c关掉,答案只会更好。然后我们发现在关闭了一个连续的区间的灯之后,人一定在端点。
//于是就可以dp了,设f(i,j,k)f(i,j,k)f(i,j,k)为已经关闭了区间[i,j][i,j][i,j]里面的灯时的最小耗电量,k=0表示人在区间左端点,k=1表示人在区间右端点。
//于是f(i,j,0)f(i,j,0)f(i,j,0)就可以从f(i+1,j,0/1)f(i+1,j,0/1)f(i+1,j,0/1)转移而来。考虑从i+1或者j走到点i的路程中,还开着的灯的耗电即可。详见代码。
//http://blog.csdn.net/mrtintin/article/details/76293311此文写得不错,摘抄如下:
//用dp[i][j][0]表示关了[i,j]这个区间的灯,最后关的是第i盏;
//f[i][j][1]表示关了[i,j]这个区间的灯,最后关的是第j盏。
//sum[i]表示从1到i的灯的总功率。cal(i,j)表示除了[i,j]之外灯的总功率
//则有:
//dp[i][j][0]=min(dp[i][j][0],dp[i+1][j][0]+(p[i+1]-p[i])*cal(i+1,j));
//dp[i][j][0]=min(dp[i][j][0],dp[i+1][j][1]+(p[j]-p[i])*cal(i+1,j));
//dp[i][j][1]=min(dp[i][j][1],dp[i][j-1][0]+(p[j]-p[i])*cal(i,j-1));
//dp[i][j][1]=min(dp[i][j][1],dp[i][j-1][1]+(p[j]-p[j-1])*cal(i,j-1));
//http://blog.csdn.net/senyelicone/article/details/52403974此文也写得不错,摘抄如下:
//很久以前刚学动规的时候做过,实际上那时候连区间动规都不知道……现在再看感觉又不一样了啊……
//比较经典的区间动规吧,三个状态f[i][j][k]代表区间[i,j],k是方向,k=0,表示往i走;k=1,表示往j走~
//还有前缀和!
//初始化f的值不能太大!不然会爆掉!
//尝试用四种办法,一题多解,开先河之题,耗时两三天,但能举一反三,值。动态规划,f[i][j][] i<j;i>j两种;深度优先遍历,一种;广度优先遍历,一种。
//深搜,这篇代码写得不错,https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1220 作者: 夏浅默 更新时间: 2015-08-22 10:31
//dfs是一个盏一盏的关灯
//编写完三种方法后,发现广度优先遍历,该题无法使用。2017-8-16 10:25 AC
//以下介绍三种方法,动态规划f[i][j][]i<j;动态规划f[i][j][]i>j;深度优先遍历dfs
方法一:动态规划f[i][j][]i<j
#include <stdio.h>
#include <string.h>
int f[50][50][2],pos[50],v[50];//f[i][j][0]最后关i f[i][j][1]最后关j 区间动态规划,i起点 j终点
int min(int a,int b){
return a>b?b:a;
}
int main(){
int n,c,i,j;
v[0]=0;
memset(f,127,sizeof(f));
scanf("%d%d",&n,&c);
for(i=1;i<=n;i++){
scanf("%d%d",&pos[i],&v[i]);
v[i]+=v[i-1];//v[]前缀和
}
//动态规划
f[c][c][0]=f[c][c][1]=0;
for(j=c;j<=n;j++)//处理过程中i<j
for(i=j-1;i;i--){//1 此处写成 for(i=c-1;i;i--)
f[i][j][0]=min(f[i+1][j][0]+(v[n]-(v[j]-v[i]))*(pos[i+1]-pos[i]),
f[i+1][j][1]+(v[n]-(v[j]-v[i]))*(pos[j]-pos[i]));//f[i+1][j][0]落脚点在i+1 f[i+1][j][1]落脚点在j a[j]-a[i]区间i-j内不包括i
f[i][j][1]=min(f[i][j-1][1]+(v[n]-(v[j-1]-v[i-1]))*(pos[j]-pos[j-1]),
f[i][j-1][0]+(v[n]-(v[j-1]-v[i-1]))*(pos[j]-pos[i]));//a[j-1]-a[i-1]区间i-j内不包括j f[i][j-1][1]落脚点在j-1 f[i][j-1][0]落脚点在i
}
printf("%d\n",min(f[1][n][0],f[1][n][1]));
return 0;
}
方法二:动态规划f[i][j][]i>j
#include <stdio.h>
#define INF 999999
int f[60][60][2],pos[60],v[60];//2 int f[50][50][2],pos[50],v[50]; 测试点2 RE
int min(int a,int b){
return a>b?b:a;
}
int main(){
int n,c,i,j;
scanf("%d%d",&n,&c);
v[0]=0;
for(i=1;i<=n;i++){
scanf("%d%d",&pos[i],&v[i]);
v[i]+=v[i-1];//前缀和
}
//1 memset(f,127,sizeof(f)) 测试点2WA 容易溢出
for(i=1;i<=n;i++)
for(j=1;j<=n;j++){
f[i][j][0]=INF;
f[i][j][1]=INF;
}
f[c][c][0]=f[c][c][1]=0;
for(j=c;j;j--)//i>j
for(i=j+1;i<=n;i++){
f[i][j][0]=min(f[i-1][j][0]+(v[n]-(v[i-1]-v[j-1]))*(pos[i]-pos[i-1]),
f[i-1][j][1]+(v[n]-(v[i-1]-v[j-1]))*(pos[i]-pos[j]));
f[i][j][1]=min(f[i][j+1][1]+(v[n]-(v[i]-v[j]))*(pos[j+1]-pos[j]),
f[i][j+1][0]+(v[n]-(v[i]-v[j]))*(pos[i]-pos[j]));
}
printf("%d\n",min(f[n][1][0],f[n][1][1]));
return 0;
}
方法三:深度优先遍历dfs
#include <string.h>
int pos[60],v[60],vis[60],n,ans=999999,tot=0;
void dfs(int x,int sum,int remain,int step){//x当前关掉灯的序号,sum当前消耗的能量, remain当前亮灯的功率, step当前关灯的盏数
int left=x,right=x;
if(sum>=ans)//剪枝
return;
if(step==n){
ans=sum;
return;
}
while(vis[left]&&left>=1)left--;//1.此处写成while(vis[x]&&left>=1);vis[left]=1表明灯已被关,被关的灯一定是连续的
while(vis[right]&&right<=n)right++;//1.此处写成while(vis[x]&&right<=n)
if(left>=1){
vis[left]=1;
dfs(left,sum+remain*(pos[x]-pos[left]),remain-v[left],step+1);
vis[left]=0;
}
if(right<=n){
vis[right]=1;
dfs(right,sum+remain*(pos[right]-pos[x]),remain-v[right],step+1);
vis[right]=0;
}
}
int main(){
int i,c;
memset(vis,0,sizeof(vis));
scanf("%d%d",&n,&c);
for(i=1;i<=n;i++){
scanf("%d%d",&pos[i],&v[i]);
tot+=v[i];
}
vis[c]=1;
dfs(c,0,tot-v[c],1);
printf("%d\n",ans);
return 0;
}
2017-8-26 AC 该单元
动态规划TG.lv(2)
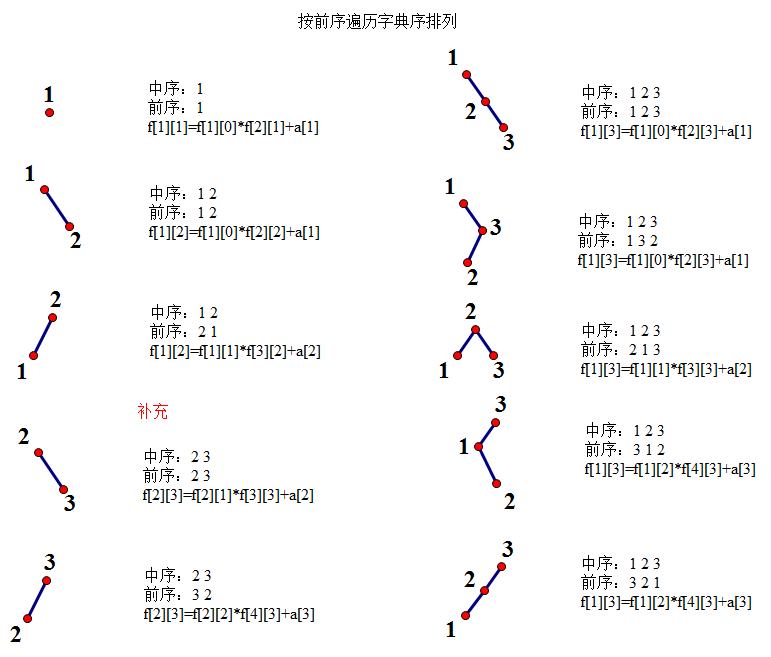
1.//P1040 加分二叉树
NOIP 2003 提高组 复赛 加分二叉树
1.样例1分析是关键:
输入:
5 5 7 1 2 10
输出:
145 3 1 2 4 5
1 2 3 4 5 中序遍历
3 1 2 4 5 前序遍历
分析可得二叉树如下图:
3
/ \
1 4
\ \
2 5
3的左子树计算1*7+5=12
3的右子树计算1*10+2=12
总加分12*12+1=145
2.关于该题,此文介绍得比较详细http://www.cnblogs.com/sdjl/articles/1273759.html
3.http://blog.csdn.NET/senyelicone/article/details/52602151此文代码写得够短。
4.http://www.cnblogs.com/Renyi-Fan/p/7421129.html代码注释写得不错。
5.n=3数据分析处理过程如下:
6.可以开始代码编写。
7.调试代码花了一定时间,样例终于通过了,提交AC。2017-8-29
8.动态规划AC代码如下:
//P1040 加分二叉树
#include <stdio.h>
int a[35],root[35][35];//f[i][j]中序遍历i-j最大分数 root[i][j] i-j的根
long long f[35][35];
void preorder(int left,int right){//先序遍历 传入的参数是 中序遍历的 左边界 与右边界
if(left>right)return;
printf("%d ",root[left][right]);//中序遍历特征,根节点左侧为左子树,根节点右侧为右子树
preorder(left,root[left][right]-1);
preorder(root[left][right]+1,right);
}
int main(){
int n,i,j,k;
scanf("%d",&n);
for(i=0;i<=n;i++)//2 此处写成 for(i=1;i<=n;i++) 查了好久
for(j=0;j<=n;j++)//2 此处写成 for(j=1;j<=n;j++) 查了好久
f[i][j]=1;//i>j f[i][j]值为1
for(i=1;i<=n;i++)
scanf("%d",&a[i]),f[i][i]=a[i],root[i][i]=i;//1 低级错误 ,此处写成 f[i][i]=root[i][i]=a[i];
for(i=n;i>=1;i--)//只有i=n这种方式才能做到f[i][j]从小区间计算到大区间,并且之后的大区间能完全用到前面算好的小区间
for(j=i+1;j<=n;j++)
for(k=i;k<=j;k++)//k从小到大,能保证之后的先序遍历在多解的情况下,按字典序输出
if(f[i][j]<f[i][k-1]*f[k+1][j]+a[k])
f[i][j]=f[i][k-1]*f[k+1][j]+a[k],root[i][j]=k;
printf("%lld\n",f[1][n]);
preorder(1,n);
return 0;
}
//记忆化搜索 2017-8-29 21:30 AC
#include <stdio.h>
#include <string.h>
int a[35],root[35][35];
long long f[35][35];
long long dfs(int left,int right){
int k;
long long t;
if(f[left][right])return f[left][right];
if(left==right)return a[left];
if(left>right)return 1;
for(k=left;k<=right;k++){
t=dfs(left,k-1)*dfs(k+1,right)+a[k];
if(f[left][right]<t){
f[left][right]=t;
root[left][right]=k;
}
}
return f[left][right];//1 漏了该句,很致命
}
void preorder(int left,int right){
if(left>right)return;
if(left==right){printf("%d ",left);return;}//2 漏了该句 if(left==right){printf("%d ",left);return;}
printf("%d ",root[left][right]);
preorder(left,root[left][right]-1);
preorder(root[left][right]+1,right);
}
int main(){
int n,i;
memset(f,0,sizeof(f));
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d",&a[i]);
printf("%lld\n",dfs(1,n));
preorder(1,n);
return 0;
}
2.//P1273 有线电视网
//花了些时间,弄明白了样例的输入输出
//如何转化为算法,还没有眉目
//http://blog.csdn.net/hehe_54321/article/details/75368187此文代码写得不错
//ans[i][j]表示第i个结点以下共j个用户观看时最大的赚钱量
//(仍然没有想到)ans[u][i]=max{ans[u][i-j]+ans[v][j]-w}
//具体解释:
/*
ans[i][j][k]表示第i个结点以下前k个子结点中有j个用户观看时最大的赚钱量
ye[v]为v及以下叶节点数量
则对于边(u,v,w),ans[i][j][k]=max{ans[i][j-p][k-1]+ans[v][p][ye[v]]-w}(0<=p<=j,1<=j<=Σ(t属于前k个子结点的编号)ye[t])
省去k一维,则需要j从大到小循环:
ans[i][j]=max{ans[i][j-p]+ans[v][p]-w}(0<=p<=j,1<=j<=Σ(t属于前k个子结点)ye[t])
*/
/*
f(i, j),表示子树i转播给j个用户的最大收益值
这题可以看作是树上的分组背包,每个子树看作是一组物品,这一组物品可以取1个,2个...j个
然后就是套用分组背包的算法了
*/
//程序有两个地方比较难理解:
//1、如何保证在取数过程中,叶结点无重复,如f[i][i-j]中的叶结点 f[v][j]中的叶结点不重复
//2、for(i=ye[u];i>0;i--)正确 for(i=1;i<=ye[u];i++)错误
//针对样例1,列出动态规划过程,能说明上述问题
//for(i=ye[u];i>0;i--)正确 过程如下:
f[1][1]=max(f[1][1],f[1][1]+f[5][0]-3)
f[1][1]=max(f[1][1],f[1][0]+f[5][1]-3) 1->5 取一个 最大值
f[2][1]=max(f[2][1],f[2][1]+f[4][0]-3)
f[2][1]=max(f[2][1],f[2][0]+f[4][1]-3) 2->4 取一个 最大值
f[2][2]=max(f[2][2],f[2][2]+f[3][0]-2)
f[2][2]=max(f[2][2],f[2][1]+f[3][1]-2)
f[2][2]=max(f[2][2],f[2][0]+f[3][2]-2) 2->4 2->3 取两个 最大值
f[2][1]=max(f[2][1],f[2][1]+f[3][0]-2)
f[2][1]=max(f[2][1],f[2][0]+f[3][1]-2) 2->4 2->3 取一个 最大值
f[1][3]=max(f[1][3],f[1][3]+f[2][0]-2)
f[1][3]=max(f[1][3],f[1][2]+f[2][1]-2)
f[1][3]=max(f[1][3],f[1][1]+f[2][2]-2)
f[1][3]=max(f[1][3],f[1][0]+f[2][3]-2) 1->5 1->4 1->3 取三个 最大值
f[1][2]=max(f[1][2],f[1][2]+f[2][0]-2)
f[1][2]=max(f[1][2],f[1][1]+f[2][1]-2)
f[1][2]=max(f[1][2],f[1][0]+f[2][2]-2) 1->5 1->4 1->3 取两个 最大值
f[1][1]=max(f[1][1],f[1][1]+f[2][0]-2)
f[1][1]=max(f[1][1],f[1][0]+f[2][1]-2) 1->5 1->4 1->3 取一个 最大值
//for(i=1;i<=ye[u];i++)错误 过程如下:
f[1][1]=max(f[1][1],f[1][1]+f[5][0]-3)
f[1][1]=max(f[1][1],f[1][0]+f[5][1]-3) 1->5 取一个 最大值
f[2][1]=max(f[2][1],f[2][1]+f[4][0]-3)
f[2][1]=max(f[2][1],f[2][0]+f[4][1]-3) 2->4 取一个 最大值
f[2][1]=max(f[2][1],f[2][1]+f[3][0]-2)
f[2][1]=max(f[2][1],f[2][0]+f[3][1]-2) 2->4 2->3 取一个 最大值
f[2][2]=max(f[2][2],f[2][2]+f[3][0]-2)
f[2][2]=max(f[2][2],f[2][1]+f[3][1]-2)
f[2][2]=max(f[2][2],f[2][0]+f[3][2]-2) 2->4 2->3 取两个 最大值
f[1][1]=max(f[1][1],f[1][1]+f[2][0]-2)
f[1][1]=max(f[1][1],f[1][0]+f[2][1]-2) 1->5 1->4 1->3 取一个 最大值
f[1][2]=max(f[1][2],f[1][2]+f[2][0]-2)
f[1][2]=max(f[1][2],f[1][1]+f[2][1]-2)
//此处有问题 f[1][1]可能是1->4 故f[1][2]有可能取成 1->4 1->4 错误从此处开始
f[1][2]=max(f[1][2],f[1][0]+f[2][2]-2) 1->5 1->4 1->3 取两个 最大值
f[1][3]=max(f[1][3],f[1][3]+f[2][0]-2)
f[1][3]=max(f[1][3],f[1][2]+f[2][1]-2)
f[1][3]=max(f[1][3],f[1][1]+f[2][2]-2)
f[1][3]=max(f[1][3],f[1][0]+f[2][3]-2) 1->5 1->4 1->3 取三个 最大值
//分析的过程中,同时将上述的两个顾虑问题解决。
#include <stdio.h>
#include <string.h>
#define INF 999999
int head[3100],cnt=0,ye[3100],f[3100][3100];//f[i][j] i节点及以下共j个用户的最大收益 因收益有正有负,故初始化为绝对值比较大的负数
struct node{//邻接表
int to,next,c;
}e[3100];//有向图
void addedge(int u,int v,int c){
cnt++,e[cnt].to=v,e[cnt].c=c,e[cnt].next=head[u],head[u]=cnt;
}
int max(int a,int b){
return a>b?a:b;
}
void dfs(int u){
int v,b,i,j,c;//b边
b=head[u];
while(b){
v=e[b].to,c=e[b].c;
dfs(v);
ye[u]+=ye[v];
for(i=ye[u];i>=1;i--)
for(j=0;j<=i;j++)
f[u][i]=max(f[u][i],f[u][i-j]+f[v][j]-c);//1 此处写成 f[u][j]=max(f[i][j],f[u][i-j]+f[v][j]-c);
b=e[b].next;
}
}
int main(){
int n,m,i,j,p,k,a,c,ans=-INF;
memset(head,0,sizeof(head));
memset(ye,0,sizeof(ye));
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
f[i][j]=-INF;
for(i=1;i<=n;i++)
f[i][0]=0;//取0个,值为0
p=n-m;
for(i=1;i<=p;i++){
scanf("%d",&k);
for(j=1;j<=k;j++){
scanf("%d%d",&a,&c);
addedge(i,a,c);
}
}
for(i=p+1;i<=n;i++){
scanf("%d",&c);
f[i][1]=c,ye[i]=1;
}
dfs(1);
for(i=ye[1];i>=1;i--){
ans=i;
if(f[1][i]>=0)break;
}
printf("%d\n",ans);
return 0;
}
3.//P1156 垃圾陷阱
//http://www.cnblogs.com/Renyi-Fan/p/7443073.html此文介绍得不错,摘抄如下:
//分析:
//这题是类背包问题的动态规划。
//基本思路是用一个二维数组来存当前高度的生命
//状态决策就是吃和不吃
//这里用bool数组表示存活与否
//a[k].f表示吃了第k件物品恢复的生命值
//假如能吃 f[i][j+a[k].f]=true;
//a[k].h表示用了第k件物品能堆的高度
//假如能用 f[i+a[k].h][j]=true;
//初始状态f[0][10],最开始能存活10分钟
//老外的题目,没说明,就表明输入未必是按时间顺序,故需要排序。
//f[i][j] i表示高度,j表示存活时间,若i高度j时间能存活,则值为1,否则为0
//样例通过,提交,测试点2-3,5-11RE,应该是数组的范围开太小了,重读了一遍题目,发现理解有误 int f[25*100+100][1000+10];//4 此处写成 int f[25+5][1000+10];
//提交,测试点9WA
//查了https://www.luogu.org/discuss/show?postid=6676摘抄如下:
//我的那个点输出的是1000 而答案2900多 ,我是数组开了1000,超过就默认为1000
//重新读题,发现T (0 < T <= 1000) F (1 <= F <= 30) 持续10小时的能量
//最长时间计算10+30*100=3010开得大一些3100,修改,提交AC 2017-9-2 21:15
//该题有两个难点:测试点10,测试点9 即int f[100+50][3100] 开成100+50 3100
//测试点10,开成100+50 深度为D(2<=D<=100)英尺,每个垃圾堆放的高度h(1<=h<=25),跳出井时的最大值估算99+25=124 ,多给些余量 100+50,测试点10 AC
//测试点9,开成3100而不是1000+10 , 重新读题,发现T (0 < T <= 1000) F (1 <= F <= 30) G (1 <= G <= 100) 持续10小时的能量, 最长时间计算10+30*100=3010开得大一些3100 测试点9 AC
#include <stdio.h>
#include <string.h>
struct node{
int t,f,h;
}a[100+10],tmp;
int f[100+50][3100];//6此处写成 int f[100+50][1000+10]; //重新读题,发现T (0 < T <= 1000) F (1 <= F <= 30) 持续10小时的能量 //最长时间计算10+30*100=3010开得大一些3100 || 最大值估算99+25=124 修改后测试点10 AC ||5此处写成int f[100+10][1000+10];测试点10RE 4 此处写成 int f[25+5][1000+10];
int main(){
int d,g,i,j,s=10,k;//2 将s初始化为s=0 s总持续时间
memset(f,0,sizeof(f));
scanf("%d%d",&d,&g);
for(i=1;i<=g;i++){
scanf("%d%d%d",&a[i].t,&a[i].f,&a[i].h);
s+=a[i].f;
}
f[0][10]=1;
for(i=1;i<=g;i++)//冒泡排序,按a[].t自小到大排序
for(j=i+1;j<=g;j++)
if(a[i].t>a[j].t){
tmp=a[i];
a[i]=a[j];
a[j]=tmp;
}
for(k=1;k<=g;k++)
for(i=d-1;i>=0;i--)//i不从d开始,是为了不把程序写复杂,详见下面程序
for(j=s;j>=0;j--)
if(f[i][j]&&a[k].t<=j){//3写成if(f[i][j])//存活
f[i+a[k].h][j]=1;//可以垫高
if(i+a[k].h>=d){
printf("%d\n",a[k].t);
return 0;
}
f[i][j+a[k].f]=1;//1 位置放错,将其错放在if之外//可以吃
}
for(i=s;i>=1;i--)
if(f[0][i]){
printf("%d\n",i);
break;
}
return 0;
}
4.//P1169 [ZJOI2007]棋盘制作
//http://blog.csdn.net/Never_See/article/details/71307772此文图文并茂,介绍得不错,摘抄如下:
我们可以先转化一下
为了方便理解这里用一个比较特殊的图
因为是要求相邻的不同
那么这样看
我们把红色区域所有的数值0变为1,1变为0
就变成了这个样子
这时候我们原本是需要相邻点值不同,但现在可以直接是当做相邻的点相同
可以这样做是与我们选取改变的点有关的
我们选取改变的点都是尽可能相邻且不缺少的
或者从左上往右下看,看做从左上角的点出发,每一个与其相邻的点都要不同,那就把它们的权值改变一下,然后再从这些相邻的点出发,这些点的集合称为S,那么所有与S相邻的点权值都要不同,但因为S里面的点权都已经改变过了所以这些新的相邻点就不用改变,然后再看这些新的相邻点,更新的相邻点又需要改变……最后就变成了这样一个图



所以问题就变成了求有障碍点的极大化子矩阵
第一问可以DP
用f[i][j]表示以点(i,j)为正方形矩阵的右下角的点时的最大边长
if( A[i][j]!=A[i-1][j-1] )f[i][j] = 1;
else f[i][j] = min( min( l[i][j],Up[i][j] ),f[i-1][j-1]+1 );- 1
- 2
- 1
- 2
Up[i][j]表示(i,j)往上有多少个连续相同,l[i][j]表示(i,j)往左有多少个连续相同
A[i][j]表示(i,j)的值
第二问用悬线法
同样Up[i][j]表示(i,j)往上有多少个连续相同,A[i][j]表示(i,j)的值
对于(i,j)如果Up[i−1][j]>=Up[i][j]也就是说(i−1,j)要比(i,j)高,那么我们计算以(i,j)为底边中的一个点的时候可以得到的最大子矩阵,然后用这种方法不断的扩充这个矩阵的左端点和右端点直到到边界或不满足条件(即Up值不满足上述要求)时为止
既然知道了以(i,j)为底边一点的最大子矩阵的左端点右端点和上端点那么我们可以求出所有这样的子矩阵的面积然后取最大就可以了
当然可以用单调栈或其他方法
这里不加阐述
//P1169 [ZJOI2007]棋盘制作
//http://blog.csdn.net/Never_See/article/details/71307772此文图文并茂,介绍得不错
//悬线法 https://wenku.baidu.com/view/0d787294dd88d0d233d46a96.html 此文介绍得不错,图文并茂,悬线法有了初步了解
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1169 作者: Tgotp 更新时间: 2017-06-24 14:12 代码写得不错
//按自己理解,编码,样例通过,提交WA //1 此处写成 scanf("%d%d",&a[i][j]);造成m=0,查了会
//造了一组数据,找到了问题所在
//输入
//3 3
//1 1 1
//1 0 1
//1 1 1
//输出
//1 3
//再次提交WA //2 漏了该功能
//再次修改,提交AC //3 漏了该句 2017-9-11 21:40
#include <stdio.h>
#define maxn 2010
int a[maxn][maxn],up[maxn][maxn],left[maxn][maxn],right[maxn][maxn];//up改点到上端的最大距离 left改点到左端的最大距离 right改点到右端的最大距离
int min(int a,int b){
return a>b?b:a;
}
int max(int a,int b){
return a>b?a:b;
}
int main(){
int n,m,i,j,ans1=0,ans2=0;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
scanf("%d",&a[i][j]);//1 此处写成 scanf("%d%d",&a[i][j]);造成m=0,查了会
for(j=1;j<=m;j++)//初始化
up[1][j]=1;
for(i=1;i<=n;i++)
left[i][1]=1;
for(i=1;i<=n;i++)
right[i][m]=1;
for(i=2;i<=n;i++)
for(j=1;j<=m;j++)
if(a[i][j]!=a[i-1][j])
up[i][j]=up[i-1][j]+1;
else
up[i][j]=1;
for(j=2;j<=m;j++)
for(i=1;i<=n;i++)
if(a[i][j]!=a[i][j-1])
left[i][j]=left[i][j-1]+1;
else
left[i][j]=1;
for(j=m-1;j>=1;j--)
for(i=1;i<=n;i++)
if(a[i][j]!=a[i][j+1])
right[i][j]=right[i][j+1]+1;
else
right[i][j]=1;
for(i=2;i<=n;i++)//2 漏了该功能
for(j=1;j<=m;j++)
if(a[i][j]!=a[i-1][j]){//3 漏了该句
left[i][j]=min(left[i][j],left[i-1][j]);
right[i][j]=min(right[i][j],right[i-1][j]);
}
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
ans1=max(ans1,min(up[i][j],left[i][j]+right[i][j]-1));
for(i=1;i<=n;i++)
for(j=1;j<=m;j++)
ans2=max(ans2,up[i][j]*(left[i][j]+right[i][j]-1));
printf("%d\n",ans1*ans1);
printf("%d\n",ans2);
return 0;
}
5.
P2467 [SDOI2010]地精部落
1.该题难度挺大的,题解都很难看懂。
2.http://blog.csdn.net/mrazer/article/details/53426415?locationNum=12&fps=1此博文写得不错,摘抄如下,并加入自己的理解:
以样例1为例
1324 1423 2314 2413 2143
4231 4132 3241 3142 3412
引理一:一个抖动序列的连续子序列(≈一个数列的子串?)仍然是抖动序列。
证明:根据抖动序列的定义即可得证。。。
以 1324 为例:132 324 仍是抖动序列
引理二:若一个抖动排列中x与x+1不相邻,那么交换x与x+1,序列仍然是抖动序列。
证明:(请自己在脑海中感性证明)由于x与x+1不相邻,所以与这两个元素相邻的最多4个元素∈[1,x−1]|[x+2,max],所以易知差距至少为2,经过一些简单的分情况讨论后考虑与相邻元素的大小关系可以发现原谷仍谷,而原峰仍峰,所以命题得证。
以 1324 1423 为例:1423 即是由 1324 交换 3 4 而来的
以 2143 为例:2143 因 2 1 相邻 4 3 相邻,故无法生成新的抖动序列
引理三:若使一个抖动排列中大于等于x的元素全部加1,得到的序列仍为抖动序列。
证明:这个可以考虑归纳法证明,对x进行归纳,x=1时相当于把整体加1,大小关系不变所以基础显然,把x加1,仍然是由于差距至少为2,分一下情况就可以发现大小关系仍然合法,命题得证(感觉应该不算很难,大概写写画画就出来了,所以写得简略了一点)
引理四:一个[1,X]的抖动序列一定可以对应到[Y−X+1,Y]的一个抖动序列。
证明:用Y−x+1替换掉x就好了,并且易知如果采用这种方法的话这是一一对应的,并且峰谷交换了。
该引理要表达的意思是,用n+1减去抖动序列每项,可以得到新的抖动序列
以 1324 4231 为例:5 减去 1324 每项可得 4231
有了上述几个引理我们就可以愉快地DP了!
设f[i][j]为[1,i]的排列中开头第一个位置的元素(其实当然也可以表示是结尾啦~)恰为j且j为峰(即第一个数j大于第二个数)的抖动排列的方案数。既然已经确定了第一个数,那么不妨考虑第二个数。
(1)如果第二个数不是j−1。那么根据引理二,我们总可以交换当前第一个元素j与和它不相邻的元素j−1而保持序列仍是抖动序列,并且由于只是进行了交换,所以是一一对应的。这一部分的方案数是f[i][j−1]。
(2)如果第二个数是j−1。那么去掉第一个数j后,[1,i]还剩下[1,j−1]|[j+1,i],根据引理三,我们只需要保持从第二个位置开始的序列是一个排列范围是[1,i−1]的抖动序列然后把其中[j,i−1]的这一部分整体加1就得到一个[1,i]的抖动序列了(并且也可以知道这一部分是一一对应的),第一个数j是峰,那么第二个数j−1就应该是谷咯,可我们的状态里似乎并没有谷?使用引理四!这时再结合上文,我们可以得到这一部分的方案数其实就是f[i−1][(i−1)−(j−1)+1]=f[i−1][i−j+1](其中第一维是用了上文的对应,而第二维是利用了引理四中的对应,所以整体也是一一对应的)。
该点理解:1 2 3 ... j-2 j-1 j+1 j+2 ...i 根据数据的离散化 [j+1,i] 区间整体 -1 可得1 2 3 ... j-2 j-1 j j+1 ...i-1即变成[1,i-1]排列范围。
j峰 j-1谷 故 接下来是一个上升序列
好了,这上面两种情况已经包含了第二个位置上的数的所有情况,并且都是一一对应的,根据动态规划与计数问题的归纳证明,我们成功地得到了正确的转移方程:f[i][j]=f[i][j−1]+f[i−1][i−j+1]!
最终ans=(∑i=1nf[n][i])∗2(其实开头元素为1且是峰的根本不存在好吧,所以我们当然可以直接不转移它啦~)(记得特殊处理一下n=1的情况),最后那个∗2是什么意思呢?很简单,因为我们状态里只有第一个数是峰的情况,根据引理四中的一一对应与峰谷交换,我们∗2就可以得到第一个数是谷的情况的方案数了。
当然接下来我们要做的就是简单的改成滚动数组就可应对内存的问题了。
以下为AC代码,2017-9-14 21:45
#include <stdio.h>
#include <string.h>
int f[2][4210];//滚动数组,技巧性高。 f[0] f[1]交替使用
int main(){
int now=0,i,j,n,ans=0,mod;
memset(f,0,sizeof(f));
scanf("%d%d",&n,&mod);
f[now][2]=1;//即f[2][2]=1 "2 1" 一维数组表示
for(i=3;i<=n;i++){
now^=1;
for(j=2;j<=i;j++)
f[now][j]=(f[now][j-1]+f[now^1][i-j+1])%mod;//f[i][j]=f[i][j-1]+f[i-1][i-j+1]故前两项用now 最后一项用now^1
}
for(i=2;i<=n;i++)
ans=(ans+f[now][i])%mod;
ans=(ans*2)%mod;
printf("%d\n",ans);
return 0;
}
2017-9-14 21:45 AC该单元
数论
1.2.
3.//P1372 又是毕业季I
//简单模拟了一下:4 2 即4/2=2 2 4最大公约数2
//100 10 100/10=10 10 20 30 40...100最大公约数10
//1000 2 1000/2=500 500 1000 最大公约数500
//该题看看挺吓人,但题中做了提示:PS:一个数的最大公约数即本身。
#include <stdio.h>
int main(){
int n,k;
scanf("%d%d",&n,&k);
printf("%d\n",n/k);
return 0;
}
4.
5.
洛谷 P1134 阶乘问题
//P1134 阶乘问题
//样例花了些时间,一直不明白,12的阶乘最右边的非零位为6
//12! = 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 x 9 x 10 x 11 x 12 = 479,001,600
//非零位,不是4 7 9 1 6共5位吗?反复读题,好半天,才弄明白非零位6是指600中的6
//本题有思路了,对10取余
//编写代码稍微费了些周折,但很快编好,样例通过
//测试了50000000,感觉介于超时与不超时之间,提交测试点4,5,7WA
//找不到测试数据,那么只能自己测试,发现20 输出8 实际4
//1! 1 2! 2 3! 6 4! 4 5! 2 6! 2 7! 4 8! 2 9! 8 10! 8 11! 8 12! 6 13! 8 14! 2 15! 8 16! 8 17! 6 18! 8 19! 2 20! 4实际
//1! 1 2! 2 3! 6 4! 4 5! 2 6! 2 7! 4 8! 2 9! 8 10! 8 11! 8 12! 6 13! 8 14! 2 15! 1 16! 6 17! 2 18! 6 19! 4 20! 8程序
//15!开始出问题,之后的数据全受影响。感觉不断的会有进位。乘的过程中,不断的会出现0.很难处理啊!算法应该要有极大的改变。
//搜索网络,原理角度,该篇文章不错,http://blog.csdn.NET/chai_jing/article/details/53132363。摘抄如下:
//【分析】一遇到数学题就怂 方法吧 把2 5拿出来凑成一个10 然后扔了= = 手玩一下10的阶乘发现只有2 5能凑成十 然后质因数2的数量貌似一定比5多的样子
//然后就把2全部拿出来 拿一个cnt加一 同时把5全部拿出来 拿一个cnt减一
//直接在最开始加上%10好像可以更快些= =(那是不是%100更快?不知道)最后必然是2会多出来一些 然后2的乘方是可以找规律的 打表即可
//代码角度,该篇文章比较清晰,http://blog.csdn.Net/rlt1296/article/details/53070283
//提交,测试点7 TLE
//进行优化:2^1=2 2^2=4 2^3=8 2^4=16 2^5=32 2^6=64 2^7=128 2^8=256
附上AC代码:
#include <stdio.h>
int main(){
int n,i,j,ans=1,cnt=0,a[4]={6,2,4,8};
scanf("%d",&n);
for(i=1;i<=n;i++){
j=i;
while(j%2==0){
j/=2;
cnt++;
}
while(j%5==0){
j/=5;
cnt--;
}
ans*=j;
ans%=10;
}
ans*=a[cnt%4];//cnt个2的处理
ans%=10;
printf("%d\n",ans);
return 0;
}
附上测试点7 TLE代码:
#include <stdio.h>
int main(){
int n,i,j,ans=1,cnt=0;
scanf("%d",&n);
for(i=1;i<=n;i++){
j=i;
while(j%2==0){
j/=2;
cnt++;
}
while(j%5==0){
j/=5;
cnt--;
}
ans*=j;
ans%=10;
}
for(i=1;i<=cnt;i++){
ans*=2;
ans%=10;
}
printf("%d\n",ans);
return 0;
}
附上测试点4,5,7WA代码:
#include <stdio.h>int main(){
int n,i,j,ans=1;
scanf("%d",&n);
for(i=1;i<=n;i++){
j=i;
while(j%10==0)
j/=10;
j%=10;
printf("j=%d ",j);
ans*=j;
while(ans%10==0)
ans/=10;
ans%=10;
printf("ans=%d \n",ans);
}
printf("%d\n",ans);
return 0;
}
2017-5-20 11:21
6.
7.//p1313 计算系数
NOIP 2011 提高组 复赛 day2 factor 计算系数
1.只看标题,就可以猜到,这是一个数学题。
2.准备好稿纸,一看,学过的二项式定理用上了,系数C(k,n)*a^n*b^m。
3.本题,一不小心,数据就会越界,取余必不可少,怎么取余才不会影响结果,看来要好好学习初等数论。
4.按自己理解,乘之前,先将系数全部取余,再进行乘运算,但很遗憾,提交0分,马上按照最后结果才取余,提交20分,这样才稍微平复了心情。
5.翻看书籍《信息学奥赛之数学一本通》,取余发现没有除运算,马上想到,“除”处理过程中有问题,若无整除,保留原数,若整除,值改变为商。信心满满,提交估计50分以上。提交还是20分。
6.想尽办法,没辙。取余遇到除运算,没辙。上网搜索。
7.看了http://blog.sina.com.cn/s/blog_606a23dd010128lo.html这篇文章,发现还是二项式,只是采用杨辉三角的表达形式,递推(或是动态规划DP),有了思路,自个编。跟本人是两种截然不同的思路,虽然都是二项式。
这道题虽然出现在提高组,却并不一定只能用高中知识解决。
其实,这道题可以用递推解决。
设f[i][j]为(ax+by)^i的x^j*y^(n-j)的系数。显然可以得到公式:
f[i][j]=(f[i-1][j-1]*a+f[i-1][j]*b)%10007。
时间复杂度O(N^2)
8.编写过程中,发现memset(d,0,sizeof(d));有效,memset(d,-1,sizeof(d));有效,memset(d,1,sizeof(d));无效。
9.经过一番编码,提交AC。
10.此题收获,取余一定要学,学习初等数论。
附上AC代码,编译环境Dev-C++4.9.9.2
//2011 factor2 计算系数
//递推公式:d[n][m]=d[n-1][m-1]+d[n-1][m];动态规划
#include <stdio.h>
#include <string.h>
#define mod 10007
int d[1000+10][1000+10];
int main(){
int a,b,k,n,m;
int i,j;
int ans=1;
scanf("%d%d%d%d%d",&a,&b,&k,&n,&m);
for(i=0;i<=k;i++){//初始化
d[i][0]=1;
d[i][i]=1;
}
//i从0开始,j从0开始
for(i=2;i<=k;i++)//行
for(j=1;j<i;j++){//列
d[i][j]=(d[i-1][j-1]+d[i-1][j])%mod;
}
for(i=1;i<=n;i++){
a%=mod;
ans*=a;
ans%=mod;
}
for(i=1;i<=m;i++){
b%=mod;
ans*=b;
ans%=mod;
}
ans*=d[k][n];
ans%=mod;
printf("%d\n",ans);
return 0;
}
附上20分代码,编译环境Dev-C++4.9.9.2
//2011 factor#include <stdio.h>
#define mod 10007
int main(){
int a,b,k,n,m;
long long ans;
int i,j;
int result;
scanf("%d%d%d%d",&a,&b,&k,&n,&m);
ans=1;
for(i=1;i<=n;i++){
//a%=mod;
ans*=a;
//ans%=mod;
}
for(i=1;i<=m;i++){
//b%=mod;
ans*=b;
//ans%=mod;
}
for(i=0;i<n;i++){
ans*=(k-i);
//ans%=mod;
}
for(i=n;i>0;i--){
ans/=i;//此处写成了ans/=n,查了会
}
ans%=mod;
result=ans;
printf("%d\n",result);
return 0;
}
博弈论
1.P1199 三国游戏
NOIP 2010 普及组 复赛 sanguo 三国游戏
1.扫到他人讨论,取第2大值,且小涵必胜。
2.编码,样例通过,提交,只通过了测试点1,6.
3.看了题解,发现是武将配对中,找出配对的第2大值。
4.看来他人评论不能看,还是自己想最重要。
5.该题基本思路如下:
模拟样例,猜测应是武将配对中,找出同一配对中的第2序列的最大值。
证明如下:i,j配对最大值。小涵选i,电脑选j,i与j的最大值小涵,电脑均不可以取到,理想情况,i取到第2大值,
j取到对应的第2大值,只要i取到的第2大值,大于,j取到的第2大值,故,取配对中的第2大值的最大值。
小涵必胜。
6.该题学会了用冒泡思路,找最大值的同时,找第2大值。算是收获。
//P1199 三国游戏#include <stdio.h>
#include <string.h>
int a[500+10][500+10];
int main(){
int n,i,j,v,max1=-1,max2=-1,ans=-1;//max1第一大,max2第二大
memset(a,-1,sizeof(a));
scanf("%d",&n);
for(i=1;i<=n;i++)
for(j=i+1;j<=n;j++){
scanf("%d",&v);
a[i][j]=v;
a[j][i]=v;
}
for(i=1;i<=n;i++){
max1=-1,max2=-1;
for(j=1;j<=n;j++)
if(a[i][j]>max1){
max2=max1;//1顺序写颠倒了,此处写成 max1=a[i][j];
max1=a[i][j];//1顺序写颠倒了,此处写成 max2=max1;
}else if(a[i][j]>max2)
max2=a[i][j];
ans=ans<max2?max2:ans;
}
printf("1\n%d\n",ans);
}
2.
3.//P1290 欧几里德的游戏
//没什么感觉,查阅网络,总体说得太抽象。
//翻看《信息学奥赛之数学一本通》P12有详解,花了些时间看懂了。
//总归要想,没有经过一段时间训练,还真不知到怎么想。
//思路是,先模拟,找规律,模拟游戏,进行决策。
//中间遇到m/n==1不可怕,可怕的是一开始就遇到m/n==1
//最关键是首先拿到m/n>1的人,肯定赢。
#include <stdio.h>
void swap(int *a,int *b){
int t;
t=*a;
*a=*b;
*b=t;
}
int main(){
int i,j,c,m,n,f,t;
scanf("%d",&c);
for(i=1;i<=c;i++){
scanf("%d%d",&m,&n);
if(m<n)//要求得到的结果是m>n
swap(&m,&n);
f=1;
while(m/n==1&&m%n){//第一次就遇到m/n==1的情况
t=m%n;
m=n;
n=t;
f=-f;
}
if(f==1)
printf("Stan wins\n");
else
printf("Ollie wins\n");
}
return 0;
}
4.
图的遍历
1.P2661 信息传递
NOIP2015 提高组 复赛 day1 message 信息传递
1.弄懂样例是关键。发现题目中附带了说明,对样例1解释得非常好。
2.n<=200000,故纯模拟,O(n^2)超时,采用O(nlogn)算法。
3.该题感觉得60分还是挺容易的,但估计得100分的算法要比60分有翻天覆地的变化。
4.用普通模拟,编着编着感觉不对劲,翻看他人做法。
5.这篇文章写得不错,https://wenku.baidu.com/view/0733a6d5a417866fb84a8eba.html
6.基本思路:将入度为0的点删除,因不存在自环,环套环,从题意中可推出,遍历环,数出最小值。
//仔细阅读题意,如下问题都能解决。//这道题没有自环没有环套环。所有的点和边都是单纯的。。。
//从每个点开始走,发现环了就更新最小长度。因为图没有分叉,所以每个点最多在一个环里,因此可以判重。复杂度O(n)是显然的
#include <stdio.h>
#include <string.h>
int f[200000+100],in[200000+100],vis[200000+100],q[200000+100];
int main(){
int n,i,j,head,tail,ans,x;
memset(vis,0,sizeof(vis));
memset(in,0,sizeof(in));
scanf("%d",&n);
ans=n;
for(i=1;i<=n;i++){
scanf("%d",&f[i]);
in[f[i]]++;//入度
}
for(i=1;i<=n;i++){//处理入度为0
if(in[i]==0&&vis[i]==0){
head=tail=0;
vis[i]=1;
q[tail]=i;
tail++;
while(head<tail){
j=q[head];
in[f[j]]--;
if(in[f[j]]==0){
vis[f[j]]=1;
q[tail]=f[j];
tail++;
}
head++;
}
}
}
for(i=1;i<=n;i++){//找最小的环
if(vis[i]==0){
vis[i]=1;
x=1;
j=f[i];
while(vis[j]==0){
vis[j]=1;
x++;
j=f[j];
}
}
if(x<ans)
ans=x;
}
printf("%d\n",ans);
return 0;
}
2.//P1330 封锁阳光大学
//题目通过样例1,2的模拟,很快弄懂。
//该题考图的什么知识点呢?
//http://www.bubuko.com/infodetail-2092883.html此文思路写得不错
//http://blog.csdn.net/rlt1296/article/details/51893429此文代码写得比较短
//http://blog.csdn.net/ypxrain/article/details/54583727此文代码也写得比较短
//http://blog.csdn.net/cax1165/article/details/52315089思路不错,摘抄如下:
//思路:
//e[i][0]是记录关于点i的边数,e[i][j]是关于i点的第j条边连向哪个点。
//然后开始DFS,从源点开始拓展,将源点染色为1,与源点相连的点(下面称为二层点,以此类推)染色为2,把与二层点相连的染色为1,与三层点相连的点染色为2,就是不断的121212……当然,这个时候,如果你发现,从一个被染色为1的点拓展,发现一个颜色也为1的点,这就无法染色,也就是题目中的Impossible。开变量累计图中你染色为1的点和染色为2的点的个数,选择小的累加到ans里面。
//!注意,这里的图不是全连通的。每个连通图分开染色,分开累加,而不是一次性地输出所有连通图中的色1和色2的较小值
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#define maxn 10000+100
int n,m,e[maxn][100],f[maxn],tot_1,tot_2,ans=0;//e[i][0]是记录关于点i的边数,e[i][j]是关于i点的第j条边连向哪个点。f[i]表示该点颜色值
void color(int u){
int i;
for(i=1;i<=e[u][0];i++){
if(f[u]==f[e[u][i]]){
printf("Impossible\n");
exit(0);//退出程序
}
if(f[e[u][i]]==0){
f[e[u][i]]=3-f[u];
if(f[e[u][i]]==1)
tot_1++;
else
tot_2++;
color(e[u][i]);//2 放错位置了,应在if之内,而非if之外
}
}
}
int main(){
int i,u,v;
scanf("%d%d",&n,&m);
memset(f,0,sizeof(f));
for(i=1;i<=n;i++)//1忘记初始化了
e[i][0]=0;//1忘记初始化了
for(i=1;i<=m;i++){//无向图
scanf("%d%d",&u,&v);
e[u][++e[u][0]]=v;
e[v][++e[v][0]]=u;
}
for(i=1;i<=n;i++)
if(f[i]==0){
f[i]=1;
tot_1=1;
tot_2=0;
color(i);
ans+=tot_1>tot_2?tot_2:tot_1;//tot_1,tot_2中最小值
}
printf("%d\n",ans);
return 0;
}
2017-5-30 23:20AC
3.//P1341 无序字母对
//用图来连接字符,字符作为节点,关系作为边,发现是无向图
//没什么感觉,翻看他人代码,发现欧拉回路字样,明白,要学新东西了。
//欧拉道路 特征 除了起点和终点外,其他点的度数应该是偶数。
//通过研究ASCII表,弄明白了,大写字母字典序在小写字母字典序之前。
//关于n的规模,这篇文章说得好http://blog.csdn.net/sinat_34550050/article/details/53088654
//n的规模应该是A(26,2)=26*25=650.
