版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a_step_further/article/details/51638484
前言:
数据获取是数据分析师的职场必备技能,其中通过网络爬虫,自动、有组织地爬取一些网站数据,既实用,又有趣。本文通过对豆瓣新书速递页面及其子页面的迭代爬取,介绍python3环境下,网络爬虫的入门级用法。
其中的要点在于通过网页元素信息,定位到目标信息的标签格式,然后通过python的一些网络分析包,如 beautifulsoup 来有效提取相关信息。
一、要爬取的信息说明
豆瓣读书经常会推荐一些市面上的新书,其页面为https://book.douban.com/latest?icn=index-latestbook-all 。如果想查看每本书的详细信息,需要点击进去二级页面查看。那么,我们这里拿来练手的,就是先访问左下的介绍页面,获取推荐的书的总量,以及每本书的下一步页面链接,然后迭代访问每本书的详情页,找出书名、作者、评分信息。最终统一打印出来。
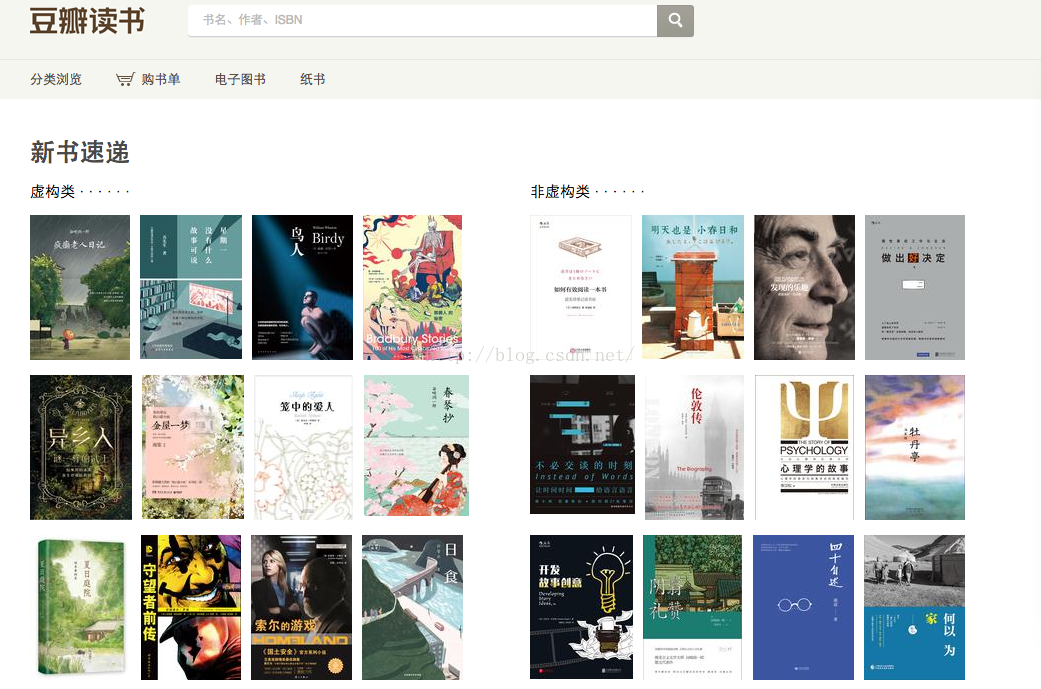

二、爬取过程
首先要通过查看见面元素信息,找到每个信息项的标签格式,如下图所示:
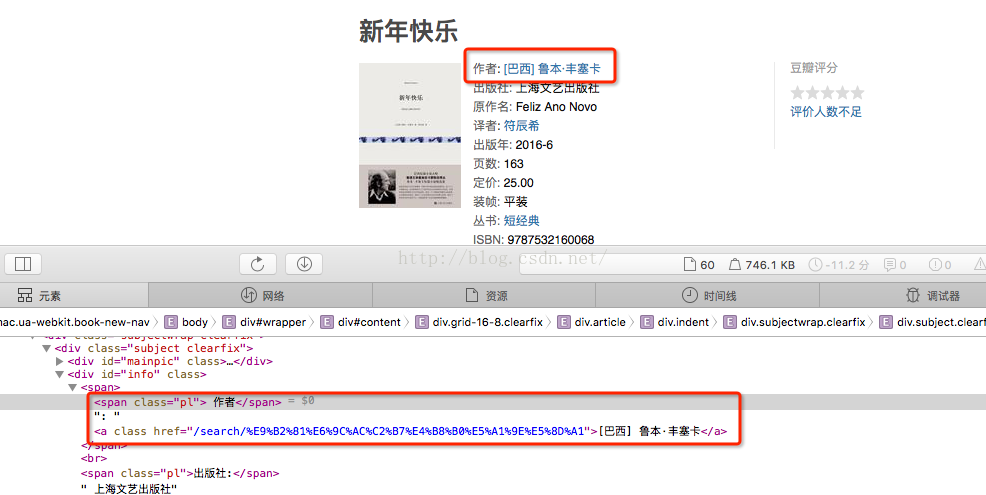
接下来就是要深入到细节,去研究beautifulsoup这类网络分析包的使用接口。针对本文的案例,完整版本的代码如下:
#!/usr/bin/env python3
# coding:utf-8
import datetime
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
def get_page_content(input_url):
try:
raw_page_content = urlopen(input_url)
except HTTPError as e:
print(e)
beautiful_page_content = BeautifulSoup(raw_page_content.read(), "html.parser")
return beautiful_page_content
if __name__ == "__main__":
douban_books_url = "https://book.douban.com/latest?icn=index-latestbook-all"
all_book_content = get_page_content(douban_books_url)
print("-------------- %s -------------- " % datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# 用正则表达式获取到页面上关于书的详细链接信息
book_link_pattern = re.compile("https://book.douban.com/subject/[0-9]+")
book_links = all_book_content.findAll("a", {"href": book_link_pattern})
print("本日豆瓣推荐新书量: %d" % len(book_links))
# 迭代地去访问每本书的链接,解析其中关于书的详细信息,如作者、售价、评分等
for link in book_links:
book_info_page_url = link.attrs["href"]
book_content = get_page_content(book_info_page_url)
book_name = book_content.find("span",{"property":"v:itemreviewed"}).getText()
if book_content.find("a",{"href":re.compile("/search/.*[%A-Z0-9]+")}) == None:
book_author = "未识别到作者"
else:
book_author = book_content.find("a",{"href":re.compile("/search/.*[%A-Z0-9]+")}).getText()
if book_content.find("a",{"href":"collections"}).getText() == "评价人数不足":
book_star = "暂无评分"
else:
book_star = book_content.find("strong", {"class": "ll rating_num "}).getText()
print("----------------------")
print("书名: %s" % book_name)
print("作者: %s" % book_author)
print("评分: %s" % book_star)
print("豆瓣链接: %s" % book_info_page_url)
实际执行的结果如下图所示:
