Lex词法分析器
一.设计内容
熟悉并实现一个简单的词法分析器
二.设计目的
了解高级语言单词的分类,了解如何识别单词规则,掌握状态图到识别程序的编程。
源程序中,存在许多编辑用的符号,他们对程序逻辑功能无任何影响。例如:回车,换行,多余空白符,注释行等。在词法分析之前,首先要先剔除掉这些符号,使得词法分析更为简单。
三.实验步骤
Lex输入文件由3个部分组成:
定义集(definition),规则集(rule)和辅助程序集(auxiliary routine)或用户程序集(user routine)。
这三个部分由位于新一行第一列的双百分号分开,因此,Lex输入文件的格式如下 :
{definitions}
%%
{rules}
%%
{auxiliary routines}
将每个单词符号进行不同类别的划分。单词符号可以划分成5种:
- 标识符:用户自己定义的名字,常量名,变量名和过程名。
- 常数:各种类型的常数。
- 保留字(关键字):如if、begin、then、while、do等。
- 运算符:如+、-、*、<、>、=等。
- 界符:如逗号、分号、括号等。
将各类单词对应到lex中:
词法分析器所输出单词符号常常表示成单词种别,单词符号的属性值的二元式:
单词种别通常用整数编码。标识符一般统归为一种。常数则宜按类型(整、实、布尔等)分种。关键字可将其全体视为一种。运算符可采用一符一种的方法。界符一般用一符一种的方法。对于每个单词符号,除了给出了种别编码之外,还应给出有关单词符号的属性信息。单词符号的属性是指单词符号的特性或特征。
- 保留字:
定义识别保留字规则

reserved_word [const|var|procedure|begin|end|if|then|while|do|read|call|write|writeln]
由于在lex中不区分大小写,所以将保留字写成:
reserved_word [cC][oO][nN][sS][tT]|[vV][aA][rR]|[pP][rR][oO][cC][eE][dD][uU][rR][eE]|
[bB][eE][gG][iI][nN]|[eE][nN][dD]|[iI][fF]|[tT][hH][eE][nN]|[wW][hH][iI]
[lL][eE]|[dD][oO]|[rR][eE][aA][dD]|[cC][aA][lL][lL]|[wW][rR][iI][tT][eE]
[wW][rR][iI][tT][eE][lL][nN]
- 常数:
digit ([0-9])+
- 标识符:
letter [A-Za-z] ([A-Za-z][0-9])*
- 运算符:
operator +|-|*|\/|:=|>=|<=|#|= /在lex中,有特殊意义的运算符要加转义字符\,如+、及*、/
- 分界符:
delimiter [,.;]
词法分析器要求跳过分隔符(如空格,回车,制表符)
delim [“”\n\t]
whitespace{delim}+
为lex制定一些规则,统计给出程序的词法分析:
{reserved_word}{line_num++;printf(“\t%d\t(1,‘%s’)\n”,line_num,yytext);}
{operator} {line_num++;printf(“\t%d\t(2,‘%s’)\n”line_num,yytext); }
{delimiter}{line_num++;printf(“\t%d\t(3,‘%s’)\n”,line_num,yytext);}
{digit}{line_num++;printf(“\t%d\t(4,‘%s’)\n”,line_num,yytext);}
{letter}{line_num++;printf(“\t%d\t(5,‘%s’)\n”,line_num,yytext);}
{whitespace} {/* do nothing*/ }
子程序:
void main() {
printf("THE LEXICAL ANALYSIS GENERATOR LEX:\n");
printf("1:reserved_word\n");
printf("2:oprator\n");
printf("3:delimiter\n");
printf("4:digit\n");
printf("5:leter\n");
printf("\n");
yyin=fopen("example.txt","r");
yylex(); /* start the analysis*/
fclose(yyin);
system("PAUSE");
}example.txt为测试的程序片段
当lex 读完输入文件之后就会调用函数 yywrap 。如果返回1 表示程序的工作已经完成了。
用lex编译工具编译源程序a.l,然后生成了lex.yy.c文件,然后在有程序片的目录下编译运行该.c文件,读取example.txt,查看输出的结果既可看到分析的结果。
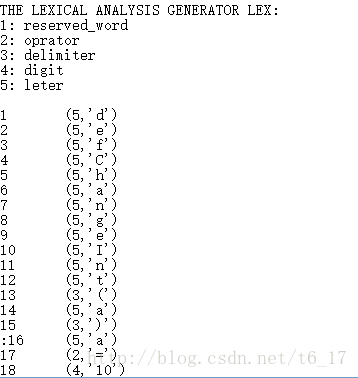
测试程序example.txt:
def ChangeInt( a ):
a = 10
b = 2
ChangeInt(b)
print b源程序a.l:
%{
#include <stdio.h>
#include <stdlib.h>
int count = 0;
%}
delim [" "\n\t]
whitespace {delim}+
operator \+|-|\*|\/|:=|>=|<=|#|=
reserved_word [cC][oO][nN][sS][tT]|[vV][aA][rR]|[pP][rR][oO][cC][eE][dD][uU][rR][eE]|[bB][eE][gG][iI][nN]|[eE][nN][dD]|[iI][fF]|[tT][hH][eE][nN]|[wW][hH][iI][lL][eE]|[dD][oO]|[rR][eE][aA][dD]|[cC][aA][lL][lL]|[wW][rR][iI][tT][eE]|[wW][rR][iI][tT][eE][lL][nN]
delimiter [,\.;\(\)]
digit ([0-9])+
letter [A-Za-z]([A-Za-z][0-9])*
%%
/*line_num is line number*/
{reserved_word} {line_num++;printf("%d\t(1,‘%s’)\n",line_num,yytext);}
{operator} {line_num++;printf("%d\t(2,‘%s’)\n",line_num,yytext); }
{delimiter} {line_num++;printf("%d\t(3,‘%s’)\n",line_num,yytext);}
{digit} {line_num++;printf("%d\t(4,‘%s’)\n",line_num,yytext);}
{letter} {line_num++;printf("%d\t(5,‘%s’)\n",line_num,yytext);}
/*ignore whitespace*/
{whitespace} { /* do nothing*/ }
%%
void main() {
printf("THE LEXICAL ANALYSIS GENERATOR LEX:\n");
printf("1:reserved_word\n");
printf("2:oprator\n");
printf("3:delimiter\n");
printf("4:digit\n");
printf("5:leter\n");
printf("\n");
yyin=fopen("test.txt","r");
yylex(); /* start the analysis*/
fclose(yyin);
system("PAUSE");
}
int yywrap()
{
return 1;
} 测试结果: