MapReduce1.x架构
客户端向JobTracker提交一个作业,JobTracker把这个作业拆分成很多份,然后分配给TaskTracker(任务执行者)去执行,TaskTracker会隔一段时间向JobTracker发送心跳信息,如果JobTracker在一段时间内没有收到TaskTracker的心跳信息,JobTracker会认为TaskTracker死掉了,会把TaskTracker的作业任务分配给其他TaskTracker。
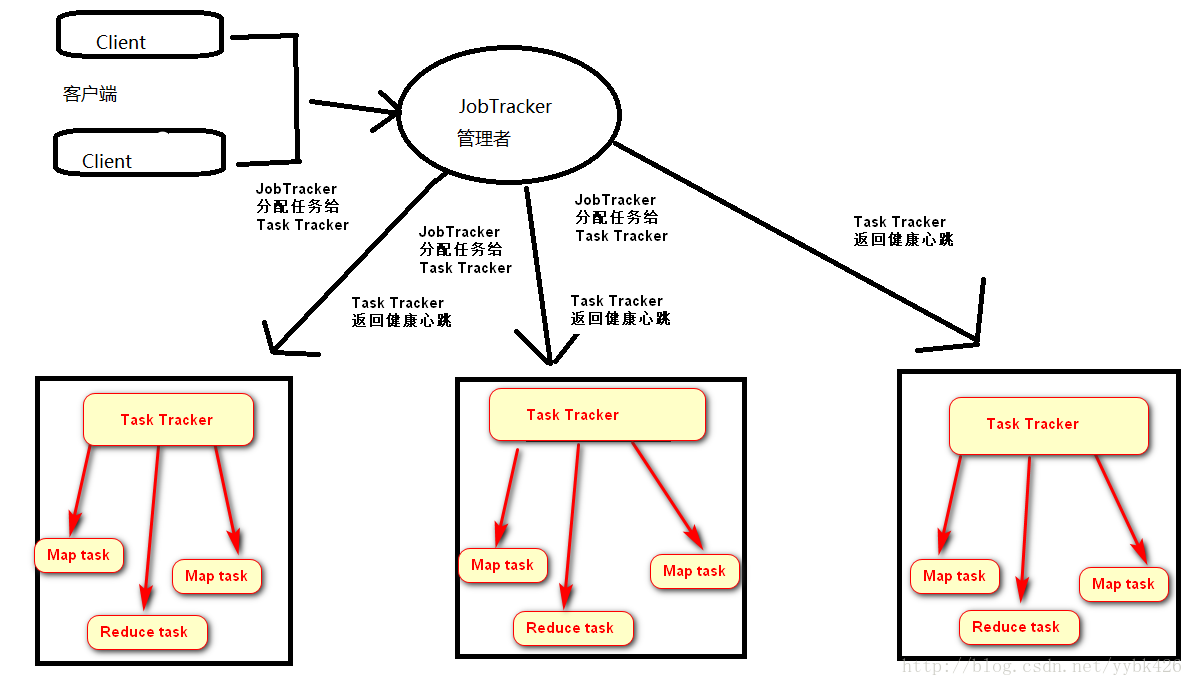
MapReduce1.x架构存在的问题:
1.JobTracker节点压力大
2.单点故障
3.只能跑mapreduce作业
MapReduce2.x架构
MapReduce就是分而治之的理念,把一个复杂的任务划分为若干个简单的任务分别来做。把一些数据通过map来归类,通过reducer来把同一类的数据进行处理。map的工作就是切分数据,然后给他们分类,分类的方式就是以key,value(键值对) 分类之后,reduce拿到的都是同类数据进行处理
MapReduce执行流程
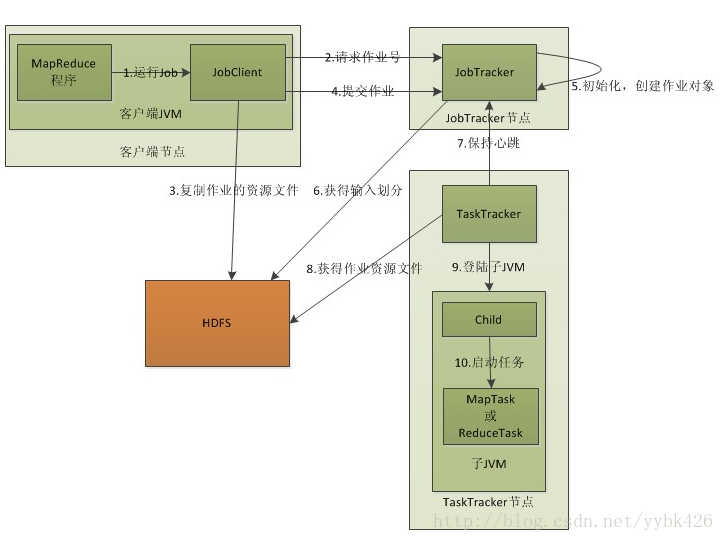
1.客户端提交一个作业
2.JobClient与JobTracker通信,JobTracker返回一个JobID
3.JobClient复制作业资源文件
将运行作业所需要的资源文件复制到HDFS上,包括MapReduce程序打包的JAR文件、配置文件和客户端计算所得的输入划分信息。这些文件都存放在JobTracker专门为该作业创建的文件夹中。文件夹名为该作业的Job ID。JAR文件默认会有10个副本(mapred.submit.replication属性控制);输入划分信息告诉了JobTracker应该为这个作业启动多少个map任务等信息。
4.开始提交任务(任务的描述信息:包括jobid,jar存放的位置,配置信息等等)
5.初始化任务。创建作业对象
