时间复杂度为O(N*logN)的常用排序算法主要有四个——快速排序、归并排序、堆排序、希尔排序
1.快速排序
·基本思想
随机的在待排序数组arr中选取一个元素作为标记记为arr[index](有时也直接选择起始位置),然后在arr中从后至前以下标j寻找比arr[index]小的数,然后从前至后以下标i寻找比arr[index]大的数,如果i<j则交换二者的值;重复以上操作,直到i>=j,之后交换arr[index]与arr[j]的值,同时在i>begin中递归排序标记值的左侧数组,在j<end中递归标记值的右侧数组,直到结束,排序完成。
·代码实现
这里只提供一种实现,快速排序有多种实现。
public void quickSort(int[] arr,int begin,int end) {
int i = begin,j = end;
//以开始下标的值为标记
int index = begin;
while(i<j) {
//从后到前寻找比标记小的值
/*
* 这里需要注意,只能先从后开始找,否则如果先从前找的话,
* 以后交换arr[j]与arr[index]的值会使比arr[index]大的值在左边
*/
while (arr[j]>=arr[index]&&i<j) {
j--;
}
//从前到后寻找比标记大的值
while (arr[i]<=arr[index]&&i<j) {
i++;
}
//如果i<j才交换
if (i<j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
//将标记的值与arr[j]交换
int temp = arr[j];
arr[j] = arr[index];
arr[index] = temp;
//递归标记值的左右数组
if (i>begin) {
quickSort(arr,begin,i-1);
}
if (j<end) {
quickSort(arr,i+1, end);
}
}·性能分析
快速排序其实是冒泡排序的一种改进,每次递归,都将整个数组拆分成两部分分别递归,每一次划分过程的时间复杂度为O(N),平均情况下,快速排序的时间复杂度为O(N*logN),快速排序的交换次数是不确定的,主要取决于标记值的选取,因此额外空间复杂度是O(logN)~O(N),同时快速排序是不稳定的排序算法,相同的值如果都比标记值大或小,则会进行相对次序上的改变。
2.归并排序
·基本思想
归并排序总的大概流程如下:
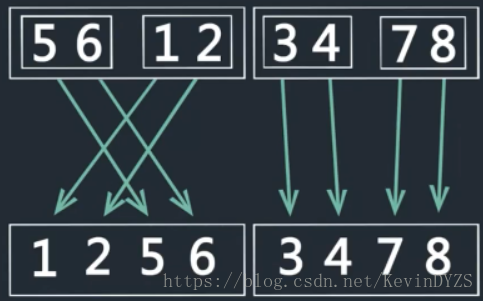
也就是说,将数组拆分成规模最小的,然后将数组逐渐的两两合并,最终合并成最初的数组。在代码实现上,则是利用递归的思想,如果发现当前数组的开始下标小于结束下标,则将数组递归拆分,直到拆分成只有一个元素的时候,开始逐层向上合并。
·代码实现
//合并函数
public void mergeCombine(int[] arr,int begin,int mid,int end,int[] temp) {
int i=begin,j=mid+1,k=0;
//将两段数组按大小顺序合并并排列
while(i<=mid&&j<=end) {
if (arr[i] <= arr[j]) {
temp[k++] = arr[i++];
}else {
temp[k++] = arr[j++];
}
}
//合并剩余的数组
//i>mid说明前半段已经合并完毕
while(i<=mid) {
temp[k++] = arr[i++];
}
while(j<=end) {
temp[k++] = arr[j++];
}
for (i = 0; i < k; i++) {
arr[begin + i] = temp[i];
}
}
//归并排序函数
//先传入一个temp辅助数组,否则每次递归的时候都要创建
public void mergeSort(int[] arr,int begin,int end,int[] temp) {
//防止范围过大而越界
int mid = begin + (end - begin)/2;
if (begin<end) {
mergeSort(arr, begin, mid,temp);
mergeSort(arr, mid+1, end,temp);
mergeCombine(arr, begin, mid, end,temp);
}
}·性能分析
归并排序的划分过程的时间复杂度是O(logN),每一个合并过程的时间复杂度是O(N),总体上的时间复杂度是O(N*logN),归并排序的效率属于比较高的。归并排序的额外空间复杂度是O(N)(注意,只有当直接传入辅助数组而不是每次递归都定义辅助数组的时候才是O(N)),同时,归并排序是稳定的排序算法,当元素相等的时候,不会进行交换。
3.堆排序
·基本思想
堆有大根堆和小根堆之分,大根堆表示父节点大于或等于左右孩子节点(这里采用大根堆的方法),同时调整根堆的方法也有递归的和非递归的,但是基本思想不变。先建造大根堆(建造的过程中就是用到了调整根堆的函数),然后将堆头和堆尾的元素进行交换,并且使根堆大小减一,同时调整根堆,每次调整完毕都交换一次,总共交换数组大小-1次,最终按序输出数组即可。·代码实现
①使用递归版本的大根堆排序
/**
* 递归版本的堆排序
*/
public class MaxHeap {
//记录堆
int[] heap;
//堆的大小(节点数目)
int heapSize;
public MaxHeap(int[] heap, int heapSize) {
this.heap = heap;
this.heapSize = heapSize;
}
public void buildMaxHeapify() {
//从最后一个非叶子节点开始向上递归
