本篇博客将围绕Hadoop伪分布安装+MapReduce运行原理+基于MapReduce的KNN算法实现这三个方面进行叙述。
(一)Hadoop伪分布安装
1、简述Hadoop的安装模式中–伪分布模式与集群模式的区别与联系.
Hadoop的安装方式有三种:本地模式,伪分布模式,集群(分布)模式,其中后两种模式为重点,有意义
伪分布:如果Hadoop对应的Java进程都运行在一个物理机器上,称为伪分布
分布:如果Hadoop对应的Java进程运行在多台物理机器上,称为分布.[集群就是有主有从]
伪分布模式就是在一台服务器上面模拟集群环境,但仅仅是机器数量少,其通信机制与运行过程与真正的集群模式是一样的.
2、简述Hadoop伪分布模式的安装步骤(7步骤)
①>关闭防火墙
②>设置静态IP地址
③>修改主机名
④>IP地址与主机名绑定
⑤>设置SSH免密码登录
⑥>安装JDK并配置环境变量
⑦>安装HADOOP并配置环境变量,并修改hadoop的四个配置文件,最后对hadoop进行格式化
3、简述Hadoop伪分布模式安装步骤的具体细节
1>关闭防火墙(验证)
service iptables status
service iptables stop(暂时关闭)
chkconfig iptables off(永久关闭)
验证:chkconfig –list|grep iptables
关闭防火墙的原因:Hadoop集群在通信的时候有很多个端口要开启使用,所以要关闭防火墙
2>设置静态IP地址(验证)
如果要使用host-only这种网络连接方式,虚拟机VMWare的虚拟网卡Vmnet1必须要开启
如果要使用brige桥接这种网络连接方式,虚拟机VMWare的虚拟网卡Vmnet8必须要开启
配置Ip地址时,默认网关为相应虚拟网卡的IP地址
设置完IP地址之后要重启网卡:service network restart
验证:ifconfig
3>修改主机名(验证)
vi /etc/sysonfig/network
验证:重启验证,使主机名生效
reboot -h now
hostname
或者为了防止重启麻烦,可以这么做:
hostname hadoop60(主机名)
exit
4>IP地址与主机名绑定(验证)
主机名类似于我们的域名,主机名只有与Ip地址绑定,才能ping通主机名,而且之所以将主机名与IP地址绑定,是因为主机名使用方便
Linux:
vi /etc/hosts 然后添加一行 IP地址 主机名
Windows:
进入C:\Windows\System32\drivers\etc\hosts
然后添加一行 IP地址 主机名
验证:ping 通主机名即可
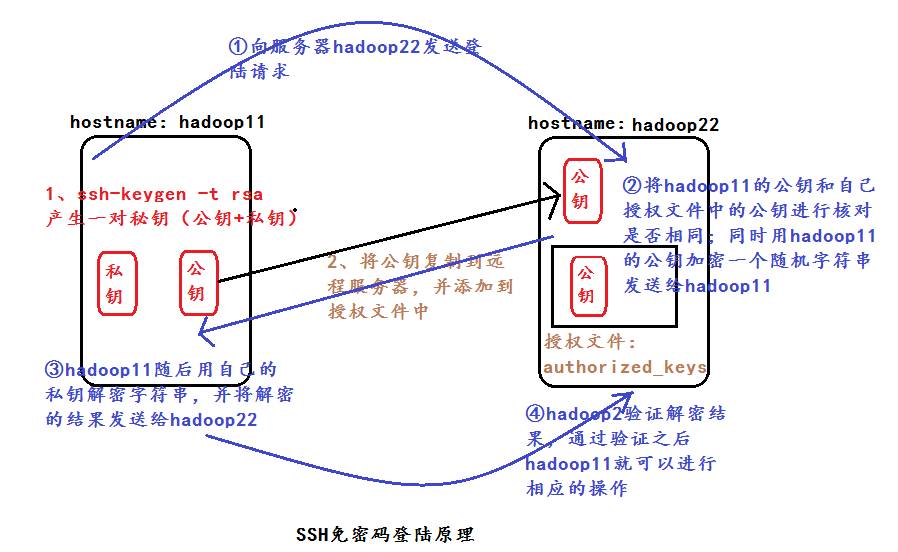
5>设置SSH(secure shell)免密码登录(验证)
执行命令ssh-keygen -t rsa 产生秘钥文件:
id_rsa(私钥) id_rsa.pub(公钥)
在homedirectory/.ssh处执行
cp id_rsa.pub authorized_keys 产生授权文件[SSH在验证的时候会读取这个授权文件文件的内容]
SSH免密码登录的作用:
通过SSH免密码登录这种机制,只要知道远程机器的主机名(hostname)与密码(passwd),通过secure shell就可以登录到远程的机器;通过SSH免密码登陆不用手动启动相应的进程!