//就程序角度而言,这三篇文章写得不错:
//http://blog.csdn.net/senyelicone/article/details/51913983
//http://www.cnblogs.com/SilverNebula/p/5678975.html
//http://blog.csdn.net/Rlt1296/article/details/51893069
//代码经过优化再优化,共41行. 提交,测试点6,7,8,9,10WA
//进入递归函数,马上打印,还是递归函数快结束时打印,困扰了很久,辛亏找到一组测试数据,进行分析
//10
//ab
//ac
//ad
//af
//bc
//cd
//cf
//de
//df
//ef
//清楚了递归函数中,打印位置不同,结果截然不同。
//程序中stack,top均是全局变量。最开始访问的元素,最迟被记录,在栈顶。
//递归函数中为什么要最后存储打印,而不是一开始就打印,解释如下:
//因按一般思路访问到最后一个元素过程中,有些元素还未访问过,故需折返,先将其他元素访问过,再访问最后的元素。
#include <stdio.h>
#include <string.h>
int e[58+10][58+10],stack[1000],top=-1;//stack[700]最后三个测试点WA,改成stack[1000],AC
int min(int u,int v){//找最小值
return u>v?v:u;
}
void euler(int u){
int i;
//printf("%c",u+'A');//很神奇的地方,此处打印 测试点6,7,8,9,10WA 解决不了,日后解决 ,跟踪了代码,有点感觉了,一杆子到不了底,只能采用迂回战术,故最后再打印。日后再回顾此问题,应会更清晰。
for(i=0;i<58;i++)
if(e[u][i]){
e[u][i]=e[i][u]=0;
euler(i);
}
top++;
stack[top]=u;
}
int main(){
int i,n,u,v,d[58+10],a[58+10],k=999999999;
char s[5];
memset(d,0,sizeof(d)),memset(e,0,sizeof(e)),memset(a,0,sizeof(a));
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%s",s);
u=s[0]-'A',v=s[1]-'A';
k=min(k,min(u,v));//找最小字典序
e[u][v]=e[v][u]=1;
d[u]++;//节点u的度
d[v]++;//节点v的度
}
for(i=0;i<58;i++)//Ascii表中,'A'-'Z'一共58个字符
if(d[i]%2==1){
a[0]++;//a[0]存储奇点个数
a[a[0]]=i;//a[a[0]]存储奇点位置
}
if(a[0]==0)//无奇点
euler(k);//从字典最小序开始遍历
else if(a[0]==2)//起点,终点两个奇点
euler(a[1]);
else{//无欧拉道路
printf("No Solution\n");
return 0;
}
while(top>=0){
printf("%c",stack[top]+'A');
top--;
}
printf("\n");
return 0;
}
该专题:2017-5-30 AC
最短路问题
1.//P1339 [USACO09OCT]热浪Heat Wave
//无向图
//邻接矩阵2500*2500占空间有点多,准备尝试邻接表
//Dijkstra 邻接表的写法,这篇文章写得不错 https://www.douban.com/note/296102336/
//很快编写好,样例通过,提交AC,一次性成功,代码写下来,竟然不用调试,难得。2017-6-16 21:26
//程序效率:耗时:159ms 内存:8535kb
#include <stdio.h>
#include <string.h>
#define INF 9999
struct node{
int to,next,w;
}e[6200*2+100];
int head[2500+100],cnt=0,vis[2500+100],d[2500+100];
void add(int u,int v,int w){//无向图
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt,e[cnt].w=w;//从头插入,head[u]指向节点u对应的边,cnt边,e[cnt].to,cnt边对应的终点,e[cnt].w,cnt边对应的权重w
cnt++,e[cnt].to=u,e[cnt].next=head[v],head[v]=cnt,e[cnt].w=w;
}
int main(){
int t,c,ts,te,i,j,k,u,v,w,min;
memset(head,0,sizeof(head));
memset(vis,0,sizeof(vis));
scanf("%d%d%d%d",&t,&c,&ts,&te);
for(i=1;i<=c;i++){
scanf("%d%d%d",&u,&v,&w);
add(u,v,w);
}
for(i=1;i<=t;i++)
d[i]=INF;
d[ts]=0;
for(i=1;i<=t;i++){//剩下t个点
u=0,min=INF;
for(j=1;j<=t;j++)
if(vis[j]==0&&d[j]<min){//找d[j]中的最小值
min=d[j];
u=j;
}
vis[u]=1;
k=head[u];//k是边
while(k!=0){//邻接表处理
v=e[k].to;
if(vis[v]==0&&d[u]+e[k].w<d[v])
d[v]=d[u]+e[k].w;
k=e[k].next;
}
}
printf("%d\n",d[te]);
return 0;
}
//P1339 [USACO09OCT]热浪Heat Wave
//准备试试SPFA算法,这篇文章介绍得不错http://blog.csdn.net/muxidreamtohit/article/details/7894298
//邻接表方式
//样例很快通过,提交,测试点3,7,8,10WA
//查出的问题还不少,主要有两处:vis[u]=0;//2 漏了此句
//if(vis[v]==0){//3 整个if语句写到上面if语句的外面,写错位置了 提交AC
#include <stdio.h>
#include <string.h>
#define INF 9999;
struct node{
int to,next,w;
}e[6200*2+100];
int q[2500+100],h,t,cnt=0,head[2500+100],vis[2500+10],d[2500+10];
void add(int u,int v,int w){//无向图,加入边,采用邻接表形式
cnt++,e[cnt].to=v,e[cnt].w=w,e[cnt].next=head[u],head[u]=cnt;
cnt++,e[cnt].to=u,e[cnt].w=w,e[cnt].next=head[v],head[v]=cnt;
}
int main(){
int t,c,ts,te,i,j,u,v,w,b;
memset(head,0,sizeof(head));
memset(vis,0,sizeof(vis));
scanf("%d%d%d%d",&t,&c,&ts,&te);
for(i=1;i<=c;i++){
scanf("%d%d%d",&u,&v,&w);
add(u,v,w);
}
for(i=1;i<=t;i++)
d[i]=INF;
d[ts]=0;
h=t=1;
q[t]=ts;
vis[ts]=1;
t++;
while(h<t){
u=q[h];
b=head[u];
while(b!=0){
v=e[b].to;
if(d[v]>d[u]+e[b].w){//1 此处写成 if(d[v]<d[u]+e[b].w)低级错误
d[v]=d[u]+e[b].w;
if(vis[v]==0){//3 整个if语句写到上面if语句的外面,写错位置了
vis[v]=1;
q[t]=v;
t++;
}
}
b=e[b].next;
}
vis[u]=0;//2 漏了此句
h++;
}
printf("%d\n",d[te]);
return 0;
}
2017-6-18 13:54 补充SPFA算法。
2.//P1462 通往奥格瑞玛的道路
//题意比较难懂:他所经过的所有城市中最多的一次收取的费用的最小值是多少。看了讨论,说意思是:即收取费用最大值的最小值.
//http://blog.csdn.net/chai_jing/article/details/53131979此文代码写得不错。
//http://www.cnblogs.com/lidaxin/p/4907277.html此文对减小时间复杂度有很大帮助
//该题要想AC,测试点9很关键,队列至少要开到 int q[10000*3+100],请注意,建议spfa算法,队列都开到 点的数量*10
//该题考点:spfa 快速排序 二分法
//对该题看法,题意表述不清,使人很难度题意,若出题人语言功底薄弱,建议,针对样例,进行详解。使读者尽可能明白题意。
#include <stdio.h>
#include <string.h>
#define INF 1000000009
struct node{
int to,next,w;
}e[50000*2+100];
int f[10000+100],cnt=0,head[10000+100],tmpf[10000+100],vis[10000+100],h,t,x,n;
long long d[10000+100];//2 int d[10000+100];
void quicksort(int left,int right){
int i=left,j=right,mid=tmpf[(left+right)/2],t;
while(i<=j){
while(tmpf[i]<mid)
i++;
while(tmpf[j]>mid)
j--;
if(i<=j){
t=tmpf[i];
tmpf[i]=tmpf[j];
tmpf[j]=t;
i++;
j--;
}
}
if(left<j)
quicksort(left,j);
if(i<right)
quicksort(i,right);
}
void add(int u,int v,int w){//无向图
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt,e[cnt].w=w;//1 漏了head[u]=cnt
cnt++,e[cnt].to=u,e[cnt].next=head[v],head[v]=cnt,e[cnt].w=w;////1 漏了head[v]=cnt
}
int spfa(int mid){//每进行一次spfa,需要将vis[],d[]进行一次初始化
int u,v,b,i;//b边
int q[10000*3+100],h=t=1;//6 int q[10000+100] 5 队列也要初始化
memset(vis,0,sizeof(vis));//4 初始化位置放错,放到主函数去了。
for(i=1;i<=n;i++)//4 初始化位置放错,放到主函数去了。
d[i]=INF;//4 初始化位置放错,放到主函数去了。
d[1]=0;//4 初始化位置放错,放到主函数去了。
h=t=1;
q[t]=1;
vis[1]=1;
t++;
while(h<t){
u=q[h];
b=head[u];
while(b!=0){
v=e[b].to;
if(f[v]>mid){
b=e[b].next;
continue;
}
if(d[v]>d[u]+e[b].w){
d[v]=d[u]+e[b].w;
if(vis[v]==0){
vis[v]=1;
q[t]=v;
t++;
}
}
b=e[b].next;
}
vis[u]=0;
h++;
}
if(d[n]<=x)return 1;
return 0;
}
int main(){
int m,a,b,c,i,j,u,v,w,left,right,mid;
memset(head,0,sizeof(head));
scanf("%d%d%d",&n,&m,&x);
for(i=1;i<=n;i++)
scanf("%d",&f[i]);
for(i=1;i<=m;i++){
scanf("%d%d%d",&u,&v,&w);
add(u,v,w);
}
memcpy(tmpf,f,sizeof(f));
quicksort(1,n);
left=1,right=n;//3 漏了left right的初始化
while(left<right){
mid=(left+right)/2;
if(spfa(tmpf[mid])==1)right=mid;
else left=mid+1;
}
if(spfa(tmpf[left])==0){
printf("AFK\n");
return 0;
}
printf("%d\n",tmpf[left]);
return 0;
}
2017-6-19
3.//P1346 电车
//一开始,觉得题目看不懂。
//但研究样例,画图,发现是有向图,确实是找最短路径。
//准备采用spfa算法。
//提交,测试点1-5WA,测试点8-10WA
//进行2 修改,提交,测试点1,3,8,9,10WA
//看了讨论,Ki可能等于0,没想法了。进行3 修改,提交,测试点1,3,8,9,10WA
//查错查了1小时,归根结底SPFA算法掌握不熟练。2017-6-19
//感谢http://www.codevs.cn,提交错误部分,能窥探到部分数据,很不错了,对解决问题有极大的帮助
#include <stdio.h>
#include <string.h>
#define INF 9999
int cnt=0,head[100+10],q[100*10+10],d[100+10],h,t,vis[100+10];
struct node{
int to,next,w;
}e[100*100+10];
void add(int u,int v,int w){
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt,e[cnt].w=w;
}
int main(){
int n,a,b,i,k,j,u,v,c;
memset(head,0,sizeof(head));
memset(vis,0,sizeof(vis));
scanf("%d%d%d",&n,&a,&b);
for(i=1;i<=n;i++){
scanf("%d",&k);
for(j=1;j<=k;j++){//3 请注意,Ki可能等于0
scanf("%d",&v);
if(j==1)
add(i,v,0);
else
add(i,v,1);//2 此处写成 add(i,v,j-1);
}
}
for(i=1;i<=n;i++)
d[i]=INF;
d[a]=0;
h=t=1;
q[t]=a;
t++;
vis[a]=1;
while(h<t){
u=q[h];
c=head[u];//边
while(c!=0){
v=e[c].to;
if(d[v]>d[u]+e[c].w){//4 此处写成 if(d[v]>d[u]+e[v].w)低级错误的低级错误,查了1个小时
d[v]=d[u]+e[c].w;//4 此处写成 d[v]=d[u]+e[v].w;低级错误的低级错误,查了1个小时
if(vis[v]==0){
vis[v]=1;
q[t]=v;
t++;
}
}
c=e[c].next;//1 低级错误,漏了该句
}
vis[u]=0;//4 此处写成 vis[v]=0;低级错误的低级错误,查了1个小时
h++;
}
if(d[b]==INF)
printf("-1\n");
else
printf("%d\n",d[b]);
return 0;
}
4.//P1119 灾后重建
//首先想到的是SPFA算法,但感觉会超时。
//翻看他人代码,发现floyd算法可以用得这么好,佩服,此文代码写得不错http://www.cnblogs.com/zbtrs/p/5795976.html
//样例很快通过,提交测试点1-3,测试点5,测试点7-10WA,洛谷上无任何测试数据,去codevs.cn看看
//t[n]=INF;//1 漏了初始化该句,查了半小时 要保证t[k]<=z能安全退出,若无该句,t[n]=0 循环无法退出
//2017-6-19 22:41
#include <stdio.h>
#define INF 100009
int main(){
int n,m,i,j,k=0,t[200+10],a[200+10][200+10],u,v,w,q,x,y,z;
scanf("%d%d",&n,&m);
for(i=0;i<n;i++)
scanf("%d",&t[i]);
for(i=0;i<n;i++)
for(j=0;j<n;j++)
if(i==j)
a[i][j]=0;
else
a[i][j]=INF;
for(i=1;i<=m;i++){
scanf("%d%d%d",&u,&v,&w);
a[u][v]=w,a[v][u]=w;//无向图
}
t[n]=INF;//1 漏了初始化该句,查了半小时 要保证t[k]<=z能安全退出,若无该句,t[n]=0
scanf("%d",&q);
while(q--){
scanf("%d%d%d",&x,&y,&z);
while(t[k]<=z){
for(i=0;i<n;i++)
for(j=0;j<n;j++)
if(a[i][j]>a[i][k]+a[k][j])
a[i][j]=a[i][k]+a[k][j];
k++;
}
if(t[x]>z||t[y]>z||a[x][y]==INF)
printf("-1\n");
else
printf("%d\n",a[x][y]);
}
return 0;
}
5.//P1144 最短路计数
//http://www.cnblogs.com/SilverNebula/p/5818766.html代码写得不错
//http://www.cnblogs.com/sssy/p/6874103.html代码写得可以
//SPFA算法,改进型。
//样例通过,一次性提交AC,难得。2017-6-20
#include <stdio.h>
#include <string.h>
#define INF 9999999
struct node{
int to,next;
}e[2000000*2+100];
int ans[1000000+100],d[1000000+100],cnt=0,head[1000000+100],q[1000000*3+100],h,t,vis[1000000+100];
void add(int u,int v){//无向图
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt;
cnt++,e[cnt].to=u,e[cnt].next=head[v],head[v]=cnt;
}
void spfa(){
int u,v,b;//u点 b边
d[1]=0;
ans[1]=1;
h=t=1;
q[t]=1;
t++;
vis[1]=1;
while(h<t){
u=q[h];
b=head[u];
while(b!=0){
v=e[b].to;
if(d[v]>d[u]+1){
d[v]=d[u]+1;
ans[v]=ans[u]%100003;
if(vis[v]==0){
vis[v]=1;
q[t]=v;
t++;
}
}else if(d[v]==d[u]+1)
ans[v]=(ans[v]+ans[u])%100003;
b=e[b].next;
}
vis[u]=0;
h++;
}
}
int main(){
int n,m,i,j,u,v;
memset(vis,0,sizeof(vis));
memset(head,0,sizeof(head));
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
d[i]=INF;
for(i=1;i<=m;i++){
scanf("%d%d",&u,&v);
add(u,v);
}
spfa();
for(i=1;i<=n;i++)
printf("%d\n",ans[i]);
return 0;
}
6.//P1522 牛的旅行 Cow Tours
//首先说明一点,翻译得很不好,还是看原版的比较好。
//http://blog.csdn.net/supersnow0622/article/details/9763979此文写得不错,摘抄如下:
//分析:首先要连在一起修路的这两个牧区,之前是不连通的。其次就是这两个牧区修路之后,
//相隔最远的两个牧区的距离最小。其实,只要枚举任意不连通的两个牧区在计算这种情况下的最远的距离就好了,
//然后在这些最远的距离中找到距离最小(题目要求半径最小)的一个就是所求了。
//关键是在两个不连通的牧区修路之后求牧场的半径呢?假设已将one牧区种的D和two牧区中的F相连,
//想一下,这个牧场的半径是不是等于与D相距最远的点到D的距离+D与F的距离+与F相距最远的点的距离呢?
//这样的求法是满足题目所说的牧场的半径是相距最远的两个点的距离。
//所以思路很快就出来了:
//1.用floyed计算任意两点间的距离
//2.计算每个点与其他点的最远距离
//3.计算任意两个不连通的点修路之后牧场的半径。
//http://www.xuebuyuan.com/1457314.html此文给出了英文原版题目,读下来,配合中文意思,弄懂题目了。
//http://www.nocow.cn/index.php/USACO/cowtour根据该文,弄懂了,为什么
//那我们只需要计算新连成的区块的直径,然后与原来的所有区块的直径放在一起,取最大直径就可以了
//突然对为什么取最大直径,又心存疑虑,想了3个小时,想不通,暂时搁置吧。
//老外的题,与中国的题,确实存在着文化差异。感叹。
//编码的过程中,真是服了,洛谷的样例输入数据有问题。查找了一通,发现没有问题,数据格式本就是如此。折腾了一场。
#include <stdio.h>
#include <string.h>
#include <math.h>//洛谷中,该头文件,必须以C++形式提交。
#define INF 1000000
int x[150+10],y[150+10];
double a[150+10][150+10],d[150+10],minD=INF;
char s[200];
double dis(int x1,int y1,int x2,int y2){
return sqrt((double)(x1-x2)*(x1-x2)+(double)(y1-y2)*(y1-y2));//别忘了强转,否者容易溢出100000*100000
}
int main(){
int i,j,k,n,w;
memset(d,0,sizeof(d));
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d%d",&x[i],&y[i]);
for(i=1;i<=n;i++){
scanf("%s",s+1);
for(j=1;j<=n;j++){
if(i!=j){
if(s[j]=='0')
a[i][j]=a[i][j]=INF;
else{
a[i][j]=a[j][i]=dis(x[i],y[i],x[j],y[j]);
}
}else
a[i][j]=0;
}
}
for(k=1;k<=n;k++)//floyd算法
for(i=1;i<=n;i++)
for(j=1;j<=n;j++)
if(a[i][j]>a[i][k]+a[k][j])
a[i][j]=a[i][k]+a[k][j];
for(i=1;i<=n;i++)//连通区块里找最大值
for(j=1;j<=n;j++)
if(a[i][j]<INF&&a[i][j]>d[i])
d[i]=a[i][j];
for(i=1;i<=n;i++)//连接两个牧区,找最小值。
for(j=1;j<=n;j++)
if(a[i][j]==INF&&minD>d[i]+d[j]+dis(x[i],y[i],x[j],y[j]))
minD=d[i]+d[j]+dis(x[i],y[i],x[j],y[j]);
for(i=1;i<=n;i++)//此处想不明白,为什么找最大值。 等水平高了再回看此题。2017-6-20 21:23
if(minD<d[i])
minD=d[i];
printf("%.6lf\n",minD);//1此处写成printf("%d\n",minD);低级错误
return 0;
}
2017-06-20 21:29 AC该单元6道题。
最小生成树
1.//P1546 最短网络 Agri-Net
//有了并查集,快排基础,Kruskal算法很快写出,样例通过,提交AC,一次性成功。2017-6-14 19:13
#include <stdio.h>
struct node{
int u;
int v;
int w;
}e[10000+100],et;
int f[100+10];
int getf(int u){
if(f[u]==u)
return f[u];
f[u]=getf(f[u]);
return f[u];
}
int merge(int u,int v){
int f1=getf(u),f2=getf(v);
if(f1!=f2){
f[f2]=f1;
return 1;//两个集合合并
}
return 0;//同属一个集合
}
void quicksort(int left,int right){
int i=left,j=right,mid=e[(left+right)/2].w;
while(i<=j){
while(e[i].w<mid)
i++;
while(e[j].w>mid)
j--;
if(i<=j){
et=e[i];
e[i]=e[j];
e[j]=et;
i++;
j--;
}
}
if(left<j)
quicksort(left,j);
if(i<right)
quicksort(i,right);
}
int main(){
int i,j,n,k=0,count=0,sum=0;
scanf("%d",&n);
for(i=1;i<=n;i++)
for(j=1;j<=n;j++){
k++;
e[k].u=i;
e[k].v=j;
scanf("%d",&e[k].w);
}
for(i=1;i<=n;i++)
f[i]=i;
quicksort(1,k);
for(i=1;i<=k;i++)
if(e[i].w!=0&&merge(e[i].u,e[i].v)==1){
sum+=e[i].w;
count++;
if(count==n-1)
break;
}
printf("%d\n",sum);
return 0;
}
2.//P2330 [SCOI2005]繁忙的都市
//第一遍读题,感觉看不懂,但静下心来,画图,模拟样例,还是弄懂了,最小生成树,边数容易确定n-1,找最后一条边
//也许到了晚上,忙了一天,小错误不断,不过还是需改,提交AC。
//Kruskal算法 需要基础:并查集,快排。
#include <stdio.h>
struct node{
int u,v,w;
}e[90000+100],et;
int f[300+10];
int getf(int u){
if(f[u]==u)
return f[u];
f[u]=getf(f[u]);
return f[u];
}
int merge(int u,int v){
int f1=getf(u),f2=getf(v);
if(f1!=f2){
f[f2]=f1;
return 1;
}
return 0;
}
void quicksort(int left,int right){
int i=left,j=right,mid=e[(left+right)/2].w;
while(i<=j){
while(e[i].w<mid)
i++;
while(e[j].w>mid)//2 此处写成 while(e[i].w>mid) 低级错误,查了会
j--;
if(i<=j){
et=e[i];
e[i]=e[j];
e[j]=et;
i++;
j--;
}
}
if(left<j)
quicksort(left,j);
if(i<right)
quicksort(i,right);
}
int main(){
int n,m,i,count=0,max=0;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)//1 犯了一个错误,将该句写到了scanf之前。
f[i]=i;
for(i=1;i<=m;i++)
scanf("%d%d%d",&e[i].u,&e[i].v,&e[i].w);
quicksort(1,m);
for(i=1;i<=m;i++)
if(merge(e[i].u,e[i].v)==1){
count++;
if(count==n-1){
max=e[i].w;
break;
}
}
printf("%d %d\n",n-1,max);
return 0;
}
2017-6-14 21:27
3.//P1991 无线通讯网
//读完题目,仔细研究,发现是最小生成树问题,找最小生成树中的最大长度。
//卫星电话,感觉在该题中无用。但又仔细一想,卫星电话的个数,影响的是最后大的边的个数。故,卫星电话有用。
//卫星电话个数s,对应边数s-1
//总哨所个数p,对应边数p-1
//一定要无线电通讯的边数 p-1-(s-1)
//提交,采用C方式,报sqrt错误,采用C++方式提交,测试点3,4,5 RE,明白要改数组长度。比较奇葩,第二次遇到了。不能采用C编译
//修改,e[250000+100],et;//1 写成 e[2500+100] 笔误,太小了 。提交AC.