for(int i = heapSize/2-1 ; i >=0 ; i --) {
maxHeapify(i);
}
}
//堆排序算法
public void heapSort() {
for(int i = 0 ; i < heap.length-1 ; i ++) {
int temp = heap[0];
heap[0] = heap[heapSize-1];
heap[heapSize-1] = temp;
heapSize--;
maxHeapify(0);
}
}
//调整大根堆
public void maxHeapify(int index) {
int left = getLeft(index);
int right = getRight(index);
int max = 0;
if (left<heapSize&&heap[left]>heap[index]) {
max = left;
}else {
max = index;
}
if (right<heapSize&&heap[right]>heap[max]) {
max = right;
}
//max==index说明头节点是最大的元素
if (max==index||max>heapSize) {
return ;
}
//否则交换头节点与最大值,继续调整以这个最大值为下标的堆
int temp = heap[index];
heap[index] = heap[max];
heap[max] = temp;
maxHeapify(max);
}
//得到左儿子节点的坐标
private int getLeft(int index) {
return 2*index+1;
}
public int getRight(int index) {
return 2*(index+1);
}
}②使用非递归版本的大根堆
/**
* 非递归版本的堆排序
*/
public class MaxHeap2 {
int[] heap;
int heapSize;
public MaxHeap2(int[] heap, int heapSize) {
super();
this.heap = heap;
this.heapSize = heapSize;
}
public void heapSort() {
for(int i = 0 ; i <heap.length-1 ; i ++) {
int temp = heap[0];
heap[0] = heap[heapSize-1];
heap[heapSize-1] = temp;
heapSize--;
maxHeapify(0);
}
}
public void buildMaxHeapify() {
for(int i = heapSize/2-1 ; i >= 0 ; i --) {
maxHeapify(i);
}
}
public void maxHeapify(int index) {
int left = getLeft(index);
int right = getRight(index);
int max = 0;
//left>=heapSize的话,说明当前index是最后一个非叶节点
while(left<heapSize) {
if (left<heapSize&&heap[left]>heap[max]) {
max = left;
}else {
max = index;
}
if (right<heapSize&&heap[right]>heap[max]) {
max = right;
}
if (max!=index) {
int temp = heap[index];
heap[index] = heap[max];
heap[max] = temp;
}else {
break;
}
//如果进行了交换,则可能头节点小于子节点,需要再次调整根堆
index = max;
left = getLeft(max);
right = getRight(max);
}
}
//得到左儿子节点的坐标
private int getLeft(int index) {
return 2*index+1;
}
public int getRight(int index) {
return 2*(index+1);
}
}·性能分析
堆排序的时间复杂度是O(N*logN),不需要额外的辅助数组,属于原地算法的一种,额外复杂度是O(1),同时,堆排序因为每次都要把堆首和堆尾值进行交换,所以它是不稳定的排序算法。
·希尔排序
·基本思想
希尔排序是插入排序的改进,插入排序是无序区与有序区相邻的比较,然后找到其合适的位置。而希尔排序则是先选定一个步长,按照这个步长,将其与之前的值(i与i-步长)进行比较,考虑是否改变二者的次序,逐渐缩小步长,直至步长为1则排序完毕。
·代码实现
/**
* @param arr 待排序数组
* @param index 初始的步长
*/
public void shellSort(int[] arr,int index) {
while(index>=1) {
for(int i = 0 ; i < arr.length ; i ++) {
for(int j = i ; j > 0+index-1 ; j --) {
if (arr[j]<arr[j-index]) {
int temp = arr[j];
arr[j] = arr[j-index];
arr[j-index] = temp;
}
}
}
index--;
}
}·性能分析
希尔排序的平均时间复杂度为O(N*logN),只需要交换元素位置时的额外空间,所以额外空间复杂度为O(1);另外,一步的插入排序是稳定的,但当步长>1的时候,相同的值可能与不同的值做比较,则会改变其相对位置,因此是不稳定的。