除此之外,也可以通过上面的秘钥文件进行无密码登陆!
验证:ssh 主机名
下面是SSH免密码登陆原理图:
6>安装JDK并配置环境变量(验证)
之所以安装JDK,是因为Hadoop是运行在Jdk之上的
安装Jdk的时候要配置两个系统变量:
vi /etc/profile
export JAVA_HOME=/usr/local/jdk
export PATH= . :/usr/local/jdk/bin :$PATH
PATH指向的是JAVA_HOME的bin目录
注意:PATH是内置的环境变量
source /etc/profile
验证:java -version java javac
7>安装HADOOP并配置环境变量,并修改hadoop的四个配置文件,最后对hadoop进行格式化(验证)
安装HADOOP并配置环境变量:
安装Hadoop的时候要配置两个系统变量:
vi /etc/profile
export HADOOP_HOME=/usr/local/hadoop
export PATH= .:/usr/local/jdk/bin:/usr/local/hadoop/bin:$PATHPATH指向的是Hadoop_HOME的bin目录
source /etc/profile
修改Hadoop的四个配置文件:
默认的hadoop是一种本地执行模式,而在这里讲的是伪分布,所以要修改配置文件,适合伪分布模式
这四个配置文件分别是:
hadoop-env.sh(1)、core-site.xml(2)、hdfs-site.xml(2)、mapred-site.xml(1)
最后对hadoop进行格式化:
启动hadoop之前要对hadoop格式化,因为新买的移动硬盘使用之前要进行格式化,格式化之后才能使用,格式化的目的是为了对磁盘上的空间按照一定的文件格式进行处理
hadoop namenode -format
最后一步:消除警告:
export HADOOP_HOME_WARN_SUPPRESS=1
验证:start-all.sh 之后会启动5个java 进程
8>检验是否安装成功
方式1:执行命令jps,看是否启动5个进程
方式2:通过浏览器http://hadoop:50070 和 http://hadoop:50030 分别查看NameNode与JobTracker是否正常启动。
4、简述四个配置文件中配置的内容
默认的hadoop是一种本地执行模式,通过修改配置文件可以变成伪分布模式.
四个配置文件分别是:
第一个是hadoop环境变量脚本文件hadoop-env.sh
在这里面需要指定Java_HOME(jdk)的具体路径,因为hadoop是运行在JDK之上的.
第二个是hadoop的核心配置文件core-site.xml
在这里面需要指定HDFS(NameNode)的访问路径(fs.default.name)以及NameNode、DataNode等存放数据的公共目录(hadoop.tmp.dir)
第三个是HDFS的配置文件hdfs-site.xml
在这里面需要指定DataNode存放block块的副本数(dfs.replication),默认是3个.以及对HDFS的访问权限(dfs.permissions).
第四个是MapReduce的配置文件mapred-site.xml
在这里面需要指定MapReduce中JobTracker的访问路径
(mapred.job.tracker)
5、简述宿主机(windows)与客户机(安装在虚拟机中的linux)网络连接方式
首先要明确:之所以使用虚拟机,是因为通过虚拟机可以模拟出一台机器,因为现有环境机器数量不够
网络连接方式:
1>host-only
这种网络连接方式的特点是宿主机与客户机单独组网,客户机(虚拟机)与宿主机所在的局域网中的其它电脑之间不能够相互通信。
如果要使用host-only这种网络连接方式,虚拟机VMWare的虚拟网卡Vmnet1必须要开启
Vmnet1:192.168.80.1
Linux:192.168.80.100
Windows:192.168.70.1
优点:隔离网络,安全
缺点:虚拟机与其它服务器之间是不能通信的
2>bridge(桥接)
这种网络连接方式的特点是客户机(虚拟机)与宿主机所在的局域网中的其它电脑之间能够相互通信。
如果要使用桥接这种网络连接方式,虚拟机VMWare的虚拟网卡Vmnet8必须要开启
Vmnet1:192.168.70.1
Linux:192.168.70.100
Windows:192.168.70.1
优点:因为同在一个局域网中,彼此之间数据的传输方便
缺点:不安全
3>NAT方式(略)
6、简述Hadoop的目录结构
bin目录:用于存放hadoop常用命令的文件夹
conf目录:用于存放hadoop相关配置文件的文件夹
src目录:用于存放hadoop源码的文件夹
docs目录:用于存放于hadoop相关的文档与api
等等
7、简述hadoop中常用的重要命令
start-all.sh:启动hadoop
stop-all.sh :关闭hadoop
分别启动:
启动hdfs:start-dfs.sh
启动mapreduce:starr-mapred.sh
分别启动各个进程:
hadoop-daemon.sh start 进程名称
这种启动方式适用于单独增加,删除节点的情况,在hadoop集群搭建的过程中经常使用.