//有并查集,快排基础,Kruskal算法编起来,真的很快。
#include <stdio.h>
#include <math.h>
struct zb{
int x,y;
}q[500+10];
struct node{
int u,v;
double w;
}e[250000+100],et;//1 写成 e[2500+100] 笔误,太小了
double dis(int x1,int y1,int x2,int y2){
return sqrt((x2-x1)*(x2-x1)+(y2-y1)*(y2-y1));
}
int f[500+10];
int getf(int u){
if(f[u]==u)
return f[u];
f[u]=getf(f[u]);
return f[u];
}
int merge(int u,int v){
int f1=getf(u),f2=getf(v);
if(f1!=f2){
f[f2]=f1;
return 1;
}
return 0;
}
void quicksort(int left,int right){
int i=left,j=right;
double mid=e[(left+right)/2].w;
while(i<=j){
while(e[i].w<mid)
i++;
while(e[j].w>mid)
j--;
if(i<=j){
et=e[i];
e[i]=e[j];
e[j]=et;
i++;
j--;
}
}
if(left<j)
quicksort(left,j);
if(i<right)
quicksort(i,right);
}
int main(){
int s,p,i,j,count=0,k=0;
scanf("%d%d",&s,&p);
for(i=1;i<=p;i++)
f[i]=i;
for(i=1;i<=p;i++)
scanf("%d%d",&q[i].x,&q[i].y);
for(i=1;i<=p;i++)
for(j=i+1;j<=p;j++){
k++;
e[k].u=i,e[k].v=j;
e[k].w=dis(q[i].x,q[i].y,q[j].x,q[j].y);
}
quicksort(1,k);
for(i=1;i<=k;i++)
if(merge(e[i].u,e[i].v)==1){
count++;
if(count==p-1-(s-1)){
printf("%.2lf",e[i].w);
break;
}
}
}
2017-6-14 22:44
4.//P1265 公路修建
//最小生成树模型,不同的是从最大边开始使用。
//测试样例,发现题目说法有误,则政府将否决其中最短的一条公路的修建申请;改成最长.
//e[12500000+100]数组,提交测试点2,10TLE,其余测试点MLE Kruskal算法该题不能用。
//无奈之下,Prim算法。 不能用邻接矩阵,只能用到的时候进行计算。
//样例通过,提交,测试点2-10 WA,修改,提交多次,还是测试点2-10 WA
//翻看http://blog.csdn.net/sinat_34943123/article/details/52336586 摘抄如下:
//值得注意的是,中间的函数最好这么写
//double ss(int yi,int er)
//{
//return sqrt((double)(a[yi]-a[er])(a[yi]-a[er])+(double)(b[yi]-b[er])(b[yi]-b[er]));
//}
//因为这里的自乘很可能爆int,改成longlong也不是不可以但耗内存 万一到别的题里就挂了,因此还是直接加个double省事
//突然醒悟,马上修改,立马10分变100分。2017-6-15
//做完该题,明白了什么叫精益求精,同时对Prim算法了解更深入了。
#include <stdio.h>
#include <math.h>
#include <string.h>
#define INF 999999999
struct zb{
int x,y;
}q[5000+10];
int vis[5000+10];
double d[5000+10];//d[]到生成树的最小距离。
double dis(int x1,int y1,int x2,int y2){
return sqrt((double)(x2-x1)*(x2-x1)+(double)(y2-y1)*(y2-y1));//3此处 return sqrt((x2-x1)*(x2-x1)+(y2-y1)*(y2-y1));
}
int main(){
int n,i,j,count=0,k;
double min;
double sum=0;
memset(vis,0,sizeof(vis));
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d%d",&q[i].x,&q[i].y);
vis[1]=1;
for(i=2;i<=n;i++)
d[i]=dis(q[1].x,q[1].y,q[i].x,q[i].y);
for(i=1;i<=n;i++){//循环次数
min=INF,k=0;
for(j=1;j<=n;j++)
if(vis[j]==0&&d[j]<min){//2 此处写成 if(vis[j]==0&&dis(q[i].x,q[i].y,q[j].x,q[j].y)<min)1 此处写成 if(vis[i]==0&&dis(q[i].x,q[i].y,q[j].x,q[j].y)<min)
min=d[j];//2 此处写成 min=dis(q[i].x,q[i].y,q[j].x,q[j].y);
k=j;
}
sum+=min;
count++;//2 将其与之后3句,移到此处,原来,在for循环的最后
if(count==n-1)
break;
vis[k]=1;//加入生成树
for(j=1;j<=n;j++)//更新生成树
if(vis[j]==0&&dis(q[k].x,q[k].y,q[j].x,q[j].y)<d[j])
d[j]=dis(q[k].x,q[k].y,q[j].x,q[j].y);
}
printf("%.2lf",sum);
return 0;
}
2017-6-15AC该单元4道题。
较复杂图论I
1.//P1113 杂务
//第一句:该题出得很差,题意根本无法让人明白,故发此博文。
//第一遍看完题目,知觉说是拓扑排序,当然题目样例还未完全弄明白。
//看题目的表述,感觉是外来题,翻译过来的题。
//花了些时间,题意还是不明白。至少样例没看懂。
//http://www.cnblogs.com/lyqlyq/p/6850150.html这篇文章的代码写得够短够好。
//跟踪了程序,弄明白了样例的意图:
//7 杂务个数
//1 5 0 杂务1 耗时5 需要前期杂务
//2 2 1 0 杂务2 耗时2 需要前期杂务1
//3 3 2 0 杂务3 耗时3 需要前期杂务2
//4 6 1 0 杂务4 耗时6 需要前期杂务1
//5 1 2 4 0 杂务5 耗时1 需要前期杂务2 4
//6 8 2 4 0 杂务6 耗时8 需要前期杂务2 4
//7 4 3 5 6 0 杂务7 耗时4 需要前期杂务3 5 6
#include <stdio.h>
#include <string.h>
int f[10000+100];
int max(int a,int b){
return a>b?a:b;
}
int main(){
int i,j,k,t,n,ans=0;
memset(f,0,sizeof(f));
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%d%d",&k,&t);
while(scanf("%d",&k)&&k)
f[i]=max(f[i],f[k]);
f[i]+=t;
ans=max(f[i],ans);
}
printf("%d\n",ans);
return 0;
}
2017-6-22
2.//P1268 树的重量
//第一遍看完题目,发现也就是将所有的边的权重不重复,全加起来即可。
//模拟了样例,发现难在重构相应的“进化树”。
//http://www.cnblogs.com/Chuckqgz/p/5644306.html此文原理写得不错
//画图弄明白了,加入的点,无论加入哪个分支,以1为根节点,在计算最小值过程中,一定能算出正确的最小值。
//该题思考远大于编程。
#include <stdio.h>
int e[30+5][30+5];
int main(){
int i,j,n,ans,min,b;//b表示增加一个点,多出的边长。
while(scanf("%d",&n)&&n){
for(i=1;i<=n;i++)
for(j=i+1;j<=n;j++){//无向图
scanf("%d",&e[i][j]);
e[j][i]=e[i][j];
}
ans=e[1][2];//只有两个点
for(i=3;i<=n;i++){//i表示新加入的点,故从3开始
min=999999999;
for(j=1;j<i;j++){//j表示枚举的点,除根节点1,以及新加入的点i.
b=(e[1][i]+e[j][i]-e[1][j])/2;//该公式可以根据画图计算得出。
if(min>b)
min=b;
}
ans+=min;
}
printf("%d\n",ans);
}
return 0;
}
2017-6-22
3.//P1525 关押罪犯
//代码角度来说,这篇文章写得比较漂亮http://hzwer.com/599.html
//该题用并查集的核心是,敌人的敌人是朋友。
//e[i].a+n表示e[i].a的对立面,属不同的两个集合,而该问题中一共两个集合。
//f[e[i].a+n] 与 f[e[i].a]爸爸不同。
//看懂他人代码比较关键的一条是:带入输入数据进行手动模拟。该题收获之一。
//该题收获之二,集合合并原来可以写得这么简洁。
#include <stdio.h>
#include <string.h>
int f[20000*2+100];
struct node{
int a,b,c;
}e[100000+100],e_t;
void quicksort(int left,int right){//快排,从大到小
int i=left,j=right,mid=e[(left+right)/2].c;
while(i<=j){
while(e[i].c>mid)
i++;
while(e[j].c<mid)
j--;
if(i<=j){
e_t=e[i];
e[i]=e[j];
e[j]=e_t;
i++;
j--;
}
}
if(left<j)
quicksort(left,j);
if(i<right)
quicksort(i,right);
}
int getf(int u){//找爸爸
if(f[u]==u)
return f[u];
f[u]=getf(f[u]);
return f[u];
}
int main(){
int n,m,i,j,f1,f2;
scanf("%d%d",&n,&m);
for(i=1;i<=2*n;i++)
f[i]=i;
for(i=1;i<=m;i++)
scanf("%d%d%d",&e[i].a,&e[i].b,&e[i].c);
quicksort(1,m);
for(i=1;i<=m;i++){
f1=getf(e[i].a);
f2=getf(e[i].b);
if(f1==f2){
printf("%d\n",e[i].c);
return 0;
}
f[f2]=getf(e[i].a+n);//合并集合 ,敌人的敌人是朋友
f[f1]=getf(e[i].b+n);
}
printf("0\n");
return 0;
}
2017-6-21
4.//P1983 车站分级
//拓扑排序,此文代码写得不错http://hzwer.com/767.html
//思路角度,此文不错http://blog.csdn.net/yuyanggo/article/details/48914523摘抄如下:
//拓扑排序。
//火车停靠站的级别总是高于未停靠站的,类似于拓扑排序里的先后顺序。
//假设一列火车的起点站为 s ,终点站为 e ,则途中的所有停靠站向未停靠站连一条边,表示停靠站的级别高于未停靠站,这样处理之后,就得到一个AOV图。
//对改图反复执行操作:
//1.将所有入度读为零的点入栈。
//2.将栈中所有点相连的边去掉,相连的点入度 -1。
// (对相连点进行判断,若入度为零,则保存起来。因为下一批入度为零的点必然是与本批入读为零的点项相连的)
//执行次数即为答案。
//根据样例,跟踪了代码,弄明白了拓扑排序的思路。同时也根据样例构建了该题,样例对应的AOV图.

//编码很快,调试很慢,调了30分钟,样例1,样例2通过后,提交AC.2017-6-21 23:10
#include <stdio.h>
#include <string.h>
int book[1000+10],a[1000+10],e[1000+10][1000+10],rd[1000+10],stack[1000+10];
int main(){
int n,m,i,j,k,q,top,ans=0;
memset(e,0,sizeof(e));
memset(rd,0,sizeof(rd));
scanf("%d%d",&n,&m);
for(i=1;i<=m;i++){//计算有向图,入度
scanf("%d",&q);
memset(book,0,sizeof(book));//3 放错位置,之前放在上面的for循环之外
for(j=1;j<=q;j++){
scanf("%d",&a[j]);
book[a[j]]=1;
}
for(j=a[1];j<=a[q];j++)
if(book[j]==0){
for(k=1;k<=q;k++)
if(e[j][a[k]]==0){//2 漏了该句,该句目的,避免重复计数
e[j][a[k]]=1;//联通,有向图
rd[a[k]]++;
}
}
}
memset(book,0,sizeof(book));//1 该句写错位置,写到while循环内部
while(1){
top=-1;
for(i=1;i<=n;i++)
if(book[i]==0&&rd[i]==0){
top++;
stack[top]=i;
book[i]=1;
}
if(top==-1)
break;//跳出循环
for(i=0;i<=top;i++)
for(j=1;j<=n;j++)
if(e[stack[i]][j]==1){
e[stack[i]][j]=0;
rd[j]--;
}
ans++;
}
printf("%d\n",ans);
return 0;
}
2017-6-22 AC此单元。
较复杂图论II
1.//P1993 小 K 的农场
//模拟样例,很快成功,该怎么写代码呢?
//翻看,说是要 查分约束 spfa 判断负环
//那么,好吧,开始学习 查分约束.
//借助http://www.cppblog.com/menjitianya/archive/2015/11/19/212292.html此文开始学习
//因有基础,直接看 上文中的 三、差分约束
//稍微折腾了一下,借助 一、引例 才将 1、数形结合 看懂
//很快将查分约束的,最大值,最小值,看懂了,文章写得真不错,有最小路径经验的读者可以直接看 一、引例 三、差分约束
//http://hzwer.com/3600.html此文代码写得不错,进行研究学习。
//为什么spfa用dfs而不用bfs,此文https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1993讲解不错,摘抄如下:
//此题一定使用SPFA的DFS形式,因为SPFA的BFS判断负环最坏复杂度为O(N^2)而DFS只有O(N),所以用BFS会TLE。
//http://blog.csdn.net/jzq233jzq/article/details/71597731?locationNum=9&fps=1此文写法比较接近传统意义上的SPFA判负。
//提交,测试点5,6,10WA ,静态查找,spfa(v);//2 致命的问题,忘了递归,测试点5,6,10WA ,提交AC 2017-6-24 21:30
#include <stdio.h>
#include <string.h>
#define INF 999999
struct node{
int to,next,w;
}e[10000*2+100];
int head[10000+100],cnt=0,d[10000+100],vis[10000+100],flag=0;
void add(int u,int v,int w){
cnt++,e[cnt].to=v,e[cnt].w=w,e[cnt].next=head[u],head[u]=cnt;
}
void spfa(int u){//用来判定是否有负环
int v,b;//b边
vis[u]=1;
b=head[u];
while(b!=0){
v=e[b].to;
if(d[v]>d[u]+e[v].w){
if(vis[v]==1){
flag=1;
return;
}
d[v]=d[u]+e[v].w;
spfa(v);//2 致命的问题,忘了递归,测试点5,6,10WA
}
b=e[b].next;
}
vis[u]=0;//回溯
}
int main(){
int n,m,i,j,a,b,c,f;
memset(vis,0,sizeof(vis));
memset(head,0,sizeof(head));//1 漏了此句
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
d[i]=INF;
for(i=1;i<=m;i++){
scanf("%d",&f);
if(f==3){
scanf("%d%d",&a,&b);
add(a,b,0);
add(b,a,0);
}else if(f==1){
scanf("%d%d%d",&a,&b,&c);
add(b,a,c);
}else if(f==2){
scanf("%d%d%d",&a,&b,&c);
add(a,b,-c);
}
}
for(i=1;i<=n;i++){
spfa(i);
if(flag==1){
printf("No\n");
return 0;
}
}
printf("Yes\n");
return 0;
}
2.//P1726 上白泽慧音
//该题样例很快模拟清楚。
//考察tarjan算法,好吧,开始学习。 http://www.cnblogs.com/uncle-lu/p/5876729.html
//https://wenku.baidu.com/view/112c64096c85ec3a87c2c527.html?re=view此文运算过程写得真不错。
//此文http://hzwer.com/4345.html代码写得不错
//提交,测试点2,8,9,10WA ,修改 in_stack[stack[top]]=0;//3 此处写成in_stack[x]=0; //不在栈内标记 提交AC
//2017-6-23 23:36
#include <stdio.h>
#include <string.h>
struct node{
int to,next;
}e[50000*2+100];
int cnt=0,head[5000+100],low[5000+100],dfn[5000+100],ind=0,in_stack[5000+100],top=-1,stack[5000+100],scc=0,belong[5000+100],have[5000+100];//low[x] x的爸爸 dnf[x] x的计数值(时间戳)
int min(int a,int b){
return a>b?b:a;
}
void add(int u,int v){
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt;
}
void tarjan(int x){
int b,v;//边
low[x]=dfn[x]=++ind;//设置时间戳
stack[++top]=x;//进栈
in_stack[x]=1;//栈内标记
b=head[x];
while(b!=0){
v=e[b].to;
if(dfn[v]==0){
tarjan(v);
low[x]=min(low[x],low[v]);//找爸爸
}else if(in_stack[v]==1){
low[x]=min(low[x],dfn[v]);//找爸爸
}
b=e[b].next;
}
if(low[x]==dfn[x]){//1 重大失误,将该if语句摆在上面while循环里 //找到强连通
scc++;
while(x!=stack[top]){
belong[stack[top]]=scc;//2 该处写成belong[x]=scc;//多对1,映射
have[scc]++;//统计scc强联通分量节点数
in_stack[stack[top]]=0;//3 此处写成in_stack[x]=0; //不在栈内标记
top--;
}
belong[x]=scc;//多对1,映射
have[scc]++;//统计scc强联通分量节点数
in_stack[x]=0;//不在栈内标记
top--;
}
}
int main(){
int i,j,n,m,u,v,t,max=0,ans,k=0;;
memset(head,0,sizeof(head));
memset(dfn,0,sizeof(dfn));
memset(in_stack,0,sizeof(in_stack));
memset(have,0,sizeof(have));
scanf("%d%d",&n,&m);
for(i=1;i<=m;i++){
scanf("%d%d%d",&u,&v,&t);
if(t==1)
add(u,v);
else if(t==2){
add(u,v);
add(v,u);
}
}
for(i=1;i<=n;i++)
if(dfn[i]==0)
tarjan(i);
for(i=1;i<=n;i++)
if(have[i]>max){
max=have[i];
ans=i;
}
printf("%d\n",max);
for(i=1;i<=n;i++)
if(belong[i]==ans){
k++;//打印格式处理
if(k==1)
printf("%d",i);
else
printf(" %d",i);
}
printf("\n");
return 0;
}
3.//P2055 [ZJOI2009]假期的宿舍
//样例数据挺复杂的,多遍之后,才读懂。
//该题有两种思路 网络流 二分图,选个代码短的进行学习,二分图。
//http://blog.csdn.net/dark_scope/article/details/8880547通过此文学习 二分图 匈牙利算法
//上文写得很精彩,很快看懂了。
//先练手 二分图匹配 匈牙利算法。采用 洛谷 P3386 【模板】二分图匹配
//弄明白了二分图匹配,开始该题的历程。
//采用邻接矩阵处理该题
//样例通过后,提交,全RE,发现问题: 1 漏写cnt=0 //1 错把该句放在while循环之外了
//修改,提交,有WA有RE ,经过2,3修改,还是有WA有RE ,经过4修改,还是有WA有RE 进过5的修改,提交AC
//该题难在建立二分图关系。逻辑上确实有难度。2017-6-25 22:53
//该题核心是匹配人和床的对应关系。但难度却是在建立二分图关系。
#include <stdio.h>
#include <string.h>
#define maxn 55
struct node{
int to,next;
}e[maxn*maxn/2];
int cnt,head[maxn],a[maxn],c[maxn],link[maxn],vis[maxn];
void add(int u,int v){
cnt++,e[cnt].to=v,e[cnt].next=head[u],head[u]=cnt;
}
int find(int u){//二分图匹配 匈牙利算法
int b,v;//b边
b=head[u];
while(b!=0){
v=e[b].to;
if(vis[v]==0){
vis[v]=1;
if(link[v]==0||find(link[v])){
link[v]=u;
return 1;
}
}
b=e[b].next;
}
return 0;
}
int main(){
int i,j,sum,tot,t,n,x;
scanf("%d",&t);
while(t--){
tot=0,sum=0,cnt=0;//1 漏写cnt=0//tot需要床的学生数,sum二分匹配,学生与床匹配
memset(head,0,sizeof(head));//1 错把该句放在while循环之外了
memset(link,0,sizeof(link));//1 错把该句放在while循环之外了
scanf("%d",&n);
for(i=1;i<=n;i++){//是否在校生
scanf("%d",&a[i]);
if(a[i]==0)//非在校生,需要床
tot++;
}
for(i=1;i<=n;i++){//是否回家
scanf("%d",&c[i]);
if(a[i]==1&&c[i]==0)//3 此处写成if(c[i]==0) 请注意,首先是住校生,然后是不回家;题中提到:注意如果第 i 个人不是在校学生,那么这个位置上的数是一个随机的数,意味着非住校生c[i]也可以是0//不回家的在校生,需要床
tot++;
}
for(i=1;i<=n;i++){
for(j=1;j<=n;j++){
scanf("%d",&x);
if(x&&a[j]==1&&((a[i]==1&&c[i]==0)||a[i]==0))//a[j]==1只要是住校生就能提供床位,无论他回不回家 5 此处写成if(x&&(a[j]==1&&c[j]==1)&&((a[i]==1&&c[i]==0)||a[i]==0))//2 此处写成 if(x&&(c[j]==0&&a[j]==1)&&((a[i]==1&&c[i]!=0)||a[i]==0))//学生与床对应关系 i人j床 c[j]==1&&a[j]==1 住校生回家,有床空出 (a[i]==1&&c[i]==0)住校生,不回家,需要床 a[i]==0非住校生
add(i,j);
}
if(a[i]==1&&c[i]==0)//4 漏了该句,很重要的判断条件,是不回家的住校生,可以睡自己的床
add(i,i);//自己也可以睡自己的床。
}
for(i=1;i<=n;i++){
memset(vis,0,sizeof(vis));
if(find(i)==1)
sum++;
}
printf("%s\n",sum>=tot?"^_^":"T_T");//床大于等于需求床的人,自然就正确了。
}
return 0;
}
4.//P2149 [SDOI2009]Elaxia的路线
//http://blog.csdn.net/slyz_wumingshi/article/details/69371411此文写得不错。摘抄如下:
//在原图中进行四遍SPFA,计算出每一个点到四个点的最短路,然后枚举每一条边,判断其是否可以同时出现在两条最短路中,如果可以就开一个新图,在这条边所在的位置加入一条单向边,进行拓扑排序,并维护答案。又由于两人面对面经过也算可行方案,所以我们还要重新判断每一条边是否可以容许两人面对面经过且处在两条最短路中,如果可以就重新开一个图,加入单向边,重新跑一遍拓扑排序,维护答案。
//这道题的数据实在是太水了,虽然大部分人都AC了,但是其实都是错误的。在bzoj的讨论中有两组数据,能将大部分人的代码卡掉。
//http://blog.csdn.net/dad3zz/article/details/50937398思路介绍得比较简洁,摘抄如下:
//4遍spfa,开四个dis数组,分别记录st1,st2,ed1,ed2到各点的最短路,然后枚举点对(i,j)判断i,j是否在最短路径上,然后更新答案即可.
