这段代码是一个爬取人民邮电出版社新书推荐信息的程序。它使用requests库发送HTTP请求,获取新书列表和每本书的详细信息,然后将数据保存到Excel文件中。具体的步骤如下:
- 导入所需的库:requests、json和openpyxl。
- 定义了一个URL变量,用于发送GET请求获取新书推荐列表的数据。
- 设置请求头信息,包括User-Agent和Cookie。
- 使用requests库的get()方法发送HTTP请求,并将响应内容解析为JSON格式。
- 定义了一个函数
save_excel(),用于创建Excel文件并保存数据。在该函数中,首先创建一个Workbook对象和一个Worksheet对象。 - 在Worksheet对象中创建一个标题行,然后遍历新书列表中的每本书,调用
json_detail()函数获取每本书的详细信息并保存到Excel中。 - 最后,使用openpyxl库的save()方法保存工作簿为Excel文件。
- 定义了一个函数
json_detail(),用于获取每本书的详细信息。在该函数中,使用POST方法发送HTTP请求,并通过bookId参数指定要获取的书的ID。 - 解析响应内容为JSON格式,获取书的作者和折扣价格,并返回这些信息。
- 在最后调用
save_excel()函数,将获取的数据保存到Excel文件中。
代码可以分为以下几个部分进行分块分析:
- 导入库
import requests
import json
import openpyxl
在这一部分中,导入了需要使用的库 requests、json 和 openpyxl。
- 定义请求URL和请求头信息
url = 'https://www.ptpress.com.cn/recommendBook/getRecommendBookListForPortal?bookTagId=d5cbb56d-09ef-41f5-9110-ced741048f5f'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
'Cookie': '...'
}
在这部分中,定义了请求的URL和请求头信息。URL是获取新书推荐信息的接口地址,headers包含了User-Agent和Cookie等信息。
- 发送请求获取JSON数据并解析
text_json = requests.get(url=url, headers=headers)
res = json.loads(text_json.content)
通过发送GET请求,获取新书推荐的JSON数据。然后将JSON数据解析为Python对象,并将其存储在变量 res 中。
- 定义保存到Excel的函数
save_excel
def save_excel(res):
wb1 = openpyxl.Workbook()