(二)MapReduce运行原理
运行原理图示:

MapReduce程序的执行过程分为两个阶段:Mapper阶段和Reducer阶段。
其中Mapper阶段可以分为6个步骤:
第一阶段:先将HDFS中的输入文件file按照一定的标准进行切片,默认切片的类为FileInputFormat,通过切片输入文件将会变成split1、split2、split3……;随后对输入切片split按照一定的规则解析成键值对<k1,v1>,默认处理的类为TextInputFormat。其中k1就是我们常说的起始偏移量,v1就是行文本的内容。
第二阶段:调用自己编写的map逻辑,将输入的键值对<k1,v1>变成<k2,v2>。在这里要注意:每一个键值对<k1,v1>都会调用一次map函数。
第三阶段:按照一定的规则对输出的键值对<k2,v2>进行分区:分区的规则是针对k2进行的,比如说k2如果是省份的话,那么就可以按照不同的省份进行分区,同一个省份的k2划分到一个区。注意:默认分区的类是HashPartitioner类,这个类默认只分为一个区,因此Reducer任务的数量默认也是1.
第四阶段:对每个分区中的键值对进行排序。注意:所谓排序是针对k2进行的,v2是不参与排序的,如果要让v2也参与排序,需要自定义排序的类,具体过程可以参看博主文章。
第五阶段:排序完之后要进行分组,即相同key的value放到同一个集合当中,例如在WordCount程序中的<hello,{1,1}>执行的就是这个步骤,但是要注意:分组也是针对key进行的,经过分组完之后,就得到了我们熟悉的键值对<k2,v2s>.
第六阶段(可选):对分组后的数据进行归约处理。通过归约处理键值对<k2,v2s>变成了<k2,v2>,经过这一阶段,传送到Reducer任务端的数据量会减少。但是规约的使用是有条件的,所以这一阶段是可以选择的。
Mapper任务处理完之后,就进入到了我们的Reducer阶段:
Reducer任务的执行过程可以分为3个阶段:
第一阶段:对多个Mapper任务的输出,按照不同的分区,通过网络拷贝到不同的Reducer节点上进行处理,将数据按照分区拷贝到不同的Reducer节点之后,对多个Mapper任务的输出在进行合并,排序。例如:在WordCount程序中,若一个Mapper任务输出了<hello,{1,1}>,另外一个Mapper任务的输出为<hello,{1,1,1}>,经过在次合并之后变为<hello,{1,1,1,1,1}>.
第二阶段:调用自己的reduce逻辑,将键值对<k2,v2s>变为<k3,v3>.在这里注意:每一个键值对<k2,v2s>都会调用一次reduce函数。
第三阶段:将Reducer任务的输出保存到指定的文件中。(三)基于MapReduce的KNN算法实现
1、KNN算法简介
K近邻算法的思想较为简单—–简单来说就是“近朱者赤,近墨者黑”,KNN算法将没有分类标签的数据与样本集合中的所有的数据进行距离计算,然后提取出最相似的K个数据.K个数据中分类标签出现最多的分类就是新数据的分类标签.