//http://www.cnblogs.com/water-full/p/4515974.html思路也介绍得不错,摘抄如下:
//思路题--SPFA+拓扑排序求最长链
//首先用两个起点和两个终点分别做一次SPFA,求出他们到图中其他所有点的最短路径。
//然后枚举图中每一条边,判断他是否同时在两个人的最短路上,即这条边的权值加上他的端点到两人起点和终点的距离是否恰好等于起点到终点的最短距离。
//如果在的话,就加入到新图中。
//问题就变成了求新图的最长链,直接topsort即可。
//http://blog.csdn.net/frods/article/details/54890608此文思路写得真棒,摘抄如下:
//分析:
//1.本题的难点在于有多条最短路,要求最长的公共最短路。
//2.首先解决一条边是否存在在最短路上的问题。
//3.注意到当d[s][u]+w[u][v]+d[v][t]=d[s][t]时,边(u,v)就会在s到t的最短路径上,因此,我们不妨对4个点都进行一次最短路。
//4.接下来解决最长公共最短路的问题。因为上一步我们已经选出了公共的最短路边,实际上我们就可以把问题进行分解,找到选出的边中路径最长的一条,拓扑排序+BFS就可以解决了
//5.错误提醒,注意边数的大小(maxn*maxn*2)
//http://blog.csdn.net/eod_realize/article/details/37583019终于找到一个画图解释该题的文章了,大家可以去看看,与众不同之处是画了图,太有助于理解了。
//该题编写完成后对拓扑图有了更深的理解,拓扑图的核心操控是 入度,研究拓扑图,构建拓扑图是必需的。拓扑图是 有向图。
//提交,测试点3,5-10WA,仔细查了代码,发现 e[1500*1500/2+100];//3 此处写成 e[1500*2+100]提交,测试点5,9WA
//e[1500*1500/2+100];//4 犯晕了,竟然忘记了该题是无向图 写成 e[1500*1500/2+100]
//1500*1500/2*2计算公式如左,继续提交还是测试点5,9WA,继续修改 e[1500*1500*2+100];//5继续修改 e[1500*1500*2+100]; 写成e[1500*1500+100];
//提交,测试点5,9WA. cnt=0;//6 忘记了该句 提交 测试点5,9WA
//7 7 #define INF 10009改成 8#define INF 999999 AC了一个数据,将 8#define INF 999999改成 #define INF 999999999又AC了一个数据,老天啊,怎么这么对我,测试数据 有严重问题。1 ≤ l ≤ 10000随便给给的。
//一个#define INF 999999999调了一个小时,猜测测试数据,也是随机生成,不能保证 1 ≤ l ≤ 10000 ,因为没有对数据进行极限测试。
//2017-6-27 INF开得大一些,测试数据不可信。
#include <stdio.h>
#include <string.h>
#define INF 999999999//8#define INF 999999 7 #define INF 10009
int n,m,x1,y1,x2,y2,head[1500+10],cnt=0,q[1500*5+10],s1[1500+10],t1[1500+10],s2[1500+10],t2[1500+10],vis[1500+10],rd[1500+10],ans=0,top_head[1500+10];//rd[]入度
struct node{
int to,next,w;
}e[1500*1500+100];//4 犯晕了,竟然忘记了该题是无向图 写成 e[1500*1500/2+100] 3 此处写成 e[1500*2+100]
int max(int a,int b){
return a>b?a:b;
}
void add(int head[],int u,int v,int w){//邻接表 无向图
cnt++,e[cnt].to=v,e[cnt].w=w,e[cnt].next=head[u],head[u]=cnt;
}
void spfa(int s,int d[]){//a起始点
int i,j,h,t,u,v,b;//b边
memset(vis,0,sizeof(vis));//访问标识,初始化
for(i=1;i<=n;i++)
d[i]=INF;
d[s]=0;
h=t=1;
q[t]=s;
vis[s]=1;
t++;
while(h<t){
u=q[h];
b=head[u];
while(b!=0){
v=e[b].to;
if(d[v]>d[u]+e[b].w){
d[v]=d[u]+e[b].w;
if(!vis[v]){//v未被访问过。
vis[v]=1;
q[t]=v;//进队列
t++;
}
}
b=e[b].next;
}
vis[u]=0;//别忘了 设置为0
h++;
}
}
void topologysort(){//在重构的拓扑图上操作,而不是原图。 拓扑图是有向图。
int h,t,d[1500+10],u,v,w,b;//b边
memset(d,0,sizeof(d));
h=t=1;
for(u=1;u<=n;u++)
if(!rd[u]){
q[t]=u;
t++;
}
while(h<t){
u=q[h];
ans=max(ans,d[u]);//初始度为0的点到u的最长距离
for(b=top_head[u];b;b=e[b].next){
v=e[b].to,w=e[b].w;
d[v]=max(d[v],d[u]+w);
rd[v]--;
if(!rd[v]){//入度为0加入队列
q[t]=v;
t++;
}
}
h++;
}
}
int main(){
int i,j,u,v,w,b;//b边
memset(head,0,sizeof(head));
scanf("%d%d",&n,&m);
scanf("%d%d%d%d",&x1,&y1,&x2,&y2);
for(i=1;i<=m;i++){
scanf("%d%d%d",&u,&v,&w);
add(head,u,v,w),add(head,v,u,w);
}
spfa(x1,s1),spfa(y1,t1),spfa(x2,s2),spfa(y2,t2);//对四个点,找最小路径。
memset(rd,0,sizeof(rd));//入度初始化
memset(top_head,0,sizeof(top_head));
cnt=0;//6 忘记了该句
for(u=1;u<=n;u++)//u是点
for(b=head[u];b;b=e[b].next){ //b是边
v=e[b].to,w=e[b].w;
if(s1[u]+w+t1[v]==s1[y1]&&s2[u]+w+t2[v]==s2[y2])//2 犯了一个重大的错误,此处写成 if(s1[u]+b+t1[v]==s1[y1]&&s2[u]+b+t2[v]==s2[y2])
add(top_head,u,v,w),rd[v]++;
}
topologysort();
memset(rd,0,sizeof(rd));//入度初始化
memset(top_head,0,sizeof(top_head));//3 此处漏写了
cnt=0;//6 忘记了该句
for(u=1;u<=n;u++)//u是点
for(b=head[u];b;b=e[b].next){ //b是边
v=e[b].to,w=e[b].w;
if(s1[u]+w+t1[v]==s1[y1]&&s2[v]+w+t2[u]==s2[y2])//2 犯了一个重大的错误,此处写成 if(s1[u]+b+t1[v]==s1[y1]&&s2[v]+b+t2[u]==s2[y2])
add(top_head,u,v,w),rd[v]++;
}
topologysort();
printf("%d\n",ans);
return 0;
}
5.
洛谷 P1345 [USACO5.4]奶牛的电信Telecowmunication
//P1345 [USACO5.4]奶牛的电信Telecowmunication
//通过该题,学习了最大流,做了模板题 P3376 【模板】网络最大流
//http://www.cnblogs.com/albert7xie/p/5323591.html思路介绍得不错,摘抄如下:
/*我记得以前貌似是删边的。删点其实也类似,把点转换成边就可以了。所以就要拆点了,拆点的方法不多说。
然后跑一遍最小割(最大流),原来的边的流量设为无限大,拆点的边就置为1,不过要注意的是这里是无向边。
主要问题就是怎么让答案的字典序最小。其实枚举就行了!枚举每一个点,然后删点,跑最大流,看一下流量是否变小,变小了就真(是真的!)删掉这个点,如果没有改变说明删不删这个点都一样。
因为每次增广都肯定会少掉至少一条边(点),这里的求最大流速度就会很快,大概是O(N2),那么总的时间复杂度就是O(N3)。
*/
//http://www.cnblogs.com/txhwind/archive/2012/08/18/2645333.html题解也写得不错,摘抄如下:
/*这个问题是要求该图的最小点割集,可以使用最小割最大流定理。
但是最小割是边的割,该怎么办呢?
拆点!将每个点拆成入点和出点。所有入边连到入点上,出边从出点连出,流量均为+INF。再在入点和出点间连一条流量为1的边。然后做最大流即为答案。
至于输出最小字典序方案的问题,可以参考milk6,从小到大枚举删点,若删去后流量减少了1,则输出。
*/
//学习了Ford-Fulkerson算法 EdmondsKarp算法 Dinic算法 发现这个题解写得最不错
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1345摘抄如下:
//这题难在建模啊
//~~不知道光说怎么连边不说原因的网络流题解有什么意义~~
//不难看出,这道题是求最小割点集的大小。
//显然的是,对于一个点,它只能被删一次。~~废话~~
//那么,对于每一个点i,我们都要复制它(设为i+n),并且从i到i+n连1的边(因为只能删一次)。(反向连0不要忘记)
//add ( i, i+n, 1 ) ; add ( i+n, i, 0 ) ;
//然后怎么看待原图中本来就存在的边呢?它们只是有一个联通的作用,对于流量并没有限制,所以明确一点:这些边加入网络中限制应该为无限大。
//假设现在要从原图中添加一条从x到y的有向边(这道题是无向边,再依下面的方法添加一个y到x的就行了)到网络中去,对于点y来说,这条边的加入不应该影响通过它的流量限制(就是前面连的那个1)发生变化,所以前面那条y到y+n的边应该接在这条边的后面,所以这条边的终点连向网络中的y,相反的,这条边应该受到x的(前面连的1)限制。因为,假设x已经被删(x到x+n满流),那么这条边再加不加都是没有变化的。所以,这条边在网络中的起点应该是x+n,这样才保证受到限制。
//add ( y+n, x, 无限大 ) ;
//add ( x, y+n, 0 ) ;
//add ( x+n, y, 无限大 ) ;
//add ( y, x+n, 0 ) ;
//不要忘记反向的。
//http://www.fx114.NET/qa-255-116191.aspx读后有启发,摘抄如下:
//将每个点拆分为两个点(如i拆分为i1和i2),原图中的边(i, j)在新图中变成四条有向边:(i1, i2) = 1,(j1, j2) = 1,(i2, j1) = INFINITY,(j2, i1) = INFINITY,等号后面为边权
//源点为c1的第二个点c12,汇点为c2的第一个点c21,求最大流MaxFlow(c12, c21),则为第一问的答案
//遍历每一条边(i1, i2),i = [1, N]并且c1, c2除外。如果将其去掉后当前最大流减少了1,则代表点i属于最小割集,也就是第二问的答案中
//http://www.cnblogs.com/SilverNebula/p/6062798.html读后有启发,摘抄如下:
//网络流最小点割。把每个点拆成入点和出点(i->i+n),在入点和出点之间连一条容量为1的边。将所给m条边容量设为INF,跑最大流即可。
//http://www.cnblogs.com/Currier/p/6695444.html读后有启发,摘抄如下:
//把一个点拆成两个点,连上容量为1的边,然后把其他边连一连求一下最小割就好了。
//刚开始求c1的入点到c2的出点的最小割了,WA了一发,其实是求c1的出点到c2的汇点的最小割。要注意。
//http://www.wosoni.com/cnblogs-modengdubai-p-4865569.html介绍构图上,讲解不错,摘抄如下:
//读完题就知道是求两点独立轨条数的问题。
//就是将一个点拆成两个点求最大流。
//但是在如何将一个点拆分成两个点之后如何建图的问题上纠结了好久。
//其实就是将一个点拆分成流入点和流出点。然后流入到流出之间有一条容量为1的有向弧。
//原来的a和b之间联通的话,就是a的出点流到了b的入点,且b的出点流到了a的入点。
//还有一个问题要解决,就是有多个最小割时如何得到集合大小最小,且字典序最小的集合。
//其实因为拆分之后的流入点到流出点之间的容量为1,且原来每个点拆分之后的自己的流入和流出之间的容量都为1.
//可以证明所有的最小割的集合大小相等。所以只要找到字典序最小的那个就好了。
//根据退流定理,枚举删除每个点。
//先找到编号最小的一个割点。
//然后删除这个点,求得删除这个点之后的最大流。将容量网络恢复。并在容量网络中删除这个点。一直重复这一步直到容量网络的最大流变为0.
//有了上面的基础,该题弄明白了。关键字:入点,出点。
附上该题最核心的图:
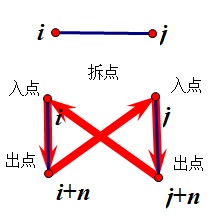
//修改 e[600*4+100+100];//2此处写成 e[600*2+100+100];提交,测试点1,2RE
//将数组中的100统统变成1000,提交AC,真是火大,精确算出的数组容量尽然不对
//仔细想想,确实不对,拆点,1变2.
//继续修改 ,int n,m,s,t,head[100*2+10],cnt=1,q[100*2+10],level[100*2+10],maxflow=0;//8 head[1000+10],cnt=1,q[1000+10],level[1000+10],maxflow=0;//7 数组容量100+10 ,
//提交AC
//该题,注意,bfs,dfs,都是从s+n到t 即出点到入点
#include <stdio.h>
#include <string.h>
#define INF 999999999
struct node{
int to,next,c;
}e[600*4+100*2+100];//3此处写成e[600*4+100+100] // 2此处写成 e[600*2+100+100];
int n,m,s,t,head[100*2+10],cnt=1,q[100*2+10],level[100*2+10],maxflow=0;//8 head[1000+10],cnt=1,q[1000+10],level[1000+10],maxflow=0;//7 数组容量100+10
int min(int a,int b){
return a>b?b:a;
}
void add(int u,int v,int c){//邻接表
cnt++,e[cnt].to=v,e[cnt].next=head[u],e[cnt].c=c,head[u]=cnt;
}
int bfs(int s1,int t1){//6一个重大问题,队尾用变量t,终点也用变量t,显然不行//分层
int u,v,h,tail,b;//b边
memset(level,0,sizeof(level));//每次分层前,初始化
h=tail=1;
q[tail]=s1;
level[s1]=1;
tail++;
while(h<tail){
u=q[h];
h++;
for(b=head[u];b>1;b=e[b].next){
v=e[b].to;
if(!level[v]&&e[b].c){
level[v]=level[u]+1;
q[tail]=v;
tail++;
}
}
}
return level[t1]>0;
}
int dfs(int now,int t1,int limit){//增广
int u,v,b,flow=0,f;
if(now==t1||!limit)return limit;
for(b=head[now];b>1;b=e[b].next){
v=e[b].to;
if(level[now]+1==level[v]&&(f=dfs(v,t1,min(limit,e[b].c)))){
flow+=f;
limit-=f;
e[b].c-=f;
e[b^1].c+=f;
}
if(!limit)break;
}
return flow;
}
int main(){
int i,x,y;
memset(head,0,sizeof(head));
scanf("%d%d%d%d",&n,&m,&s,&t);
for(i=1;i<=m;i++){
scanf("%d%d",&x,&y);//1 重大失误,此处写成 scanf("%d%d%d",&x,&y);
add(x+n,y,INF);
add(y,x+n,0);
add(y+n,x,INF);
add(x,y+n,0);
}
for(i=1;i<=n;i++){
add(i,i+n,1);
add(i+n,i,0);
}
while(bfs(s+n,t))
maxflow+=dfs(s+n,t,INF);
printf("%d\n",maxflow);
return 0;
}
2017-7-2 16:56
2017-7-2 16:58 AC 该单元
并查集
1.//p1111 修复公路//难度:普及/提高-
//考点:输入,输出 ,并查集,快速排序
//适用:小学生
//注意:过大的数组要开到main函数的外面。
//小技巧:要设置一个计数变量
//看了数据范围,快速排序是省不了了
//四个错误如下:
//for(i=1;i<=n;i++)//1该句太超前,查了半天,现在移位
//quicksort(1,m);//2此处写成quicksort(1,n),查了会
//while(i<=j){//3竟然漏了这个最大的循环,真是笑话
//for(i=1;i<=m;i++){//4此处写成for(i=1;i<=n;i++),又是查了半天
#include <stdio.h>
int n,m;
struct node{
int x;
int y;
int t;
}q[100000+100],q_t;
int f[1000+10];
void quicksort(int left,int right){//自小到大排序
int i=left,j=right;
int mid=q[(i+j)/2].t;
while(i<=j){//3竟然漏了这个最大的循环,真是笑话
while(q[i].t<mid)
i++;
while(q[j].t>mid)
j--;
if(i<=j){
q_t=q[i];
q[i]=q[j];
q[j]=q_t;
i++;
j--;
}
}
if(left<j)
quicksort(left,j);
if(i<right)
quicksort(i,right);
}
int getf(int u){
if(f[u]==u)
return u;
f[u]=getf(f[u]);
return f[u];
}
void merge(int t1,int t2){//靠左
int f1,f2;
f1=getf(t1);
f2=getf(t2);
if(f1!=f2){
f[f2]=f1;
}
}
int main(){
int i,j,count;
scanf("%d%d",&n,&m);
for(i=1;i<=m;i++)
scanf("%d%d%d",&q[i].x,&q[i].y,&q[i].t);
quicksort(1,m);//2此处写成quicksort(1,n),查了会
for(i=1;i<=n;i++)//1该句太超前,查了半天,现在移位
f[i]=i;
for(i=1;i<=m;i++){//4此处写成for(i=1;i<=n;i++),又是查了半天
merge(q[i].x,q[i].y);
count=0;
for(j=1;j<=n;j++)
if(f[j]==j){
count++;
if(count>1)
break;
}
if(count==1){
printf("%d\n",q[i].t);
return 0;
}
}
printf("-1\n");
return 0;
}
2.//P2024 食物链
//靠自己,想不到要分成三块x的同类,x吃的动物,被x吃的动物
//f[x] f[x+n] f[x+2*n]x的同类,x吃的动物,吃x的动物
//f[y] f[y+n] f[y+2*n]y的同类,y吃的动物,吃y的动物
//审题不清,没往脑子里去:A 吃 B,B吃 C,C 吃 A。
//http://www.cnblogs.com/zbtrs/p/5819576.html分析得不错,摘抄如下 :
//分析:吃与被吃和同类是三种逻辑关系,而三种逻辑关系对应的动物又有很多,而动物之间又可以形成集合,所以考虑并查集.因为有3种逻辑关系,所以用大小n*3的并查集.
//可以参考noip2010的关押罪犯,对于一个犯人而言,另一个犯人只有可能和他在同一个监狱或者在不同监狱,那么建立n*2大小的并查集,那么对于本题也是一样,用x表示和x同种的动物集合,x+n表示被x吃的动物,x+2*n表示吃x的动物,那么对于另一种动物y,如果是第一种说法,那么x和y一定是同类(废话......),那么如果y在x+n的集合中或者y在x+2*n的集合中,就是假话,当然,要先判断x或y是否大于n并且是否相等,之后合并一下x和y,x+n和y+n,x+2*n和y+2*n.
//那么对于第二种说法呢?如果x和y是同类,那么肯定是假话,如果y吃x,那么肯定也是假话,那么判断x和y或者x+2*n和y是否在同一个集合即可,之后合并x和y + 2 * n,x + n和 y,x + 2*n和y + n(因为食物链是环,吃x的必然被y吃),那么本题就结束了.