JobTracker接收到作业后,将其放在一个作业队列里,等待作业调度器对其进行调度
6.对HDFS上的资源文件进行分片,每一个分片对应一个MapperTask
当作业调度器根据自己的调度算法调度到该作业时,会根据输入划分信息为每个划分创建一个map任务,并将map任务分配给TaskTracker执行
7.TaskTracker会向JobTracker返回一个心跳信息(任务的描述信息),根据心跳信息分配任务
TaskTracker每隔一段时间会给JobTracker发送一个心跳,告诉JobTracker它依然在运行,同时心跳中还携带着很多的信息,比如当前map任务完成的进度等信息。当JobTracker收到作业的最后一个任务完成信息时,便把该作业设置成“成功”。当JobClient查询状态时,它将得知任务已完成,便显示一条消息给用户。
8.TaskTracker从HDFS上获取作业资源文件
对于map和reduce任务,TaskTracker根据主机核的数量和内存的大小有固定数量的map槽和reduce槽。这里需要强调的是:map任务不是随随便便地分配给某个TaskTracker的,这里有个概念叫:数据本地化(Data-Local)。意思是:将map任务分配给含有该map处理的数据块的TaskTracker上,同时将程序JAR包复制到该TaskTracker上来运行,这叫“运算移动,数据不移动”。而分配reduce任务时并不考虑数据本地化。
9.登录到子JVM
10.TaskTracker启动一个child进程来执行具体任务
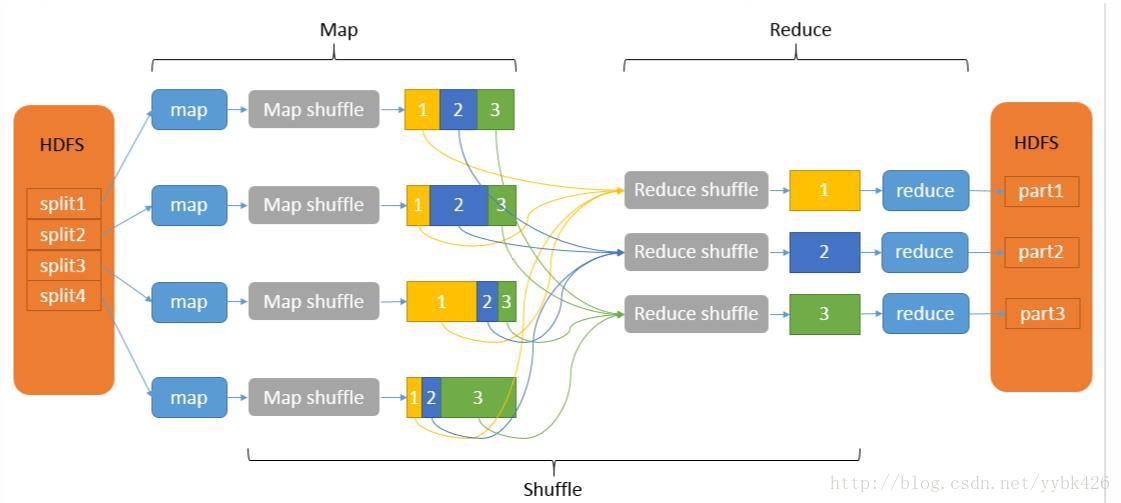
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
以下是mapreduce统计单词的单元测试
package com.kgc.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* Created by ASUS on 2017/7/25.