总结下来:就是KNN算法很容易理解,同时易于实现。但是KNN算法的计算复杂度较高,计算量较大,对于每一个待分类的样本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。因此在大数据环境下,寻找准确的近邻需要花费较多的响应时间,限制了在实际中的一些应用—-此时我们的Hadoop平台就得到了应用。
2、map函数和reduce函数伪代码实现


3、基于MapReduce的KNN算法实现代码
package IT002;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Set;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
//本程序的目的是实现MR-K-NN算法
public class KNN0
{
public static String path1 = "hdfs://hadoop60:9000/test.txt";//读取HDFS中的测试集
public static String path2 = "hdfs://hadoop60:9000/testdir";
public static void main(String[] args) throws Exception
{
FileSystem fileSystem = FileSystem.get(new Configuration());
if(fileSystem.exists(new Path(path2)))
{
fileSystem.delete(new Path(path2), true);
}
Job job = new Job(new Configuration(),"KNN");
job.setJarByClass(KNN0.class);
FileInputFormat.setInputPaths(job, new Path(path1));//在这里指定输入文件的父目录即可,MapReduce会自动读取输入目录下所有的文件
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setNumReduceTasks(1);
job.setPartitionerClass(HashPartitioner.class);
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileOutputFormat.setOutputPath(job, new Path(path2));
job.waitForCompletion(true);
//查看执行结果
FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop60:9000/testdir/part-r-00000"));
IOUtils.copyBytes(fr, System.out, 1024, true);
}
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text>
{
public ArrayList<Instance> trainSet = new ArrayList<Instance>();
public int k = 9;//k在这里可以根据KNN算法实际要求取值
protected void setup(Context context)throws IOException, InterruptedException
{
FileSystem fileSystem = null;
try
{
fileSystem = FileSystem.get(new URI("hdfs://hadoop60:9000/"), new Configuration());
} catch (Exception e){}
FSDataInputStream fr0 = fileSystem.open(new Path("hdfs://hadoop60:9000/trainData.txt"));
BufferedReader fr1 = new BufferedReader(new InputStreamReader(fr0));
String str = fr1.readLine();
while(str!=null)
{
Instance trainInstance = new Instance(str);
trainSet.add(trainInstance);
str = fr1.readLine();
}
}
protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException
{
ArrayList<Double> distance = new ArrayList<Double>(k);
ArrayList<String> trainLable = new ArrayList<String>(k);
for(int i=0;i<k;i++)
{
distance.add(Double.MAX_VALUE);
trainLable.add(String.valueOf(-1.0));
}
Instance testInstance = new Instance(v1.toString());
for(int i=0;i<trainSet.size();i++)
{
double dis = Distance.EuclideanDistance(trainSet.get(i).getAttributeset(),testInstance.getAttributeset());
for(int j=0;j<k;j++)
{
if(dis <(Double) distance.get(j))
{
distance.set(j, dis);
trainLable.set(j,trainSet.get(i).getLable()+"");
break;
}
}
}
for(int i=0;i<k;i++)
{
context.write(new Text(v1.toString()),new Text(trainLable.get(i)+""));
}
}
}
public static class MyReducer extends Reducer<Text, Text, Text, NullWritable>
{
protected void reduce(Text k2, Iterable<Text> v2s,Context context)throws IOException, InterruptedException
{
String predictlable ="";
ArrayList<String> arr = new ArrayList<String>();
for (Text v2 : v2s)
{
arr.add(v2.toString());
}
predictlable = MostFrequent(arr);
String preresult = k2.toString()+"\t"+predictlable;//**********根据实际情况进行修改**************
context.write(new Text(preresult),NullWritable.get());
}
public String MostFrequent(ArrayList arr)
{
HashMap<String, Double> tmp = new HashMap<String,Double>();
for(int i=0;i<arr.size();i++)
{
if(tmp.containsKey(arr.get(i)))
{
double frequence = tmp.get(arr.get(i))+1;
tmp.remove(arr.get(i));
tmp.put((String) arr.get(i),frequence);
}
else
tmp.put((String) arr.get(i),new Double(1));
}
Set<String> s = tmp.keySet();
Iterator it = s.iterator();
double lablemax=Double.MIN_VALUE;
String predictlable = null;
while(it.hasNext())
{
String key = (String) it.next();
Double lablenum = tmp.get(key);
if(lablenum > lablemax)
{
lablemax = lablenum;
predictlable = key;
}
}
return predictlable;
}
}
}
class Distance
{
public static double EuclideanDistance(double[] a,double[] b)
{
double sum = 0.0;
for(int i=0;i<a.length;i++)
{
sum +=Math.pow(a[i]-b[i],2);
}
return Math.sqrt(sum);//计算测试样本与训练样本之间的欧式距离
}
}
class Instance
{
public double[] attributeset;//存放样例属性
public double lable;//存放样例标签
public Instance(String line)
{
String[] splited = line.split("\t");
attributeset = new double[splited.length-1];
for(int i=0;i<attributeset.length;i++)
{
attributeset[i] = Double.parseDouble(splited[i]);
}
lable = Double.parseDouble(splited[splited.length-1]);
}
public double[] getAttributeset()
{
return attributeset;
}
public double getLable()
{
return lable;
}
}