sheet = wb1.active
sheet.title = "人民邮电新书推荐"
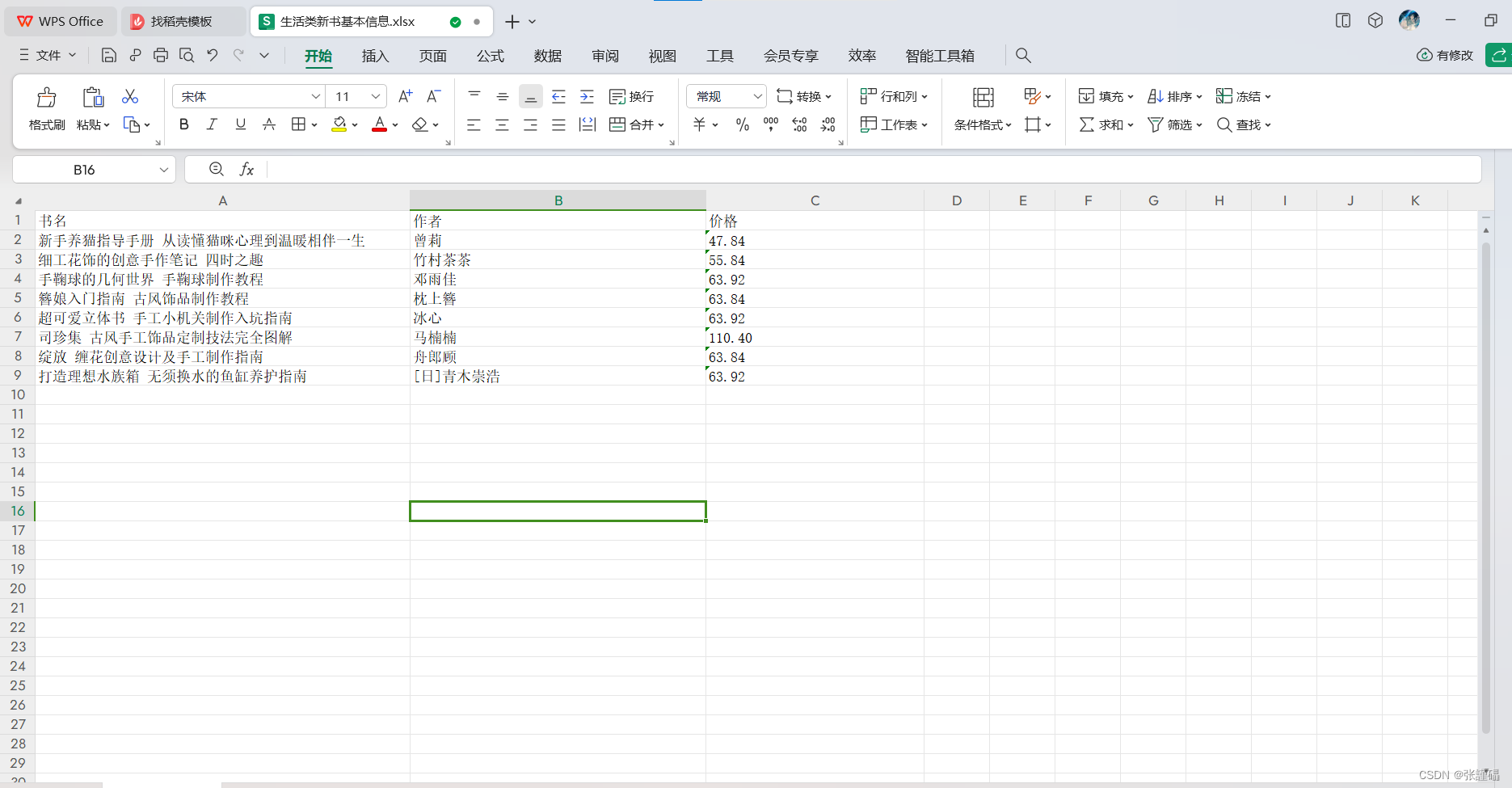
title = ['书名', '作者', '价格']
sheet.append(title)
for re in res['data']:
author, discountPrice = json_detail(re['bookId'])
sheet.append([re['bookName'], author, discountPrice])
wb1.save('生活类新书基本信息.xlsx')
这个函数用于将新书推荐信息保存到Excel文件。在函数内部,首先创建一个Excel工作簿,然后创建一个名为 “人民邮电新书推荐” 的工作表。接下来,添加表头信息到工作表中。然后,遍历每个书籍的信息,通过调用 json_detail 函数获取书籍的详细信息,并将其添加到工作表中。最后,保存Excel文件。
- 定义获取书籍详细信息的函数
json_detail
def json_detail(bookid):
url = 'https://www.ptpress.com.cn/bookinfo/getBookDetailsById'
params = {
'bookId': bookid,
}
text_json = requests.post(url=url, headers=headers, params=params)
res = json.loads(text_json.content)['data']
author = res['author']
discountPrice = res['discountPrice']
print(res['bookName'], author, discountPrice)
return author, discountPrice
这个函数用于通过书籍ID获取书籍的详细信息。在函数内部,首先构建获取书籍详细信息的接口URL,并设置书籍ID参数。然后,通过发送POST请求,获取书籍详细信息的JSON数据。接着,将JSON数据解析为字典,并提取出书籍的作者和折扣价格。最后,输出书籍的名称、作者和折扣价格,并将作者和折扣价格作为返回值返回。
- 调用保存到Excel的函数
save_excel(res)
在这部分代码中,调用了 save_excel 函数,将新书推荐信息保存到Excel文件中。
完整代码:
import requests
import json
import openpyxl
url = 'https://www.ptpress.com.cn/recommendBook/getRecommendBookListForPortal?bookTagId=d5cbb56d-09ef-41f5-9110-ced741048f5f'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44',