*/
public class MapReduceApp {
//第一个参数输入的k,第二个参数是输入的内容字符串类型,第三个参数输出的value类型,第四个输出的词频的个数
//第一个参数是这个文件的偏移量,第二个参数一行一行的数据,第三个参数按照分隔符把第二个参数分割,第四个参数出现的次数,赋值上1
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>{
LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//拿到输入的值
String line = value.toString();//接受每一行数据
//对拿到的值以指定分隔符进行分割,得到的是一个字符串数组
String[] words= line.split("\t");//按照指定的分隔符进行拆分
//给每个单词进行迭代,
for (String word : words){
//借助上下文,第一个参数是解析出来的单词,第二个参数是1
context.write(new Text(word),one);//通过上下文,把map的处理结果输出
}
}
}
//第一个参数和第二个参数就是map的输出,是reduce是输入,第三和第四个是reduce是输出
//第一个参数和第二个参数reduce输入必须要和map输出一样,第三和第四个是reduce是输出
public static class MyReduce extends Reducer<Text,LongWritable,Text,LongWritable>{
//key就是map发过来的word,values就是一堆的1,Iterable<LongWritable> values是reudce输入,可以理解为一堆的1
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
//下面做的是把一堆的1加起来
long sum = 0;
for (LongWritable value : values){
sum+= value.get();//求出现的总数
}
context.write(key,new LongWritable(sum));//最终统计结果的输出
}
}
//封装mapreduce作业所有信息
public static void main(String[] args) throws Exception {
//创建Configuration
Configuration configuration = new Configuration();
//准备/清理环境
Path outputPath = new Path(args[1]);
FileSystem fs = FileSystem.get(configuration);
if (fs.exists(outputPath)){
fs.delete(outputPath,true);
}
//创建job,wordcount是job的名称
Job job =Job.getInstance(configuration,"wordcount");
//设置job处理类,就是主类
job.setJarByClass(MapReduceApp.class);
//处理数据,就必须有一个输入路径,第一个参数job的名称,第二个参数是Path
FileInputFormat.setInputPaths(job,new Path(args[0]));//设置作业处理的路径
//设置map相关的
job.setMapperClass(MyMapper.class);//设置MyMapper.class
job.setOutputKeyClass(Text.class);//设置map输出key的类型,是Text
job.setMapOutputValueClass(LongWritable.class);//设置map输出的value的类型
//设置reduce相关的
job.setReducerClass(MyReduce.class);//设置MyReduce.class
job.setOutputKeyClass(Text.class);//设置reduce输出key的类型,是Text
job.setMapOutputValueClass(LongWritable.class);//设置reduce输出的value的类型
//设置作业处理的输出路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));
boolean result = job.waitForCompletion(true);//把作业提交
System.exit(result ? 0 : 1);//0就是true
}
}