大三有门课程叫编译原理,叫我们自己写一个简单的编译器,嗯,随意什么语言都可以,那我当然用js啦,这么优雅,虽然被我用的不怎么优雅。这个和语言无关,只是我喜欢用js而已,里面没用多少js的特性。
另外代码写的有点烂,别喷。
先说一下我自己的整个过程吧
- 首先第一步词法分析:就是需要写正则表达式然后把里面的单词和数字符号什么的全部切割出来。
- 构建语法规则,这里我选的是LL(1)文法。这里设计好自己的文法。
- 构建中间代码。这里我用了语法树。
- 编写转换程序,什么样的文法句子就对应什么样的程序。
词法分析:
输入一个正则,把正则表达式转换成nfa->dfa->dfa最小化。这部分去看网易云课堂那个用java做的编译器那个,照着上面的做就好了,我前面nfa部分就照着他的视频做的。
得到dfa最小化的那个表。对于每一个正则表达式来说需要的就只是这个表而已。所以确定好正则表达式之后就可以直接存储这个表,不需要每次都生成。
- 然后你需要一大堆正则表达式
- 数字一个
- 符号一个
- 关键字一个
- 变量名一个
- “anything”一个(这个可以用来处理出错的,如果都不是上面1-4,那么就可以用5去接收排除掉)
var id_ = new build_rule();
id_.build_from_str(id__str, 3);
//这个变量id__str就是那个已经生成字符串保存起来的dfa最小化的表
//数字3就是id对应的名字,到时候用来判断来生成类型码的
var key_word = new build_rule();
key_word.build_from_str(key_word_str, 1);
//和上面一样
var ops = new build_rule("{op}{op}*", 1);
//这个使用正则生成的规则的,需要经过nfa---dfa---最小化这几步的转化
//1符号和关键字统称的类型
var num = new build_rule("{float}", 4);
//同上
var anything = new build_rule();
anything.build_from_str(anything_str);
anything.rule_name = 5;
//这个就是用来处理错误的,识别5这个类型时候就会出错,也可以记录这个出错让程序一直扫描到后面再输出错误
//按照自己定义的规定的顺序进行添加规则,到时候就会按照这个顺序进行查找
var qing = qingai(code);
qing.add_rules(key_word);
qing.add_rules(id_);
qing.add_rules(ops);
qing.add_rules(num);
qing.add_rules(anything);
qing.action();- 所有正则表达式有顺序的,这个看你自己安排那个重要。例如顺序是:
变量名——–>关键字———->其他
这样的话,如果识别到 “var” 会把var当成是变量名,因为var在没有被定义成为关键词时候,这个是可以作为合法的变量名的。
所以顺序需要自己安排好 - 构建好多个正则表达式以及他们的顺序之后,就开始开工了。
- 源代码从头开始扫描,主指针指向开头
- 指针指向开头
- 从第一个规则找起
- 按照dfa自动机规则,也就是那个表,遇到什么字符就跳到那一行
- 如果读入下一个还是可以跳转的就再跳转到另一行。如果不能跳转,看看这一行是不是有结束标记的,有的话就顺利退出,不用再找下一个规则,然后主指针加上这个找到的字符串的长度,顺便记录这个字符串的信息:长度,那一行,那一列,什么类型。如果没有就要找下一个规则。
- 因为有那个 都是的规则存在,保证每个都能找到属性。
- 还是会有没找到的,因为有空格个换行,需要在最后判断一下,过滤掉就好了。
- 然后根据自己写的源代码
a=7464;
b=7465;
a=b+7464*2;
就可以得到这样的一个表了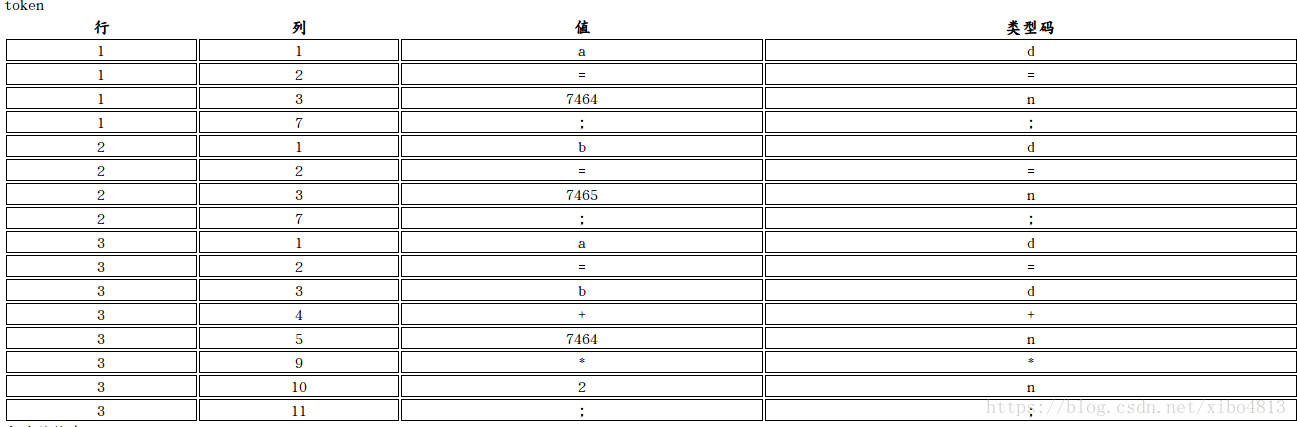
8. 后面的类型码,就是在文法里面需要用类型码来表述这个类型的字符串。之后语法这边会通过类型码去判断输入的句子符不符合给出的文法。因为不同的关键字和符号都有不同的意思,所以关键字和符号的类型码都是不同的,我的变量名就用d来表示
总结步骤
- 输入正则表达式
- 把正则表达式的宏定义换成正常的字符
- 切割正则表达式
- 把切割好的整个表达式传入nfa自动机构造nfa图
- 把nfa图的头节点传入dfa自动机构造dfa表
- 把nfa表进行dfa最小化得到dfa最小化表
- 这样完成一种字符串对应的查找自动机的构造
- 重复1-7直到所有正则表达式都转换完成。之后只需要保存好所有最小化的表,每次只要载入那个表就可以了,不需用每次都生成nfa、dfa什么的。
- 按照顺序把规则放进扫描仪(其实就是一个while循环一次自己写的源程序所有的字符而已)里面,开始扫描。
- 得到token表
- 结束