//提交30分,只AC了测试点1,3,9明白是判断同类,异类出了问题。 修改,提交还是30分
//错在:如果是第一种说法,那么x和y一定是同类(废话......),那么如果y在x+n的集合中或者y在x+2*n的集合中,就是假话
//错在:那么对于第二种说法呢?如果x和y是同类,那么肯定是假话,如果y吃x,那么肯定也是假话
//归根结底,对题目分析不够,望日后有重做的机会2017-6-4 23:18
#include <stdio.h>
int f[3*50000+100];
int getf(int z){
if(f[z]==z)
return z;
f[z]=getf(f[z]);
return f[z];
}
void merge(int a, int b){//靠左规则
int f1=getf(a),f2=getf(b);
if(f1!=f2)
f[f2]=f1;
}
int main(){
int n,k,i,j,x,y,t,ans=0;
scanf("%d%d",&n,&k);
for(i=1;i<=3*n;i++)
f[i]=i;
for(i=1;i<=k;i++){
scanf("%d%d%d",&t,&x,&y);
if(x>n||y>n)
ans++;
else if(t==1){
if(getf(x+n)==getf(y)||getf(x+2*n)==getf(y))//2getf(x+n)==getf(y)||getf(x)==getf(y+n) x吃y 或者 y吃x 非同类 1getf(x+n)==getf(y)||getf(x+2*n)==getf(y+n)||getf(x)==getf(y+2*n)
ans++;
else{
merge(x,y);
merge(x+n,y+n);
merge(x+2*n,y+2*n);
}
}else if(t==2){
if(getf(x)==getf(y)||getf(x+2*n)==getf(y))//2getf(x)==getf(y)同类 同类1getf(x)==getf(y)||getf(x+n)==getf(y+n)||getf(x+2*n)==getf(y+2*n)
ans++;
else{
merge(x+n,y);
merge(x+2*n,y+n);
merge(x,y+2*n);
}
}
}
printf("%d\n",ans);
return 0;
}
3.//P1197 [JSOI2008]星球大战
//读完题目,发现是并查集
//但看到不断的有数据被删除,觉得每次都要算一遍,好麻烦啊,超时是肯定的
//当然,也相信通过该题,并查集能更上一层楼。
//怀着忐忑的心情提交,结果测试点3-10全TLE
//http://hzwer.com/1695.html此文写得不错,同时意味着需要学习图的邻接表表示方法
//解题思路摘抄如下:
//给定一张图,支持删点和询问连通块个数
//按操作顺序处理的话要在删除点的同时维护图的形态(即图具体的连边情况),这是几乎不可做的
//我们发现,这道题可以先读入操作,把没删的点的边先连上,然后再倒序处理操作
//这样的话从删点变成了加点,而且只要维护连通块的数量,用并查集可以快速的解决这个问题
#include <stdio.h>
#include <string.h>
struct node{
int to;//终点
int next;//下一条边的位置。
}e[400000+100];
int head[400000+100],f[400000+100],cnt=0,tot=0,n,m,used[400000+100],d[400000+100],des[400000+100],ans[400000+100];//cnt统计边数,tot统计连通数
void ins(int u,int v){//插入边
cnt++;e[cnt].to=v;e[cnt].next=head[u];head[u]=cnt;//2此处写成cnt++;e[u].to=v;e[u].next=head[u];head[u]=cnt;
cnt++;e[cnt].to=u,e[cnt].next=head[v];head[v]=cnt;//2此处写成cnt++;e[v].to=u,e[v].next=head[v];head[v]=cnt;
}
int getf(int u){//找爸爸
if(f[u]==u)
return u;
f[u]=getf(f[u]);
return f[u];
}
void add(int u){//加入点,判断连通
int i=head[u],p=getf(u),q,v;//1 此处写成 p=f[u]
tot++;//连通区域加1
while(i){//非0,即继续搜
v=e[i].to;
if(used[v]==1){
q=getf(v);//1此处写成 q=f[v];
if(p!=q){
f[q]=p;//4此处写成 f[v]=p;检讨一下
tot--;//连通区域减1
}
}
i=e[i].next;//下一条边的位置
}
}
int main(){
int i,j,u,v,k;
memset(head,0,sizeof(head));
memset(used,0,sizeof(used));
memset(des,0,sizeof(des));
scanf("%d%d",&n,&m);
for(i=0;i<n;i++)
f[i]=i;
for(i=1;i<=m;i++){
scanf("%d%d",&u,&v);
ins(u,v);
}
scanf("%d",&k);
for(i=1;i<=k;i++){
scanf("%d",&d[i]);
des[d[i]]=1;
}
for(i=0;i<n;i++)
if(des[i]==0){
add(i);
used[i]=1;//3此处写成 used[i];也叫个没想法
}
ans[k]=tot;
for(i=k;i>=1;i--){
add(d[i]);
used[d[i]]=1;//3此处写成 used[i];也叫个没想法
ans[i-1]=tot;
}
for(i=0;i<=k;i++)
printf("%d\n",ans[i]);
return 0;
}
4.//P1196 银河英雄传说
//读题样例弄懂,确定是并查集
//感觉应该能编出,不过,可能会超时。
//按自己思路编写,不如意,翻阅《算法艺术与信息学竞赛》P82对该题有一个解题思路。
//http://hzwer.com/903.html跟踪此文,弄明白后开始编码。
//printf("x=%d y=%d sum[x]=%d sum[y]=%d s[x]=%d s[y]=%d\n",x,y,sum[x],sum[y],s[x],s[y]);//跟踪
//printf("%d\n",abs(sum[x]-sum[y])-1);//此种写法错误
#include <stdio.h>
#include <stdlib.h>
int f[30000+100],s[30000+100],sum[30000+100];//f[i] i的爸爸 s[i] i到爸爸的深度 sum[i] i之后的数量,包括i
int getf(int u){
int p;
if(f[u]!=u){
p=getf(f[u]);
s[u]+=s[f[u]];//深度,s[u]到爸爸f[u]的深度,s[f[u]]爸爸f[u]到f[u]爸爸的深度 请注意sum[i]没有改变
f[u]=p;//路径压缩
}
return f[u];
}
int main(){
int t,x,y,i,f1,f2;
char cmd[5];
for(i=1;i<=30000;i++){
f[i]=i;
sum[i]=1;
s[i]=0;
}
scanf("%d",&t);
for(i=1;i<=t;i++){
scanf("%s%d%d",cmd,&x,&y);
f1=getf(x);
f2=getf(y);
if(cmd[0]=='M'){//该题中,合并靠右
f[f1]=f2;
s[f1]=sum[f2];//f1有新的爸爸,故其到新爸爸的深度要改变。
sum[f2]+=sum[f1];//f2是f1的爸爸,故sum[f2]要加上之后sum[f1]的数量 改变的是爸爸之后的数量,其他数量未改变
}else{
if(f1!=f2)
printf("-1\n");
else
printf("%d\n",abs(s[x]-s[y])-1);//1此处写成 printf("%d\n",abs(s[y]-s[x]-1));
}
}
return 0;
}
2017-6-5 22:38完成该单元4道题。
堆
1.//P1801 黑匣子_NOI导刊2010提高(06)
//费老大劲,才算读懂样例,难道该题是外国人出的,怎么这么难读懂。
//7 4
//3 1 -4 2 8 -1000 2
//1 2 6 6
//7个点4个动作。1:放入3后读取第1小;2:放入3 1后读取第2小;6:放入3 1 -4 2 8 -1000读取第3小;6:放入3 1 -4 2 8 -1000读取第4小。
//http://blog.csdn.net/huzujun/article/details/49470135此文写的不错,摘抄如下:
//我们建立两个堆,一个小根堆hmin,一个大根堆hmax。一开始读入数据时,将数据加入hmin。进行GET操作时,输出hmin的堆顶,并将其移入hmax。
//这样,hmax中存有的,就是当前黑箱中最小的i个数。当最新读入的数x比hmax的堆顶y要小时,说明x在新黑箱最小的i个数之中,相当于y的位置就被x挤掉了。那么就将y移回hmin。若x比y要大,则将x加入hmin。
//这种双堆的技巧,也适用于求多个连续区间的中位数。
//http://blog.csdn.net/darost/article/details/52734743此博文也写得不错,摘抄如下:
//开两个堆,一个大根堆维护1~i-1小元素,一个小根堆维护i~n小元素
//添加元素时,如果元素小于大根堆堆顶,那么把大根堆堆顶出堆,将此元素加入大根堆
//否则将元素加入小根堆
//查询值即为小根堆顶,查询完后将小根堆顶加入大根堆
//本题,优点,编写了push,pop函数,思路还有一点混轮,但程序是编的很不错。2017-7-9
#include <stdio.h>
#define maxn 200000+100
int qmin[maxn],qmax[maxn],qmin_s=0,qmax_s=0,a[maxn];//qmin[]小根堆,存储由小到大序列i-n的元素;qmax[]大根堆,存储由小到大序列1-i-1的元素 qmin_s堆中元素个数 qmax_s堆中元素个数
void qmin_push(int k){//插入小根堆
int p;
qmin_s++;
p=qmin_s;
while(p>1&&k<qmin[p/2]){
qmin[p]=qmin[p/2];
p/=2;
}
qmin[p]=k;
}
void qmax_push(int k){//插入大根堆
int p;
qmax_s++;
p=qmax_s;
while(p>1&&k>qmax[p/2]){//1 此处写成 while(p>1&&k<qmax[p/2]) 拷贝粘贴的代价
qmax[p]=qmax[p/2];
p/=2;
}
qmax[p]=k;
}
void qmin_adjust(int t){
int left=2*t,right=2*t+1,k=t,tmp;
if(left<=qmin_s)k=qmin[k]<qmin[left]?k:left;
if(right<=qmin_s)k=qmin[k]<qmin[right]?k:right;
if(k!=t){
tmp=qmin[k],qmin[k]=qmin[t],qmin[t]=tmp;
qmin_adjust(k);
}
}
int qmin_pop(){
int t=qmin[1];
qmin[1]=qmin[qmin_s];
qmin_s--;
qmin_adjust(1);
return t;
}
void qmax_adjust(int t){
int left=2*t,right=2*t+1,k=t,tmp;
if(left<=qmax_s)k=qmax[k]>qmax[left]?k:left;//1 此处写成 if(left<=qmax_s)k=qmax[k]<qmax[left]?k:left; 拷贝粘贴的代价
if(right<=qmax_s)k=qmax[k]>qmax[right]?k:right;//1 if(right<=qmax_s)k=qmax[k]<qmax[right]?k:right;拷贝粘贴的代价
if(k!=t){
tmp=qmax[k],qmax[k]=qmax[t],qmax[t]=tmp;
qmax_adjust(k);
}
}
int qmax_pop(){
int t=qmax[1];
qmax[1]=qmax[qmax_s];
qmax_s--;
qmax_adjust(1);
return t;
}
int main(){
int n,m,i,j=1,x;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
scanf("%d",&a[i]);
for(i=1;i<=m;i++){
scanf("%d",&x);
for(;j<=x;j++){
if(qmax_s&&a[j]<qmax[1]){
qmin_push(qmax_pop());
qmax_push(a[j]);
}else
qmin_push(a[j]);
}
printf("%d\n",qmin[1]);
qmax_push(qmin_pop());
}
return 0;
}
2.//P2278 [HNOI2003]操作系统
//搜索了好多代码,但是都看不懂,无奈,还是要跟踪。
//想找堆的代码来分析,但大多都是优先队列的,算了,还是分析出思想,之后用堆来写
//http://blog.csdn.net/nlj1999/article/details/50464864找来该篇的代码,提交,发现最后一个测试点TLE。
//那么只好作罢,在提交中,找了时间最短,内存最小的进行研究。提交,最后一个测试点TLE,明白洛谷改过数据了,那么只要在最近通过程序中,找好的代码。
//找了一堆代码,全是最后一个测试点TLE,无奈,找最新的,且编译无优化,代码较短的,终于找到,进行研究学习。
//本人编码过程中,发现now的转换是难点。
//样例通过后,提交AC.2017-7-8
#include <stdio.h>
#define maxn 15000+100
struct node{//进程号num 到达时间arrive 执行时间left 优先级 priority
int num,arrive,left,priority;
}heap[maxn],tmp;//heap[1]最先执行的进程
int s=0,now=0;//堆中元素个数 s,当前时间now(即读取当前进程时,上一个进程可用时间结束的时刻,当前进程开始时刻)
int cmp(int x,int y){//x,y两进程在堆中序号,比较两进程,谁先执行。x先执行,返回1,y先执行,返回0
return heap[x].priority>heap[y].priority||heap[x].priority==heap[y].priority&&heap[x].arrive<heap[y].arrive;//执行优先级高的进程;若优先级相同,执行先到达的进程。
}
void insert(int num,int arrive,int left,int priority){
int p;
s++;
p=s;
while(p>1&&(priority>heap[p/2].priority||priority==heap[p/2].priority&&arrive<heap[p/2].arrive)){
heap[p]=heap[p/2];
p/=2;
}
heap[p].num=num,heap[p].arrive=arrive,heap[p].left=left,heap[p].priority=priority;
}
void adjust(int t){
int left=2*t,right=2*t+1,k=t;//left左儿,right右儿
if(left<=s)k=cmp(k,left)?k:left;
if(right<=s)k=cmp(k,right)?k:right;
if(k!=t){
tmp=heap[k];
heap[k]=heap[t];
heap[t]=tmp;
adjust(k);
}
}
void del(){
printf("%d %d\n",heap[1].num,heap[1].left+now);
now=heap[1].left+now;//2 漏了此句
heap[1]=heap[s];
s--;
adjust(1);
}
int main(){
int num,arrive,left,priority;
while(scanf("%d%d%d%d",&num,&arrive,&left,&priority)!=EOF){//1此处漏了!=EOF
while(s&&heap[1].left+now<=arrive)//堆中有元素,且在下一个进程到达前,当前进程能执行完毕
del();
if(s&&arrive-now)//堆中有元素,且在下一个进程到达前,当前进程有时间能执行。
heap[1].left-=arrive-now;
now=arrive;
insert(num,arrive,left,priority);
}
while(s)
del();
return 0;
}
3.//P1631 序列合并
//一看数据范围N<=100000,O(n^2)显然无法过关,需寻求O(nlogn)的算法
//样例很快模拟成功。
//堆http://www.cnblogs.com/TheRoadToTheGold/p/6238795.html该篇还行
//http://www.cnblogs.com/TheRoadToTheGold/p/6239034.html用堆解该题。
//算法来讲,这篇文章写得不错http://blog.csdn.net/ypxrain/article/details/54585916摘抄如下:
//其实算法很简单,将A与B序列从大到小排列,再将A序列第一项与B序列所有项加上入队得到初始队列,
//之后再比较A中第2项与B中所有项的和,如果有一个和比当前Sum的最大值(即Sum.top())还要大,就跳出,
//否则就弹出Sum.top(),入队。
//编码,样例通过,提交,全WA
//进行修改
//if(left<=s)
// k=h[k]<h[left]?left:k;// 1 k=h[t]<=h[left]?left:t;
// if(right<=s)
// k=h[k]<h[right]?right:k;//1 k=h[t]<=h[right]?right:t;找出 left right k中最大值
//提交,还是全WA,修改
//while(p>1&&k>h[p/2]){//2 此处写成 while(p>1&&h[p]>h[p/2]) 通过静态查找,才找出问题
//提交AC,对插入堆函数编写要小心。
#include <stdio.h>
int a[100000+100],b[100000+100],h[100000+100],ans[100000+100],s=0;
void insert(int k){//最大堆,在堆中插入元素
int p;
s++;
p=s;
while(p>1&&k>h[p/2]){//2 此处写成 while(p>1&&h[p]>h[p/2]) 通过静态查找,才找出问题
h[p]=h[p/2];
p/=2;
}
h[p]=k;
}
void adjust(int t){//t表示在堆中序号
int left=2*t,right=2*t+1,k=t,c;//k=t不能省
if(left<=s)
k=h[k]<h[left]?left:k;// 1 k=h[t]<=h[left]?left:t;
if(right<=s)
k=h[k]<h[right]?right:k;//1 k=h[t]<=h[right]?right:t;找出 left right k中最大值
if(k!=t){
c=h[k];
h[k]=h[t];
h[t]=c;
adjust(k);//递归
}
}
int delmax(){//删除堆中最大值,返回值为删除的最大值
int max=h[1];
h[1]=h[s];
s--;
adjust(1);
return max;
}
int main(){
int n,i,j;
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d",&a[i]);
for(i=1;i<=n;i++)
scanf("%d",&b[i]);
for(i=1;i<=n;i++)
insert(a[1]+b[i]);
for(i=2;i<=n;i++)
for(j=1;j<=n;j++){
if(h[1]<=a[i]+b[j])
break;
delmax();//删除最大值
insert(a[i]+b[j]);//插入新值
}
while(s)
ans[s]=delmax();
printf("%d",ans[1]);
for(i=2;i<=n;i++)
printf(" %d",ans[i]);
printf("\n");
return 0;
}
4.//P2085 最小函数值
//题意不明,样例的输入,如何得出输出的数据,
//该题若用堆,用最小堆即可解决。关键是题意不明。
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P2085 摘抄如下
/*
每个函数的a,b,c都是正数
所以每个抛物线的对称轴都是负数
所以每条抛物线在x>=1时都是增函数
所以fi(1)一定是该抛物线最小值
所以首先把所有的fi(1)都放到优先队列里面
每次直接输出优先队列的top值
然后把top值所对应的函数的x+1的值放到队列里面
循环n次就是答案
*/
//虽然上面用的是优先队列,但思路是一样的。
//困扰在于如何插入m个有效的数,而且算法复杂度不高。
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P2085 摘抄如下
//算法:用一个数组记录当前第i个函数自变量的值,初始化X[i]=1,每次从小根堆取出一个函数值时,
//使其对应的自变量的值增加,比如取出的是第i个,就X[i]++,这样就是一个O(n+m)的算法
//请注意:(x∈N*)表示,x=1,2,3,...
//样例很快通过,可惜洛谷 502 Bad Gateway 2017-7-4
//提交AC
#include <stdio.h>
#define maxn 10000+100
int s=0;
struct node1{
int a,b,c;
}d[maxn];//?
struct node2{
int v,x,a;//a表示序列
}heap[maxn],tmp;
int f(int x,int a,int b,int c){
return a*x*x+b*x+c;
}
void insert(struct node2 k){//最小堆
int p;
s++;
p=s;
while(p>1&&k.v<heap[p/2].v){
heap[p]=heap[p/2];
p/=2;
}
heap[p]=k;
}
void adjust(int t){//位置
int left=2*t,right=2*t+1,k=t;
if(left<=s)k=heap[k].v<heap[left].v?k:left;
if(right<=s)k=heap[k].v<heap[right].v?k:right;
if(k!=t){
tmp=heap[k];
heap[k]=heap[t];
heap[t]=tmp;
adjust(k);
}
}
int main(){
int n,m,a,b,c,i,j;
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++){
scanf("%d%d%d",&a,&b,&c);
d[i].a=a,d[i].b=b,d[i].c=c;
tmp.v=f(1,a,b,c),tmp.a=i,tmp.x=1;
insert(tmp);
}
for(i=1;i<=m;i++){
printf("%d ",heap[1].v);
heap[1].x++,j=heap[1].a,heap[1].v=f(heap[1].x,d[j].a,d[j].b,d[j].c);
adjust(1);
}
return 0;
}
2017-7-9 10:42 AC该单元
线段树树状数组基础
1.//P1198 [JSOI2008]最大数
//http://www.cnblogs.com/shadowland/p/5870339.html通过该文学习了线段树,特点是文章够短,代码够短。
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1198关于线段树的代码写得不错
//2017-7-13 12:12AC
#include <stdio.h>
#define INF 2000000000
#define M 200000
struct node{
int left,right,max;
}a[M*5];//5 M*4数组会越界
int max(int a,int b){
return a>b?a:b;
}
void build(int u,int left,int right){//自顶向下处理
int mid=(left+right)/2;
a[u].left=left,a[u].right=right,a[u].max=-INF;
if(left==right)return;//1 漏了此行。
build(u*2,left,mid);//左子树
build(u*2+1,mid+1,right);//右子树
}
void update(int u,int x,int v){//自顶向下处理
if(x>=a[u].left&&x<=a[u].right)a[u].max=max(a[u].max,v);//4 此处写成 a[u].left=left,a[u].right=right,a[u].max=max(a[u].max,v);
else return;
update(u*2,x,v);//4 此处写成 update(u*2,left,mid,v);
update(u*2+1,x,v);//4 此处写成 update(u*2+1,mid+1,right,v);
}
int query(int u,int left,int right){
if(a[u].left>right||a[u].right<left)return -INF;
if(a[u].left>=left&&a[u].right<=right)return a[u].max;
return max(query(u*2,left,right),query(u*2+1,left,right));//3 此处写成 return max(query(u,left,mid),query(u,mid+1,right));真是失策
}
int main(){
int m,d,i,t=0,x,len=0;//2 此处忘记对t初始化为0
char cmd[5];
scanf("%d%d",&m,&d);
build(1,1,m);//建树
for(i=1;i<=m;i++){
scanf("%s%d",cmd,&x);
if(cmd[0]=='Q'){
t=query(1,len-x+1,len);
printf("%d\n",t);
}else update(1,++len,(t+x)%d);
}
return 0;
}
2.//P1972 [SDOI2009]HH的项链
//http://hzwer.com/3007.html此文介绍得不错,摘抄如下:
//这题首先在线是没法做的,所以我们可以考虑离线算法
//首先记录下每种颜色的下一种颜色所在的位置
//将所有询问按照左端点进行排序
//将所有颜色的第一个点x a[x]++
//然后从左往右扫
//扫到一个点x将a[next[x]]++
//碰到一个询问l,r输出sum[r]-sum[l-1]
//其中sum是a数组的前缀和
//求前缀和可以用树状数组
//通过http://blog.csdn.net/mrcrack/article/details/61625530此文中的3.//p1908 逆序对重新学习了树状数组
//树状数组,写法固定,该题,a.left==b.left?a.right<b.right:a.left<b.left;相应的快排,编写不易,故第一次采用C++中的sort函数。
//2017-7-17 20:34 AC
#include <stdio.h>
#include <string.h>
#include <algorithm>
using namespace std;
#define maxn 1000000+100
int n,a[50100],p[maxn],next[50100],c[50100];//原来写成 int n,a[maxn],p[maxn],next[maxn],c[maxn];
struct node{
int left,right,id,ans;
}q[200100];//原来写成 q[maxn]
int cmp1(node a,node b){
return a.left==b.left?a.right<b.right:a.left<b.left;
}
int cmp2(node a,node b){
return a.id<b.id;
}
int lowbit(int x){//树状数组,固定写法
return x&-x;
}
void update(int x,int v){//树状数组,固定写法 ,更新数据
int i;
for(i=x;i<=n;i+=lowbit(i))
c[i]+=v;
}
int sum(int x){//树状数组,固定写法 ,查询数据 ,计算和
int i,ans=0;
for(i=x;i>0;i-=lowbit(i))
ans+=c[i];
return ans;
}
int main(){
int i,m,left,right,mx=0,ans;
memset(c,0,sizeof(c));
memset(p,0,sizeof(p));
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%d",&a[i]);
mx=max(mx,a[i]);
}
for(i=n;i>0;i--){//该程序,数据处理,最核心部分,希望后来者,跟踪该段代码进行理解
next[i]=p[a[i]];
p[a[i]]=i;
}
for(i=1;i<=mx;i++)
if(p[i])
update(p[i],1);
scanf("%d",&m);
for(i=1;i<=m;i++){
scanf("%d%d",&left,&right);
q[i].left=left,q[i].right=right,q[i].id=i;
}
sort(q+1,q+m+1,cmp1);
left=1;
for(i=1;i<=m;i++){
while(left<q[i].left){//后序重复元素处理,若当前元素不在q[i].left q[i].right之间,后序重复元素开始起作用
if(next[left])
update(next[left],1);
left++;
}
q[i].ans=sum(q[i].right)-sum(q[i].left-1);
}
sort(q+1,q+m+1,cmp2);
for(i=1;i<=m;i++)
printf("%d\n",q[i].ans);
return 0;
}
3.//P2023 [AHOI2009]维护序列
//与 P3373 【模板】线段树 2 思路基本一致
//样例通过,提交,测试点2-10WA 进行1 的改写,全部取模,还是测试点2-10WA,进行2 的改写,提交,还是测试点2-10WA
//进行3的修改,lazya[k]+=v;//3 此处写成 lazya[k]=v;大失水准.提交AC,错误,竟然不是核心代码,是异想不到的地方。2017-7-21 19:16AC
#include <stdio.h>
#include <string.h>
#define maxn 100100
long long p,c[maxn*4],lazya[maxn*4],lazyb[maxn*4];
void build(int left,int right,int k){//自顶向下,自左往右建树
int mid=(left+right)/2;
if(left==right){
scanf("%lld",&c[k]);//2 此处写成 scanf("%d",&c[k]);
return;
}
build(left,mid,2*k);
build(mid+1,right,2*k+1);
c[k]=(c[2*k]+c[2*k+1])%p;//1 c[k]=c[2*k]+c[2*k+1];
}
void down(int left,int right,int k){
int mid=(left+right)/2;
lazya[2*k]*=lazyb[k];
lazya[2*k]+=lazya[k];
lazya[2*k]%=p;
lazyb[2*k]*=lazyb[k];
lazyb[2*k]%=p;
c[2*k]*=lazyb[k];
c[2*k]+=(mid-left+1)*lazya[k];
c[2*k]%=p;
lazya[2*k+1]*=lazyb[k];
lazya[2*k+1]+=lazya[k];
lazya[2*k+1]%=p;
lazyb[2*k+1]*=lazyb[k];
lazyb[2*k+1]%=p;
c[2*k+1]*=lazyb[k];
c[2*k+1]+=(right-mid)*lazya[k];
c[2*k+1]%=p;
lazya[k]=0;
lazyb[k]=1;
}
void add(int left,int right,int k,int start,int end,int v){
int mid=(left+right)/2;
if(left>end||right<start)return;
if(start<=left&&right<=end){
c[k]+=(right-left+1)*v;
lazya[k]+=v;//3 此处写成 lazya[k]=v;大失水准
c[k]%=p;//1 添加
lazya[k]%=p;//1 添加
return;
}
down(left,right,k);
add(left,mid,2*k,start,end,v);
add(mid+1,right,2*k+1,start,end,v);
c[k]=(c[2*k]+c[2*k+1])%p;//1 c[k]=c[2*k]+c[2*k+1];
}
void mul(int left,int right,int k,int start,int end,int v){
int mid=(left+right)/2;
if(left>end||right<start)return;
if(start<=left&&right<=end){
c[k]*=v;
lazyb[k]*=v;
lazya[k]*=v;
c[k]%=p;//1 添加
lazyb[k]%=p;//1 添加
lazya[k]%=p;//1 添加
return;
}
down(left,right,k);
mul(left,mid,2*k,start,end,v);
mul(mid+1,right,2*k+1,start,end,v);
c[k]=(c[2*k]+c[2*k+1])%p;//1 c[k]=c[2*k]+c[2*k+1]
}
long long ask(int left,int right,int k,int start,int end){
int mid=(left+right)/2;
if(left>end||right<start)return 0;
if(start<=left&&right<=end)
return c[k]%p;
down(left,right,k);
return (ask(left,mid,2*k,start,end)+ask(mid+1,right,2*k+1,start,end))%p;
}
int main(){
int n,m,i,cmd,opx,opy,opv;
memset(lazya,0,sizeof(lazya));
scanf("%d%d",&n,&p);
for(i=1;i<=4*n;i++)
lazyb[i]=1;
build(1,n,1);
scanf("%d",&m);
for(i=1;i<=m;i++){
scanf("%d",&cmd);
switch(cmd){
case 1:
scanf("%d%d%d",&opx,&opy,&opv);
mul(1,n,1,opx,opy,opv);
break;
case 2:
scanf("%d%d%d",&opx,&opy,&opv);
add(1,n,1,opx,opy,opv);
break;
case 3:
scanf("%d%d",&opx,&opy);
printf("%lld\n",ask(1,n,1,opx,opy));
break;
}
}
return 0;
}
4.//P2161 [SHOI2009]Booking 会场预约
//https://www.luogu.org/record/lists?pid=P2161内存,时间效率极高的算法 Splay 伸展树
//很有兴趣进行学习。
//http://blog.csdn.net/skydec/article/details/20151805先从此文入手
//http://blog.csdn.net/qq_33184171/article/details/73549164 写得比较基础
//冰冻三尺,非一日之功,先快速解决该题,是第一要素,用set方法吧,顺便开始一些C++的痕迹。
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P2161学习set方法
//https://zhidao.baidu.com/question/279995268.html学习了set lower_bound方法
//http://blog.csdn.net/yas12345678/article/details/52601454学习了C++ set
//一直对为什么重载<而不是=或是>,心存疑虑,此文讲解不错,http://bbs.csdn.net/topics/390261324摘抄如下:
//肯定可以,C++的设计哲学之一就是使得程序在对待自定义类型时和内置类型必须是一致的(甚至自定义类型的支持更好)。所以,肯定是你程序的问题,如下:
//《C++标准程序库》中明确指出:“只要是assignable、copyable、comparable(根据某个排序准则)的型别T,都可以成为set或multiset的元素型别。”。其中,所谓的comparable指的是less,即可进行<比较。
//反之,则不被支持,所以,问题是,你的A是否支持上述三种语义?