'Cookie': 'gr_user_id=796019e3-dc58-40f5-a6df-892a38008bcd; '
'acw_tc=2760822416373059896443147efcf3dd457a5539d63a07fdafd12f3041cd93; '
'JSESSIONID=A0FD72E84771D06417CF145392DAA679; '
'gr_session_id_9311c428042bb76e=1a1d8cc2-0de9-4409-adc4-07de4cdb503f;'
' gr_session_id_9311c428042bb76e_1a1d8cc2-0de9-4409-adc4-07de4cdb503f=true'
}
text_json = requests.get(url=url, headers=headers)
res = json.loads(text_json.content)
def save_execl(res):
wb1 = openpyxl.Workbook()
sheet = wb1.active
sheet.title = "人民邮电新书推荐"
title = ['书名', '作者', '价格']
sheet.append(title)
for re in res['data']:
author, discountPrice = json_detail(re['bookId'])
sheet.append([re['bookName'], author, discountPrice])
wb1.save('生活类新书基本信息.xlsx')
def json_detail(bookid):
url = 'https://www.ptpress.com.cn/bookinfo/getBookDetailsById'
bookid = bookid
params = {
'bookId': bookid,
}
text_json = requests.post(url=url, headers=headers, params=params)
res = json.loads(text_json.content)['data']
author = res['author']
discountPrice = res['discountPrice']
print(res['bookName'], author, discountPrice)
return author, discountPrice
save_execl(res)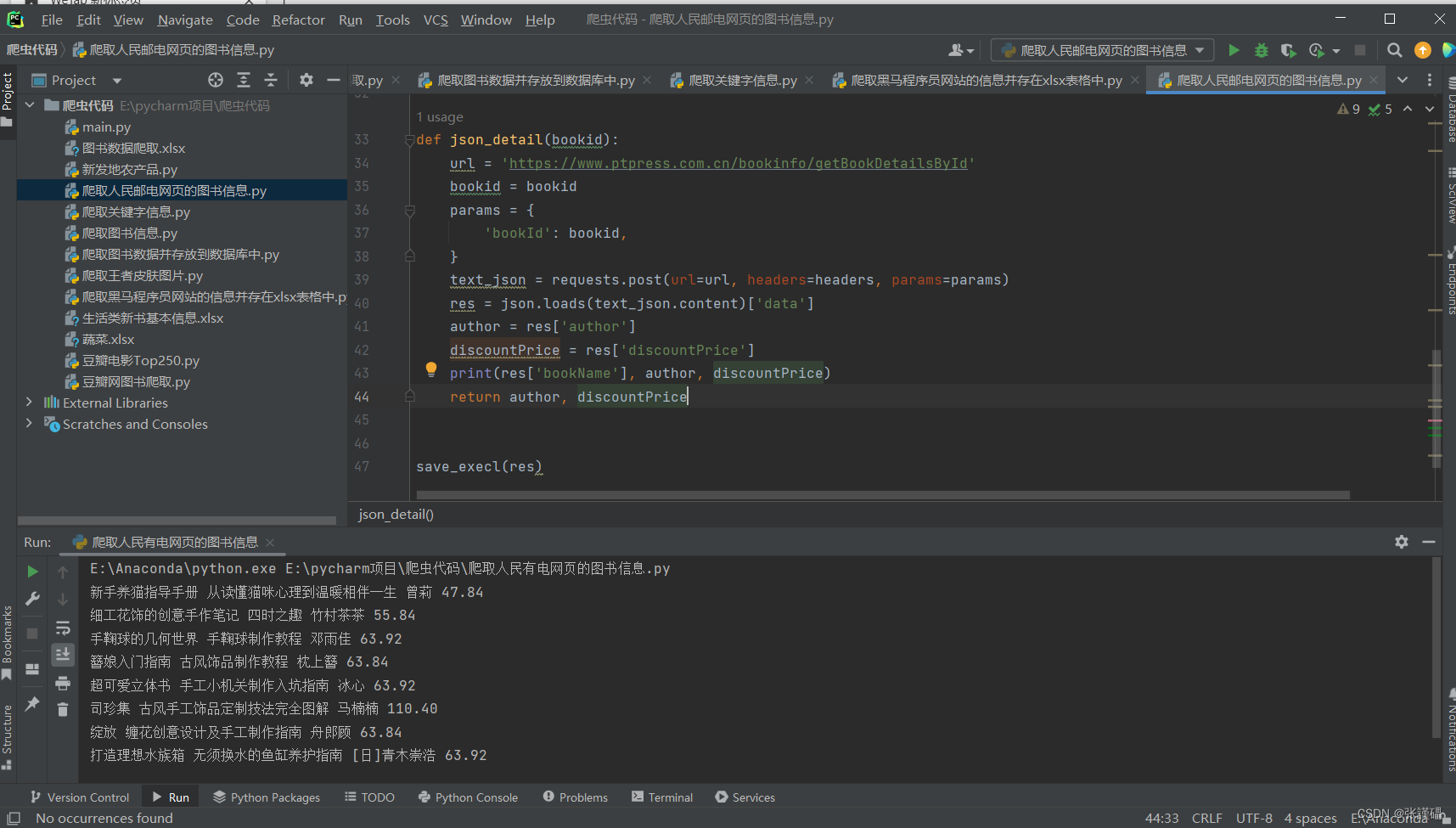
![]()