java编译器是什么?
编译简单理解就是一种高级语言到另一种低级语言的翻译过程;而执行这个过程的主体称为编译器。寻常所说的编译器是指把汇编语言转变成机器语言,也称目标代码,即CPU指令集。汇编语言是一种比机器语言对人友好的语言,但不同机器硬件构造不一样,驱动机器的软件也不一样,因此汇编语言需要针对不同的机器编写不同的代码,显得有点麻烦。为解决这个问题,聪明的工程师想到一种方法,即采用虚拟机的形式屏蔽底层硬件和软件平台的不同,也就是说,高级语言的编写不受底层硬件的影响,达到“一次编译,到处运行”的效果。
很明显,“一次编译,到处运行”的功能寄托于虚拟机;java语言是基于java虚拟机(JVM)而实现的一种高级语言,它需要通过java编译器编译成JVM识别的语言,最后由JVM实现到目标语言的转换。

javac的作用?
javac是把java高级语言转变成JVM识别的一种二进制代码;具体体现就是.java文件到.class文件的转变;JVM识别的.class文件存储的是字节码;而转变的正确性则是由JVM的语言规范来保证,所以java编译器的作用可以理解为把java语言规范转变成JVM语言规范。
javac的主要过程?
从java语言到字节码的转变要经过四个过程:①java语言到Token流的过程,称为词法分析;②Token流到抽象语法树的过程,称为语法分析;③解析复杂的树节点,如语法糖的解析等,称为语义分析;④抽象语法树到字节码的过程,称为代码生成。
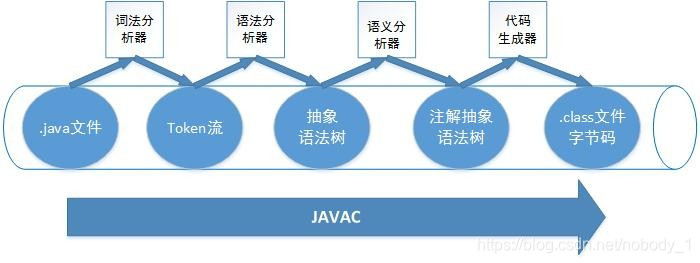
至于为什么要分为这四个步骤?
抽象语法树是关键。抽象语法树可以把一种语言结构重组为另外一种语言结构,这里可以简单理解为java语言规范到JVM语言规范的转变。
这篇博客首先来看一下词法分析的过程。
何为词法分析?
词法分析从字面来理解就是解析java语言中的单词;单纯的从字面来看,java文件由java关键字、标识符(包名、类名、属性名和方法名)以及符号(各类运算符、各类括号)等三部分组成。词法分析的主要目的就是把这些单词和符号转变成Token流。那么什么是Token流呢,后面会讲到。
词法分析的过程?
词法分析在源代码中是和语法分析在一起的,在这里为了更好的理解词法分析的过程,我是从代码的执行角度来分析的。有如下代码:
package com.compile;
public class CifaAnalysis {
int i = 0;
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
大体过程如下:
①通过com.sun.tools.javac.main.Main类的compile()方法读取.java文件;
②通过com.sun.tools.javac.main.JavaCompiler.readSource(JavaFileObject)方法把文件内容转变成字符流(charSequence);
③通过com.sun.tools.javac.parser.Scanner.nextToken()方法从字符流中获取一个token;
这里有两个问题:
①长串字符流如何形成一个个token?token长啥样?
②形成的token存放在哪里?
针对第一个问题,nextToken()方法说的很清楚,由于方法过长,这里就不黏贴出来,简单的说就是一个一个字符读取字符流,比如”package com.compile”,当读取p-a-c-k-a-g-e-空格,识别到空格时则会把空格前的字符流组成一个token字符串.(Token是一个枚举类,列举了所有的关键字、各类运算符和符号等)。或许你在这里还有一个疑问,如果一个双目运算符两边没有空格如int i=0该如何形成四个token而不是两个?在nextToken方法里面已经对这种特殊操作符(!%&*?±:<=>|~@)进行了特殊的处理。
针对第二个问题,就要说说token是怎么处理的了。
原来Token类里面的name到value的映射是由com.sun.tools.javac.parser.Keywords.Keywords(Context)方法完成的,每一个token都以Name类的对象存储在Token类型的数组内;
key = new Token[maxKey+1];
for (int i = 0; i <= maxKey; i++) key[i] = IDENTIFIER;
for (Token t : Token.values()) {
if (t.name != null)
key[tokenName[t.ordinal()].index] = t;
}
maxKey表示Token枚举类的数量;通过第二个for循环把映射关系(name-value)初始化好,name没有映射的value则value为IDENTIFIER;因此当nextToken()方法形成一个token时会定义为name对象,然后根据这个name对象去key数组中查找对应的value,没有找到对应关系的name,其value为IDENTIFIER,所以com/compile等标识符都会被定义为IDENTIFIER;
public Token key(Name name) {
return (name.index > maxKey) ? IDENTIFIER : key[name.index];
}
此时,针对Token放在哪里的问题也就很清楚了。
就这样,整个原文件被形成下面这个样子:

可以看出,经常误以为的main和String并不是java关键字,只是作为一种IDENTIFIER。
最后还有一个问题,虽然我们知道package后面跟的是包名,但编译器怎么知道?编译器怎么识别包名、类名、变量和方法名的?
编译器知道Token.PACKAGE后面跟的是包名,Token.IMPORT后面跟的是导入的类名;Token.CLASS后面是类名等等这些都是事先约定好的,可以认为是java语言的规范。
总结
到此,词法分析的整个过程结束了。可以整理下流程:
->读取.java源文件,并转换为字符流;
->读取字符流,根据规则形成name对象,并映射成Token;
->一个个Token形成Token流;
参考资料
《深入分析javaweb技术内幕》
http://blog.51cto.com/13981400/2178759