//找了半天,总算,找了个该题set写得比较象样的程序http://blog.csdn.net/darost/article/details/54882225
//该题,用set难点在于 结构体 情况下 lower_bound()的使用,以下附图,帮助大家理解,当然,有STL大神 补充,更佳。

//从代码角度,该程序算是set 写得比较好懂的。
//2017-7-23 9:42 AC
#include <cstdio>
#include <set>
using namespace std;
struct node{
int left,right;
bool operator<(const node &v)const{//1 此处写成 bool operator<(const node &v)
if(right==v.right)
return left<v.left;
return right<v.right;
}
};
set<node> s;
int main(){
int n,i,cnt,left,right;
char cmd[5];
set<node>::iterator it;
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%s",cmd);
if(cmd[0]=='A'){
scanf("%d%d",&left,&right);
cnt=0;
while(1){
it=s.lower_bound((node){0,left});//建议读者画图理解该句,整个程序中最核心的代码,也是最难写得代码//1 此处写成 it=s.lower_bound(node{0,left});
if(it!=s.end()&&right>=it->left){
s.erase(it);
cnt++;
continue;
}
s.insert((node){left,right});//1 此处写成 s.insert(node{left,right});
break;
}
printf("%d\n",cnt);
}else
printf("%d\n",s.size());
}
return 0;
}
2017-7-23 9:50 AC该单元。
神奇的解法
1.//P1007 独木桥
//读完此题,发现很像蚂蚁那道题。
//士兵相遇,可以看成士兵穿越彼此。
#include <stdio.h>
int main(){
int L,n,x,i,x_min,x_max,a,b,t_min=0,t_max=0;
scanf("%d%d",&L,&n);
for(i=1;i<=n;i++){
scanf("%d",&x);
a=x-0;
b=L+1-x;
x_min=a>b?b:a;
x_max=a>b?a:b;
if(t_min<x_min)
t_min=x_min;
if(t_max<x_max)
t_max=x_max;
}
printf("%d %d\n",t_min,t_max);
}
2.//P1984 [SDOI2008]烧水问题
//http://www.cnblogs.com/zbtrs/p/5831475.html此文比较接近考场,摘抄如下:
//分析:一个很容易想到的思路就是把每杯水能传递的热量都给传递,考虑第i杯水,如果想要到100℃,
//那么从第1杯到第i-1杯水能给它热传递就热传递,这样可以发现从1到i-1杯水的温度是递增的,所以结果一定是最优的,
//然后把这个暴力打上去后超时......
//那么就要用一些特殊的方法了,注意到题目只给出了一个数n,而要求输出一堆东西,那么很显然,
//不是递推就是数学公式,加上数据有那么大,可以确定为数学公式,然后发现这个公式我推不出来,
//那么这个时候就要找规律了,手动模拟一下.
//为了方便起见,每杯水升1℃需要消耗1J,假设有4杯水,第一杯水需要消耗100J的能量,第二杯水需要消耗50J的能量,
//第三杯水需要消耗37.5J的能量,第四杯水需要消耗31.25J的能量,设第i杯水花费的能量为costi,
//那么cost2 = (1/2)cost1,cost3 = (3/4)cost2,cost4 = (5/6)cost3,然后发现规律,
//对于第i杯水而言,消耗的能量=costi-1 * (2*i - 1)/(2*i),然后一个循环就搞定了.数学规律有时候也要靠找规律找到啊!
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1984思路比较接近理科思维,看得出是经过,抽象,整理的,摘抄如下:
//推导:设沸腾温度为a
//则第一杯温度为a,需要加热t1=a
//第二杯可以中和的最高温度为a/2,需要加热t2=a/2
//第三杯可以中和的最高温度为t3=(a/4+a)/2=5a/8,需要加热t3=3a/8
//第四杯可以中和的最高温度为t4=((a/8+5a/8)/2+a)/2=11a/16,需要加热t4=5/16
//则t3/t2=3/4=1-1/4, t4/t3=5/6=1-1/6
//继续推导得t(n+1)/t(n)=1-1/2n
//经过推导,发现上述两种方法一致,思考过程如下图所示。
//2017-7-24 21:35 AC
#include <stdio.h>
int main(){
int n,i;
double ans,cost;
scanf("%d",&n);
cost=4200*100*1.0/n;
ans=cost;
for(i=2;i<=n;i++){
cost*=(2*(i-1)-1)*1.0/(2*(i-1));//1 此句写成 cost*=(2*i-1)*1.0/2*i;大失水准
ans+=cost;
}
printf("%.2lf",ans);
return 0;
}

3.//P2022 有趣的数
//此文写得不错,代码够短,http://www.cnblogs.com/shenben/p/5736624.html摘抄如下:
//由于答案可能非常大,所以这道题显然不能用枚举,即便用二分,时间复杂度{O[N(logN)^2]}也特别大。
//我们可以设所有字典序比K小的数中的第M-1个为X,N就等于K与X的最大值,怎么求X呢?
//当然是枚举。我们把所有字典序比K小的数分成无穷大个集合。
//集合Ai里的任意两个数j,k,都满足i=floor(log10(j))=floor(log10(k))(floor(a)表示取a的整数部分,
//log10(a)表示以10为底,以a为真的对数值),其中最大值为ai。我们可以发现,
//设K的左数第i位是pi,qi=∑pj*(i-j+1)(1<=j<=i),当j<=log10(K),|Aj|=qj-1,aj=qj-1;
//当j>log10(K),|Aj|=|A(j-1)|*10(请读者自己证明)。由此我们可求出X所在集合Ai,
//且X=ai+[M-∑|Aj|(1<=j<=i)]-1。求X所在集合的时间复杂度和求出X所在集合后求X的值的时间复杂度均为O[log10(N)],
//总的时间复杂度为O[log10(N)]。
//搜索了一通,找了个能看得懂的,http://www.cnblogs.com/grhyxzc/p/5742694.html摘抄如下:
//对于该题来说,我们只需考虑比K小的数就可以了,比K小的自然数中,比K小的字典序的个数=K-1。
//eg:
//对于456而言,从100~455 都可以,有456-100-1个。(更正456-100=356 mrcrack)
//从10~45 也可以 有(45-10-1) +1 //45是可以的,以为456还有后面的数,所以45也小于456(字典序)(更正45-10+1 =36 mrcrack)
//从1~4中也都可以,有(4-1-1)+1//原因同上 (更正4-1+1=4 mrcrack)
//(补充,故456位置为397 测试数据 输入:456 397 输出:456 mrcrack)
//由以上,我们便可以找出规律:比K字典序小的数等于ans=(K%10-1)//直到K=0;ans+=(t-1),因为除了位数与原数相同的的情况,等于是成立的,见以上标红部分。
//规律找到,然后逐渐扩大N,以K的10^i扩大,当ans>m时,ans=(k*10^i-(ans-(M-1)+1))//减出多余的部分。
//输入:456 397
//输出:456
//输入:456 397
//输出:1000
//1-45
//10-45
//100-456
//1000-(4560-1) 4560-1-1000+1=3560
//10000-(45600-1) 45600-1-10000=35600
//以 456 398 为例cnt=3560+396=3956 M-1=397 cnt-(M-1)=35599 (4560-1)-35599=1000 (4560-1)-(cnt-(M-1)) cnt-(M-1)多出的个数 由更高层完成故 通式为 (c-1)-(cnt-(M-1))
//按上述思路编写,提交,测试点9,14,16,34,48TLE ,进行1的修改,提交AC 2017-7-26 22:35
//程序特点:纯C语言编写,可以C或C++提交。 目标:大家花时间尽量能看懂的代码(跟踪程序,更容易看懂代码) 。
//题解:该程序的编写,建立在3个样例上(m-1指的是m的前一位),提供给大家:
//样例1
//输入:456 397
//输出:456
//样例2
//输入:456 398
//输出:1000
//样例3
//输入:10 10
//输出:0
//样例1:
//对于456而言,从100~455 都可以,有456-100=356个。
//从10~45 也可以 有45-10+1 =36个 //45是可以的,以为456还有后面的数,所以45也小于456(字典序)
//从1~4中也都可以,有更正4-1+1=4//原因同上
//最大数到456,比456字典序小的个数为(456-100+1)-1+(45-10+1)+(4-1+1)个,即 (456-100+1)+(45-10+1)+(4-1+1)-1个,即396个,getcount函数因此算法编出
//样例2:
//同样例1思路,但第397个数在小于456里面找不到了,只能从1000~(4560-1)里面进行寻找,可寻找的数目(4560-1)-1000+1=3560个,while(cnt<m-1)里面的内容由此编出
//多算个数cnt-(m-1),如样例2,cnt=396+3560 m-1=398-1 cnt-(m-1)=3560+396-(398-1)=3599。
//多算个数的数字,属 1000~(4560-1)区间,故m-1位置处数字是,(4560-1)-(3560+396-(398-1))=1000, 过m-1位置处数字是(c-1)-(cnt-(m-1))
//在m-1,m位数字间取最大值,即为答案,如样例2,1000 456最大值为1000;样例1 455 456 最大值为456
//样例3的原因是,10最多只能有1字典序比10小,再也找不到满足题意的其他数,字典序比10小了,故要添加 k==base&&cnt<m-1的判断,否则 测试点9,14,16,34,48TLE
#include <stdio.h>
long long base,cnt=0;//如456 base=100
void getcount(long long x){//获得小于x的,且字典序小于x的数的个数
long long base1=1,x1=x,x2=x;
while(x1){//数出x的位数,如456 计算得出base1=100
x1/=10;
base1*=10;
}
base1/=10;//因为多 一次*10,故此处 一次/10
base=base1;//如456 base=100
while(x2){//最大数到456,比456字典序小的个数为(456-100+1)-1+(45-10+1)+(4-1+1)个,即 (456-100+1)+(45-10+1)+(4-1+1)-1个,即396个,getcount函数因此算法编出
cnt+=x2-base1+1;
x2/=10;
base1/=10;
}
cnt-=1;//cnt计算小于x,且字典序小于x的数的个数
}
long long max(long long a,long long b){
return a>b?a:b;
}
int main(){
long long k,m,c,p;
scanf("%lld%lld",&k,&m);
getcount(k);
if(cnt>m-1||k==base&&cnt<m-1){//1 此处写成 if(cnt>m-1)漏了一种情况 10 10 无输出结果。
printf("0\n");//无解
return 0;
}
c=k,p=k-base;
while(cnt<m-1){//计算大于x,且字典序小于x的数的个数。 //同样例1思路,但第397个数在小于456里面找不到了,只能从1000~(4560-1)里面进行寻找,可寻找的数目(4560-1)-1000+1=3560个,while(cnt<m-1)里面的内容由此编出
c*=10;
p*=10;
cnt+=p;
}
printf("%lld\n",max(k,(c-1)-(cnt-(m-1))));
return 0;
}
4.//P2320 [HNOI2006]鬼谷子的钱袋
//http://hzwer.com/1211.html写得不错,摘抄如下:
//找第一个比n大的2^k数
//http://www.cnblogs.com/zxhl/p/5599062.html摘抄如下:
//任意一个数都可以用二进制组合表示 所以答案就是log2(n)+1;
//http://blog.csdn.net/rlt1296/article/details/53068743代码也写得不错
//以m=10为例,钱袋数目,及钱袋金币计算如下图:
//2017-7-24 9:14AC
#include <stdio.h>
int main(){
int m,ans[35],i;
scanf("%d",&m);
ans[0]=0;//存储数据长度
while(m){
if(m%2)//非0
ans[++ans[0]]=m/2+1;
else
ans[++ans[0]]=m/2;
m/=2;
}
printf("%d\n%d",ans[0],ans[ans[0]]);
for(i=ans[0]-1;i>0;i--)
printf(" %d",ans[i]);
printf("\n");
}
2017-7-26 23:26 AC 该单元

BOSS战-提高综合练习2
1.//P1901 发射站
//快排,自小到大
//自小到大扫描一遍数据,处理,同时找出最大值。
//提交,测试点1-7,9-10WA。
//重读题目,发现误解题意。
//题意本身意思:并且发出的能量只被两边最近的且比 它高的发射站接收。每个发射站发来的能量有可能被 0 或 1 或 2 个其他发射站所接受
//http://www.cnblogs.com/zbtrs/p/5869978.html此文代码写得不错
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P1901思路比较清晰,摘抄如下:
//我们先来考虑这个问题的一半。假如每个发射站只会向左发射信号,如果第i个发射站比它左边的发射站都高,那么第i个发射站左边的站点就不可能收到右边站点发送的信号。这让我们想到了单调栈。
//我们维护一个栈顶向栈底递增的单调栈,每次一个元素入栈之后,设此时栈顶为top,那么该元素发射的信号只能被位于top-1的站点收到。
//向左发射信号的过程做完后,再做一遍向右发射信号的过程。这样我们就能找出哪个站点收到的信号最多了。
//通过该题,学习了单调栈的用法。
//2017-7-29 22:30AC
#include <stdio.h>
#include <string.h>
#define maxn 1000000+100
int h[maxn],v[maxn],stack[maxn],ans[maxn],top=0;//stack[]存储序列位置
void push(int x){//栈自底向顶递减
while(top&&h[stack[top]]<=h[x])//1 此处写成 while(top&&h[stack[top]]>=h[x])
top--;
if(top)
ans[stack[top]]+=v[x];
stack[++top]=x;
}
int main(){
int n,i,max=0;
memset(ans,0,sizeof(ans));
scanf("%d",&n);
for(i=1;i<=n;i++)
scanf("%d%d",&h[i],&v[i]);
for(i=1;i<=n;i++)//自左往右扫描,信号自右向左传递
push(i);
top=0;
for(i=n;i>=1;i--)////自右往左扫描,信号自左向右传递
push(i);
for(i=1;i<=n;i++)
max=max>ans[i]?max:ans[i];
printf("%d\n",max);
return 0;
}
2.//P1314 聪明的质监员
NOIP 2011 提高组 复赛 day2 qc 聪明的质监员
1.题目看看样子,感觉有背包问题的味道,动态规划是免不了了。
2.当务之急,是弄明白题意,吃透样例。
3.读了半天题,发现样例的输出推不出,归结为Yi的计算西格玛看不懂怎么算,这种西格玛的写法,j加在下方,没有值,第一次看到,看不懂啊。
4.参考了http://www.doc88.com/p-8572941809341.html才弄明白题意Yi=(区间符合条件矿石个数和)*(区间符合条件矿石价格和)
5.补充一点,西格玛的优先级高于乘除。
6.如果没有时间限制,此题还是比较简单的,两个循环搞定,有些类似冒泡算法。
7.看到数据范围S<=10^12,描述要采用long long 类型了。
8.原以为矿石是按重量大小自小到大输入的,仔细搜索,没有,那么排序不可避免,冒泡排序排除,时间复杂度满足不了,那么快速排序上。较好的时间复杂度O(nlogn).
9.转念一想,拍好序有啥用呢,区间限制,拍好序的矿石与区间无法对应。
10.这样吧,为了熟悉程序,第一目标30分,第二目标50分,开始编程。
11.比较好奇,S必须用long long ,怎么输入输出数据S,Linux与windows有很大不同。本人采用%lld
12.很明显Yi(Wi)是减函数。考虑遍历一次所有矿石,找出重量最轻,最重的数据。在重量区间进行每次重量加1的排查,不现实,数量太大,想来想去,没有比二分法更好了。
13.w=0,w=max两个值,猜提交有20分,提交0分,14个数据WA,6个数据TLE,那么好吧,老老实实讨论一般的情况。
14.代码写好,样例通过,提交40分,前8个数据AC,9,14WA,10-13,15-20TLE
15.再看数据范围,发现m与n是同一数量级,矿石输入未说明按重量自小到大,那么以目前的算法TLE不可避免。
16.受http://blog.csdn.NET/visors/article/details/50813986(后查证long long f(int W)函数有误,
w[i]>W,应该成w[i]>=W,不建议读者跟踪此文章代码,)启发,
准备改写long long f(int w)函数。当然,此时突然感觉此法
其实本人在NOIP 2011 提高组 复赛i] day1 选择客栈 中用过,
不过,在此处却没想到,实在可惜。思想有些类似最长上升子序列。17.开始改造,提交,全WA,马上知道,TLE这关过了,重读题目,发现//区间处理 ,区间的含义是包括了li ,故应减li-1,此处容易出错 ,修改,提交55分,明白应该是二分法,这块出问题,开始修改。
18.对二分法找不到的情况进行模拟,对二分法的认识更深刻了。
19.多次提交都是60分,无奈祭出对拍法宝,一度怀疑是二分法的问题,随着跟踪的深入,才发现是long long f(int w)函数写得有问题。
20.提交还是60分,找了http://hzwer.com/5061.html来研究。
21.程序跟到最后,发现思路全无问题,问题出在取绝对值函数abs上,跳进stdlib.h文件才发现,对于long long 类型,函数应写成llabs,彻底服了,网上似乎没有人提到这个问题,当然,用C编的人极少。
22.前面的种种问题,竟然是栽在abs上,对于long long 应改成llabs。好吧,一天时间,就是因为这个函数,希望对后来者有用。提交AC。
23.此题还学到一招,long long 可以在C++里用cin ,cout进行输入输出,可以回避掉scanf,printf的windows,linux下的不同输入方式的问题。
2017-1-14 16:11
附上AC代码,编译环境Dev-C++4.9.9.2
//2011 qc
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define inf 9999999
struct node1{
int w;
int v;
}ks[200000+10];
struct node2{
int li;
int ri;
}qj[200000+10];
struct node3{
long long count;
long long v;
}sum[200000+10];
int n,m;
long long f(int w){
long long y;
long long count,v;
int i;
int li,ri;
y=0;
memset(sum,0,sizeof(sum));
for(i=1;i<=n;i++){//一次扫描即可。
sum[i]=sum[i-1];
if(ks[i].w>=w){
sum[i].count++;
sum[i].v+=ks[i].v;
}
}
for(i=1;i<=m;i++){//区间处理 ,区间的含义是包括了li ,故应减li-1,此处容易出错
li=qj[i].li;
ri=qj[i].ri;
count=sum[ri].count-sum[li-1].count;
v=sum[ri].v-sum[li-1].v;
y+=count*v;
}
return y;
}
int main(){
int i,j,k;
long long s;
long long count;
long long v;
long long y;
int w;
long long ans;
int min,max,mid;
scanf("%d%d%lld",&n,&m,&s);
for(i=1;i<=n;i++)
scanf("%d%d",&ks[i].w,&ks[i].v);
for(i=1;i<=m;i++)
scanf("%d%d",&qj[i].li,&qj[i].ri);
min=0;
max=-inf;
for(i=1;i<=n;i++){
if(ks[i].w>max)
max=ks[i].w;
}
if((y=f(max))>=s)
ans=y-s;
else if((y=f(min))<=s)
ans=s-y;
else{
while(min<=max){
mid=(min+max)/2;
y=f(mid);
if(y>s)
min=mid+1;
else if(y<s)
max=mid-1;
else
break;
}
if(min<=max)
ans=0;
else{
if(llabs(f(min)-s)>=llabs(f(max)-s))
ans=llabs(f(max)-s);
else
ans=llabs(f(min)-s);
}
}
printf("%lld\n",ans);
return 0;
}
附上40分代码,编译环境Dev-c++4.9.9.2
//2011 qc
#include <stdio.h>
#include <stdlib.h>
#define inf 9999999
struct node1{
int w;
int v;
}ks[200000+10];
struct node2{
int li;
int ri;
}qj[200000+10];
int n,m;
long long f(int w){
long long y;
int count,v;
int i,j;
y=0;
for(i=1;i<=m;i++){
count=0;
v=0;
for(j=qj[i].li;j<=qj[i].ri;j++){
if(ks[j].w>=w){
count++;
v+=ks[j].v;
}
}
y+=count*v;
}
return y;
}
int main(){
int i,j,k;
long long s;
int count;
int v;
long long y;
int w;
long long ans;
int min,max,mid;
scanf("%d%d%lld",&n,&m,&s);
for(i=1;i<=n;i++)
scanf("%d%d",&ks[i].w,&ks[i].v);
for(i=1;i<=m;i++)
scanf("%d%d",&qj[i].li,&qj[i].ri);
min=0;
max=-inf;
for(i=1;i<=n;i++){
if(ks[i].w>max)
max=ks[i].w;
}
if((y=f(max))>=s)
ans=y-s;
else if((y=f(min))<=s)
ans=s-y;
else{
while(min<=max){
mid=(min+max)/2;
if(f(mid)>=s&&f(mid+1)<=s)
break;
if(f(mid)>s)
min=mid;
else
max=mid;
}
if(abs(f(mid)-s)>=abs(f(mid+1)-s))
ans=abs(f(mid+1)-s);
else
ans=abs(f(mid)-s);
}
// printf("y=%lld s=%lld\n",y,s);
printf("%lld\n",ans);
return 0;
}
3.//P2144 [FJOI2007]轮状病毒
//http://blog.csdn.net/kiana810/article/details/20305131比较接近考试时的思路,摘抄如下:
//做这题颇有感触啊,感觉省选题目画半个小时画图不吃亏。
//看到题目,反正我的第一反应是递推。递推就要有递推式,于是我花了将近20分钟,画出n=1~5情况的轮状病毒个数,结果如下:
//1 5 16 45 121……
//乍一看,奇数项是完全平方数,偶数项是5的倍数,我想的是往平方数上靠,于是转化成了这样:
//1*1 3*3-4 4*4 7*7-4 11*11……
//1 3 4 7 11……
//就是这样,原来是个变形的Fibonacci数列,前两项为1和3,然后对每一项平方,如果是偶数项就减4,AC~
//递推式:F[n]=f[n]*f[n]-4*(n+1 mod 2),f[n]=f[n-1]+f[n-2],f[1]=1,f[2]=3
//对了,此题正解是基尔霍夫矩阵,然后优化成另一个递推式。虽然我的答案可能不是出题人想要的,但这一道题让我明白了勤于猜想的力量。
//【代码】
//既然是Fibonacci变形还要平方,n最大为100,自然上高精度。
//https://wenku.baidu.com/view/64d69e3143323968011c9225.html通过此文学习基尔霍夫矩阵
//https://wenku.baidu.com/view/d027e87101f69e3143329425.html?re=view通过此文学习基尔霍夫矩阵
//http://vfleaking.blog.163.com/blog/static/17480763420119685112649/此文有详细推导
//http://m.blog.csdn.net/huangzhengdoc/article/details/53365145代码写得够短
//轮状病毒的方案数满足递推式F(n) = 3 * F(n - 1) - F(n - 2) + 2,其中F(1) = 1, F(2) = 5写高精度算法
//简单修改,提交,一次性AC,2017-8-10 21:32
#include <stdio.h>
#include <string.h>
int f[110][110];
void mul(int x,int k){
int i;
f[x][0]=f[x-1][0];
for(i=1;i<=f[x-1][0];i++){
f[x][i]+=3*f[x-1][i];
f[x][i+1]+=f[x][i]/10;
f[x][i]%=10;
}
if(f[x][i]!=0)
f[x][0]=i;
}
void add(int x,int k){
int i;
f[x][1]+=k;
for(i=1;i<=f[x][0];i++){
f[x][i+1]+=f[x][i]/10;
f[x][i]%=10;
}
if(f[x][i]!=0)
f[x][0]=i;
}
void sub(int x){
int i;
for(i=1;i<=f[x-2][0];i++){
f[x][i]-=f[x-2][i];
if(f[x][i]<0){
f[x][i]+=10;
f[x][i+1]--;
}
}
while(f[x][f[x][0]]==0)//退位处理
f[x][0]--;
}
int main(){
int n,i;
memset(f,0,sizeof(0));
scanf("%d",&n);
f[1][0]=1,f[1][1]=1,f[2][0]=1,f[2][1]=5;//初始化f[1],f[2] ,f[1][0] f[2][0]存储数据长度
for(i=3;i<=n;i++){
mul(i,3);
add(i,2);
sub(i);
}
for(i=f[n][0];i>=1;i--)
printf("%d",f[n][i]);
printf("\n");
return 0;
}
4.//P1073 最优贸易
//NOIP 2009 提高组 复赛 trade 最优贸易
//http://blog.csdn.net/Qantun_Mechanics/article/details/51265515此文写得不错 ,摘抄如下:
//这个题目的解题思路比较多我就用了最蠢的跑两边spfa的做法写的。
//首先看题目以后我们知道这个题目一定是贪心,贪心的思路也很简单就是在最便宜的地方买商品在最贵的地方卖出去赚取差价,但是如果我们直接比较出最大值最小值做差是有问题的,当然不可能这个简单这个题目是当年的压轴题啊。这里写图片描述这么简单怎么玩。【虽然实际上也不难】因为那个人在不断的往前面走并在前面买东西在后面卖,所以我就把原来的边拆了建在两个图上。把所有的边正向建一张图,然后把边反过来再建一次,这样我原来的图就有两个了,于是我在正向的图上跑一边SPFA**不断更新从1到该点的最小值然后我再在反向的图上面跑第二遍SPFA然后更新最大值**并且把每个点的最大值与最小值做差来更新答案。这样就是正确的姿势啦。
//【证明】因为我们正向的跑了一边spfa更新最小值就相当于把起点到每个点的最小值求出来了,然后我第二遍spfa就做了两件事情第一个证明了连通性【因为我这个题目中有一些路是单向的,所以说可能某些点买的价格特别低或者特别高,但是我去的那儿是陷阱,你进去了就出不来了这样你的答案就是错的了,所以我把图反过来建这样你从终点可以反着跑到这个点也就代表这个点可以正着跑到终点,这就相当于证明了连通性】
//第二个事情就是不断的货比三家,计算利润和差值。
//http://hzwer.com/1144.html此文代码写得不错。
//邻接矩阵爆内存,只能邻接表,一个正向表,统计到达该点的最小值,一个反向表,统计该点到终点的最大值。
//感慨,有段时间没接触图了,确实有一定遗忘,spfa确实是重头戏,需要经常练习。2017-8-12 22:40 AC
//该题有句话,很关键:输入数据保证 1 号城市可以到达 n 号城市。
#include <stdio.h>
#include <string.h>
int head1[100000+100],head2[100000+100],cnt1=0,cnt2=0,mn[100000+100],mx[100000+100],p[100000+100],q[100000*10],inq[100000+100],n;//mn[]最小值 到达该点的最小值,mx[]最大值 该点到终点的最大值,p[]价格 q[]队列inq[]是否在队列中 n 点的个数
struct node{
int to,next;//to下一个节点,next下一条边
}e1[500000*2+100],e2[500000*2+100];//1 注意,正向图,反向图存储在不同空间。
int min(int a,int b){
return a>b?b:a;
}
int max(int a,int b){
return a>b?a:b;
}
void addedge(int u,int v){
cnt1++,e1[cnt1].next=head1[u],e1[cnt1].to=v,head1[u]=cnt1;//正向图
cnt2++,e2[cnt2].next=head2[v],e2[cnt2].to=u,head2[v]=cnt2;//反向图
}
void spfa1(){//找最小值
int h=0,t=0,u,v,i;
memset(inq,0,sizeof(inq));
q[t]=1;
t++;
inq[1]=1;
mn[1]=p[1];
while(h<t){
u=q[h];
inq[u]=0;
for(i=head1[u];i;i=e1[i].next){
v=e1[i].to;
if(mn[u]<mn[v]||p[v]<mn[v]){
mn[v]=min(mn[u],p[v]);
if(!inq[v]){
q[t]=v;
t++;
inq[v]=1;
}
}
}
h++;
}
}
void spfa2(){//找最大值
int h=0,t=0,u,v,i;
memset(inq,0,sizeof(inq));
q[t]=n;
t++;
inq[n]=1;
mx[n]=p[n];
while(h<t){
u=q[h];
inq[u]=0;
for(i=head2[u];i;i=e2[i].next){
v=e2[i].to;
if(mx[u]>mx[v]||p[v]>mx[v]){
mx[v]=max(mx[u],p[v]);
if(!inq[v]){
q[t]=v;
t++;
inq[v]=1;
}
}
}
h++;
}
}
int main(){
int m,i,x,y,z,ans=0;
memset(head1,0,sizeof(head1));
memset(head2,0,sizeof(head2));
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++){
scanf("%d",&p[i]);
mn[i]=1000;
mx[i]=-1;
}
for(i=1;i<=m;i++){
scanf("%d%d%d",&x,&y,&z);
addedge(x,y);
if(z==2)
addedge(y,x);
}
spfa1();
spfa2();
for(i=1;i<=n;i++)
ans=max(ans,mx[i]-mn[i]);//找出最大差价
printf("%d\n",ans);
return 0;
}
2017-8-12 22:48 AC 该单元
提高模板-nlogn数据结构
1.//P3374 【模板】树状数组 1//有了积累,该题,就是菜题了。
//树状数组,写法极其固定
//2017-7-18 9:15 AC
#include <stdio.h>
#include <string.h>
#define maxn 500000+100
int n,c[maxn];
int lowbit(int x){
return x&-x;
}
void update(int x,int v){
int i;
for(i=x;i<=n;i+=lowbit(i))
c[i]+=v;
}
int sum(int x){
int i,ans=0;
for(i=x;i>0;i-=lowbit(i))
ans+=c[i];
return ans;
}
int main(){
int i,m,v,cmd,x,y,ans;
memset(c,0,sizeof(c));
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++){
scanf("%d",&v);
update(i,v);
}
for(i=1;i<=m;i++){
scanf("%d%d%d",&cmd,&x,&y);
switch(cmd){
case 1:
update(x,y);
break;
case 2:
ans=sum(y)-sum(x-1);
printf("%d\n",ans);
break;
}
}
return 0;
}
2.//P3368 【模板】树状数组 2
//也是菜题一道,有了积累,现在这些题,真是容易。
//树状数组,写法极其固定。
//提交,测试点2,5-10TLE,不敢想象。
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P3368摘抄如下:
//这模板题名字就是树状数组..干嘛用线段树..代码还贼长..
//这里介绍树状数组+差分思想,算是对下面大神的补充吧。
//何为差分
//现在我们有一个从小到大的数列a[]
// a 1 3 6 8 9
//然后还有一个差分数组b[]
// b 1 2 3 2 1
//相信某些小伙伴已经看出端倪了..这里b[i]=a[i]-a[i-1],我令a[0]=0,故b[1]=a[1]。
//拥有了b数组,我们就可以很简单的求出bit[]中任意一个数,只需bit[i]=sigma(k=1 to i) b[k](这个很好推吧..)
//我觉得现在该有人说我zz了..何必不直接查询a[i]而是找这么麻烦一个方法..这里我们转回正题!别忘了,题目要我们进行区间修改..
//我们知道,树状数组对于单点值的修改十分方便(不懂的去看树状数组1),对于区间的修改就比较尴尬..而我们又不想敲死长的线段树..怎么办呢,这时候差分就显出优势
//还是上面的a[]和b[],现在我们使区间[2,4]的所有数均+2,则a[]/b[]变为
// a 1 5 8 10 9
// b 1 4 3 2 -1
//事实上,这里只有b[2]和b[5]发生了变化,因为区间内元素均增加了同一个值,所以b[3],b[4]是不会变化的。
//这里我们就有了第二个式子:对于区间[x,y]的修改(增加值为d)在b数组内引起变化的只有 b[x]+=d,b[y+1]-=d。(这个也很好推的..)
//这样,我们就把树状数组的软肋用差分解决了。
//采用上述思想,很快程序编写成功,提交AC。2017-7-18 10:30
#include <stdio.h>
#include <string.h>
#define maxn 500100
int n,c[maxn];
int lowbit(int x){
return x&-x;
}
void update(int x,int v){
int i;
for(i=x;i<=n;i+=lowbit(i))//1 写成 for(i=x;i<=n;i+=lowbit(x))有失水准
c[i]+=v;
}
int sum(int x){
int i,ans=0;
for(i=x;i>0;i-=lowbit(i))//1 写成 for(i=x;i<=n;i+=lowbit(x))有失水准
ans+=c[i];
return ans;
}
int main(){
int i,m,cmd,x,y,k,first,second;
memset(c,0,sizeof(c));
scanf("%d%d",&n,&m);
scanf("%d",&first);
update(1,first);//b[1]
for(i=2;i<=n;i++){
scanf("%d",&second);
update(i,second-first);//b[i]=a[i]-a[i-1]
first=second;
}
for(i=1;i<=m;i++){
scanf("%d",&cmd);
switch(cmd){
case 1:
scanf("%d%d%d",&x,&y,&k);
update(x,k);
update(y+1,-k);
break;
case 2:
scanf("%d",&x);
printf("%d\n",sum(x));
break;
}
}
return 0;
}
//P3372 【模板】线段树 1
//调了会,样例通过,提交AC 2018-5-8 收获是 对 线段树 理解更深刻了
#include <stdio.h>
#include <string.h>
#define maxn 100100
#define LL long long
LL n,m,lazy[4*maxn],ans,max_k=-999999999;
struct node{
LL left,right,v;
}q[4*maxn];
void build(LL k,LL left,LL right){
LL mid=(left+right)/2;
q[k].left=left,q[k].right=right;
if(q[k].left==q[k].right){
scanf("%lld",&q[k].v);
if(max_k<k)max_k=k;//判断最大节点位置
return ;
}
build(2*k,left,mid);
build(2*k+1,mid+1,right);
q[k].v=q[2*k].v+q[2*k+1].v;
}
void down(LL k){
LL v=lazy[k];
//此处多写了此句q[k].v+=(q[k].right-q[k].left+1)*v;
if(2*k<=max_k){//判断有无越界
lazy[2*k]+=v;
q[2*k].v+=(q[2*k].right-q[2*k].left+1)*v;//漏了此句
}
if(2*k+1<=max_k){//判断有无越界
lazy[2*k+1]+=v;
q[2*k+1].v+=(q[2*k+1].right-q[2*k+1].left+1)*v;//漏了此句
}
lazy[k]=0;
}
void query(LL k,LL left,LL right){
LL mid=(q[k].left+q[k].right)/2;//此处写成 LL mid=(left+right)/2;
if(left<=q[k].left&&q[k].right<=right){
ans+=q[k].v;
return ;
}
if(lazy[k])down(k);
if(left<=mid)query(2*k,left,right);
if(right>=mid+1)query(2*k+1,left,right);
}
void add(LL k,LL left,LL right,LL v){
LL mid=(q[k].left+q[k].right)/2;//此处写成 LL mid=(left+right)/2;
if(left<=q[k].left&&q[k].right<=right){
q[k].v+=(q[k].right-q[k].left+1)*v;
lazy[k]+=v;//漏了此句
return ;
}
if(lazy[k])down(k);
if(left<=mid)add(2*k,left,right,v);//此处写成 query(2*k,left,right)昏招
if(right>=mid+1)add(2*k+1,left,right,v);//此处写成 query(2*k+1,left,right)昏招
q[k].v=q[2*k].v+q[2*k+1].v;
}
int main(){
LL i,cmd,x,y,v;
scanf("%lld%lld",&n,&m);
build(1,1,n);
memset(lazy,0,sizeof(lazy));
while(m--){
scanf("%lld",&cmd);
if(cmd==2){
ans=0;
scanf("%lld%lld",&x,&y);
query(1,x,y);
printf("%lld\n",ans);
}else{//cmd==1
scanf("%lld%lld%lld",&x,&y,&v);
add(1,x,y,v);
}
}
return 0;
}
3.//P3372 【模板】线段树 1
//http://www.cnblogs.com/thmyl/p/6838066.html此文代码写得比较短,进行学习研究。
/*感觉好久没写线段树了,这是一个只牵扯到区间修改和区间查询的线段树模板,需要用懒标记,别忘开longlong*/
//http://www.cnblogs.com/Booble/archive/2010/10/11/1847793.html通过此文对线段树 Lazy-Tag进行学习
//https://www.douban.com/note/273509745/此文关于Lazy-Tag也写得不错,摘抄如下:
//在此通俗的解释我理解的Lazy意思,比如现在需要对[a,b]区间值进行加c操作,那么就从根节点[1,n]开始调用update函数进行操作,如果刚好执行到一个子节点,它的节点标记为rt,这时tree[rt].l == a && tree[rt].r == b 这时我们可以一步更新此时rt节点的sum[rt]的值,sum[rt] += c * (tree[rt].r - tree[rt].l + 1),注意关键的时刻来了,如果此时按照常规的线段树的update操作,这时候还应该更新rt子节点的sum[]值,而Lazy思想恰恰是暂时不更新rt子节点的sum[]值,到此就return,直到下次需要用到rt子节点的值的时候才去更新,这样避免许多可能无用的操作,从而节省时间 。
//采用跟踪的方式,研究了代码。
//提交,测试点2,9,10RE ,进行4 修改,还是 测试点2,9,10RE
//打印 printf("maxn*4=%d\n",maxn*4); #define maxn 100000+100 发现是100400,啊,这是潜在的漏洞,弄明白了.
//进行5修改 提交AC 2017-7-20 17:11
#include <stdio.h>
#include <string.h>
#define maxn 100100//#define maxn 100000+100
struct node{
int left,right;
long long v;
}q[maxn*4];
long long lazy[maxn*4],ans;
void build(int left,int right,int k){//建树,自顶向下,从左往右
int mid=(left+right)/2;
q[k].left=left,q[k].right=right;
if(q[k].left==q[k].right){
scanf("%lld",&q[k].v);
return ;
}
build(left,mid,2*k);
build(mid+1,right,2*k+1);
q[k].v=q[2*k].v+q[2*k+1].v;
}
void down(int k){
long long v=lazy[k];//2 此处写成 int v=lazy[k];
q[2*k].v+=(q[2*k].right-q[2*k].left+1)*v;
q[2*k+1].v+=(q[2*k+1].right-q[2*k+1].left+1)*v;
lazy[k]=0;
lazy[2*k]+=v;
lazy[2*k+1]+=v;
}
void add(int left,int right,long long v,int k){//自顶向下更新 4 int v
int mid=(q[k].left+q[k].right)/2;
if(left<=q[k].left&&q[k].right<=right){
q[k].v+=(q[k].right-q[k].left+1)*v;
lazy[k]+=v;
return;
}
if(lazy[k])down(k);
if(left<=mid)add(left,right,v,2*k);
if(right>mid)add(left,right,v,2*k+1);
q[k].v=q[2*k].v+q[2*k+1].v;//1 漏了此句
}
void ask(int left,int right,int k){
int mid=(q[k].left+q[k].right)/2;//3 此处写成 int mid=(left+right)/2;
if(left<=q[k].left&&q[k].right<=right){
ans+=q[k].v;
return;
}
if(lazy[k])down(k);
if(left<=mid)ask(left,right,2*k);
if(right>mid)ask(left,right,2*k+1);
}
int main(){
int n,m,i,cmd,opx,opy;//4 int n,m,i,cmd,opx,opy,opv;
long long opv;//4 添上该句
memset(lazy,0,sizeof(lazy));
scanf("%d%d",&n,&m);
build(1,n,1);
for(i=1;i<=m;i++){
scanf("%d",&cmd);
switch(cmd){
case 1:
scanf("%d%d%lld",&opx,&opy,&opv);//4 scanf("%d%d%d",&opx,&opy,&opv);
add(opx,opy,opv,1);
break;
case 2:
scanf("%d%d",&opx,&opy);
ans=0;
ask(opx,opy,1);
printf("%lld\n",ans);
break;
}
}
return 0;
}
//P3372 【模板】线段树 1
//枚举的方式,猜测70分。
//果然,提交70分,测试点8,9,10 TLE 2018-5-7 18:01
#include <stdio.h>
#define maxn 100100
#define LL long long
LL a[maxn];
int main(){
LL n,m,i,j,cmd,x,y,k,sum;
scanf("%lld%lld",&n,&m);
for(i=1;i<=n;i++)scanf("%lld",&a[i]);
while(m--){
scanf("%lld",&cmd);
if(cmd==1){
scanf("%lld%lld%lld",&x,&y,&k);
for(i=x;i<=y;i++)a[i]+=k;
}else{
sum=0;
scanf("%lld%lld",&x,&y);
for(i=x;i<=y;i++)sum+=a[i];
printf("%lld\n",sum);
}
}
return 0;
}
4.//P3373 【模板】线段树 2
//https://www.luogu.org/wiki/show?name=%E9%A2%98%E8%A7%A3+P3373此文写得不错
//线段树多个lazy标记的应用。
//每个点上的标记表示自己儿子要乘或加上多少。
//标记下放时,儿子节点的add标记先乘上父亲节点的乘标记再加上父亲节点的加标记(因为父亲节点的加标记已经乘上了一些乘标记了,不需要再乘一次)
//儿子节点的值同上。
//儿子节点的乘标记直接乘上父亲节点的乘标记。
//修改值的时候要根据下放标记与修改值的先后次序进行微调。
//就是这样。
//程序编写, 程序 一直出现停止工作 ,查了好久,竟然不是核心算法的问题, 而是scanf("%d%d",&opx,&opy);//2 此处写成 scanf("%d%d%d",&opx,&opy); 程序 一直出现停止工作
//该题,编写,线段树,Lazy-tag理解更上一台阶,当然,还有些模糊,日后还是要来处理该问题。
//提交,测试点2,5-10WA. 一查: for(i=1;i<=4*n;i++)//3 此处写成 for(i=1;i<=n;i++)提交AC
//2017-7-21 17:44 AC
#include <stdio.h>
#include <string.h>
#define maxn 100100
int p;
long long c[maxn*4],lazya[maxn*4],lazyb[maxn*4];//lazya 加懒标记 lazyb 乘懒标记
void build(int left,int right,int k){//建树(线段树),自上而下,自左往右
int mid=(left+right)/2;
if(left==right){
scanf("%d",&c[k]);
return;
}
build(left,mid,2*k);
build(mid+1,right,2*k+1);
c[k]=c[2*k]+c[2*k+1];//1 此处写成 c[k]=(c[2*k]+c[2*k+1])%p;
}
void down(int left,int right,int k){
int mid=(left+right)/2;
lazya[2*k]*=lazyb[k];//1 漏了该句
lazya[2*k]+=lazya[k];
lazya[2*k]%=p;//1 漏了该句
lazyb[2*k]*=lazyb[k];
lazyb[2*k]%=p;//1 漏了该句
c[2*k]*=lazyb[k];//1 写成 c[2*k]*=lazyb[2*k];
c[2*k]+=(mid-left+1)*lazya[k];//1 写成 c[2*k]+=(mid-left+1)*lazya[2*k];
c[2*k]%=p;//1 漏了该句
lazya[2*k+1]*=lazyb[k];// 1 漏了该句
lazya[2*k+1]+=lazya[k];
lazya[2*k+1]%=p;//1 漏了该句
lazyb[2*k+1]*=lazyb[k];
lazyb[2*k+1]%=p;//1 漏了该句
c[2*k+1]*=lazyb[k];//1 写成 c[2*k+1]*=lazyb[2*k+1];
c[2*k+1]+=(right-mid)*lazya[k];//1 写成 c[2*k+1]+=(right-mid)*lazya[2*k+1];
c[2*k+1]%=p;//1 漏了该句
lazya[k]=0;
lazyb[k]=1;
}
void add(int left,int right,int k,int start,int end,int v){
int mid=(left+right)/2;
if(left>end||right<start)return;//剪枝
if(start<=left&&right<=end){
c[k]+=(right-left+1)*v;//1 此处写成 c[k]+=(right-left+1)*v%p;
lazya[k]+=v;//1 此处写成 lazya[k]+=v%p;
return;
}
down(left,right,k);
add(left,mid,2*k,start,end,v);
add(mid+1,right,2*k+1,start,end,v);
c[k]=c[2*k]+c[2*k+1];//1 此处写成c[k]=(c[2*k]+c[2*k+1])%p;
}
void mul(int left,int right,int k,int start,int end,int v){
int mid=(left+right)/2;
if(left>end||right<start)return;//剪枝
if(start<=left&&right<=end){
c[k]*=v;//1 此处写成 c[k]*=v%p;
lazyb[k]*=v;//1 此处写成 lazyb[k]*=v%p;
lazya[k]*=v;//1 此处写成 lazya[k]*=v%p;
return;
}
down(left,right,k);
mul(left,mid,2*k,start,end,v);
mul(mid+1,right,2*k+1,start,end,v);
c[k]=c[2*k]+c[2*k+1];//1 此处写成 c[k]=(c[2*k]+c[2*k+1])%p;
}
long long ask(int left,int right,int k,int start,int end){
int mid=(left+right)/2;
if(left>end||right<start)return 0;//剪枝 该句写得不错,返回0
if(start<=left&&right<=end)
return c[k]%p;
down(left,right,k);
return (ask(left,mid,2*k,start,end)+ask(mid+1,right,2*k+1,start,end))%p;//解释:查询是无需改变数组c[]的值 1 此处写成 ask(left,mid,2*k,start,end);ask(mid+1,right,2*k+1,start,end);return c[k]=(c[2*k]+c[2*k+1])%p;
}
int main(){
int n,m,i,cmd,opx,opy,opv;
memset(lazya,0,sizeof(lazya));
scanf("%d%d%d",&n,&m,&p);
for(i=1;i<=4*n;i++)//3 此处写成 for(i=1;i<=n;i++)
lazyb[i]=1;
build(1,n,1);
for(i=1;i<=m;i++){
scanf("%d",&cmd);
switch(cmd){
case 1:
scanf("%d%d%d",&opx,&opy,&opv);
mul(1,n,1,opx,opy,opv);
break;
case 2:
scanf("%d%d%d",&opx,&opy,&opv);
add(1,n,1,opx,opy,opv);
break;
case 3:
scanf("%d%d",&opx,&opy);//2 此处写成 scanf("%d%d%d",&opx,&opy); 程序 一直出现停止工作
printf("%lld\n",ask(1,n,1,opx,opy));
break;
}
}
return 0;
}
5.//P3378 【模板】堆
//明确题,是最小堆
#include <stdio.h>
#include <string.h>
int h[1000000+100],n,s=0;//s堆中的元素个数
void insert(int k){//在最小堆中插入元素,自下而上处理
int p;
s++;//在堆中再多开一个元素位置
p=s;
while(p>1&&k<h[p/2]){//该段代码必须画出堆的图,才能很好理解。
h[p]=h[p/2];
p/=2;
}
h[p]=k;
}
void adjust(int t){//最难写的是调整部分,自上向下调整,整个程序中最难写的部分.
int k=t,left=2*t,right=2*t+1,c;
if(left<=s)
k=h[k]>h[left]?left:k;
if(right<=s)
k=h[k]>h[right]?right:k;//找出h[k] h[left] h[right]三者中最小值的位置
if(k!=t){
c=h[k];
h[k]=h[t];
h[t]=c;
adjust(k);
}
}
void del(){
h[1]=h[s];
s--;
adjust(1);
}
int main(){
int i,cmd,a;
scanf("%d",&n);
for(i=1;i<=n;i++){
scanf("%d",&cmd);
switch(cmd){
case 1:
scanf("%d",&a);
insert(a);
break;
case 2:
printf("%d\n",h[1]);
break;
case 3:
del();
break;
}
}
return 0;
}
2017-7-12 17:50AC该单元
提高模板-数、树、图、串
1.//P3370 【模板】字符串哈希
//http://www.cnblogs.com/zbtrs/p/5998028.html此文写得不错,算是暴力。
//采用暴力方式,提交AC。
//至于字符串Hash函数,等学到时再来尝试该题,《高级数据结构》(C++版)林厚从 有介绍,会很快学习到。
//http://www.yhzq-blog.cc/%E5%AD%97%E7%AC%A6%E4%B8%B2hash%E6%80%BB%E7%BB%93/此文采用字符Hash,感觉写得不错,学到时再来看。标记一下
//暴力在竞赛中很关键,或者是第一思想。2017-8-9 22:23
#include <set>
#include <string>
#include <iostream>
#include <cstdio>
using namespace std;
int main(){
int n,i,ans=0;
set<string> s;
string ss;
scanf("%d",&n);
for(i=1;i<=n;i++){
cin>>ss;
if(!s.count(ss)){
s.insert(ss);
ans++;
}
}
printf("%d\n",ans);
}
2.
3.
4.
5.