版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a_step_further/article/details/79360613
日常情况下,我们常常是从整洁的数据仓库表中读取数据,进行数据分析,但事实上,数据科学工作往往需要进行数据获取,预处理,分析,展示这样整个的流程。本文从一个实际的案例出来,将不同的分析工具串联起来(虽然仅用一种工具也能实现全流程工作,但不是本文的侧重点),目的是为了体现不同工具的特点和实际使用方法,有利于开拓思路。
任务说明
从新浪微博上爬取天猫超市微博消息的评论,进行分词,使用文字云的形式进行可视化。包括以下步骤:
1. 爬取新浪微博消息;本文使用python处理
2. 中文文本预处理,包括分词,剔除停用词,词频统计;本文使用spark处理
3. 文字云展示; 本文使用R处理
1. 数据获取
以下是天猫超市新浪微博最近发布的某条消息,下面有一些评论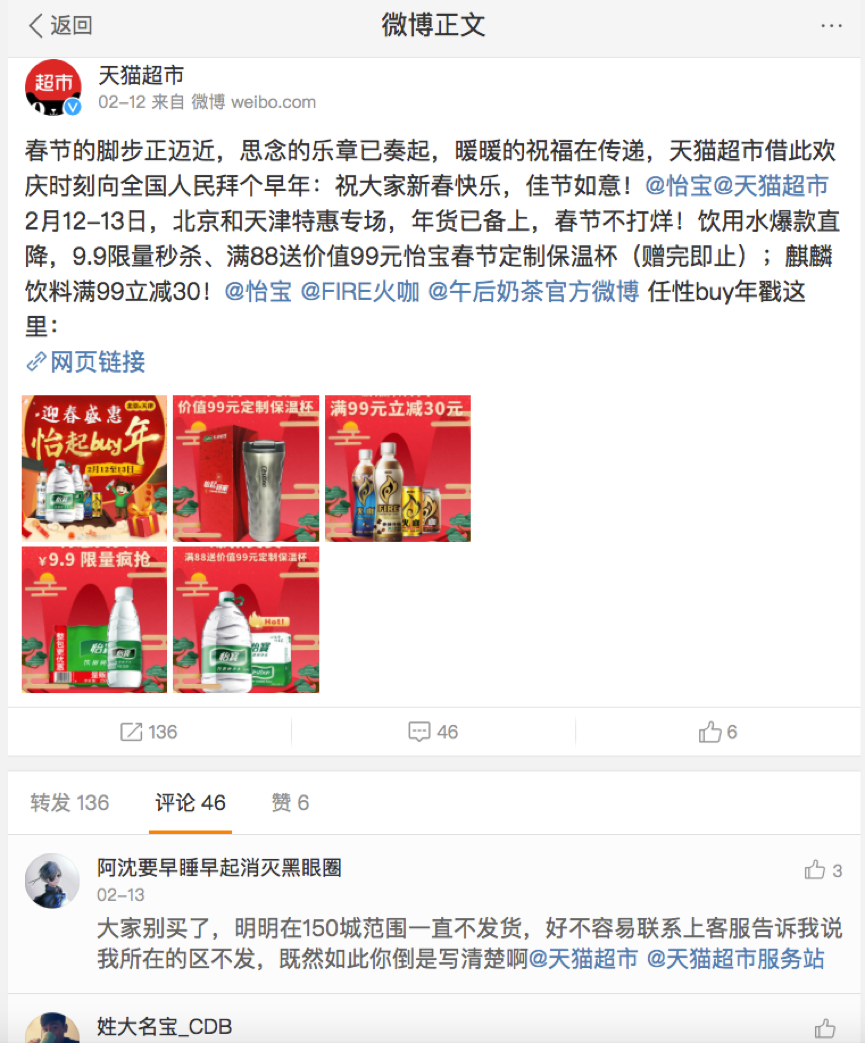
爬取的时候,从较容易的移动端网页入手,这里采用m.weibo.cn作为入手点,从浏览器窗口中可观察到每个微博消息的ID,如下图所示:
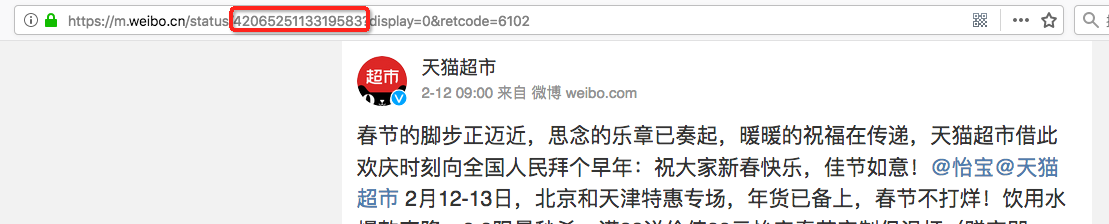
微博评论页面的链接格式为“https://m.weibo.cn/api/comments/show?id=”,这里的id即每个原始消息的ID,例如上面id=4206525113319583这条消息的评论页面如下
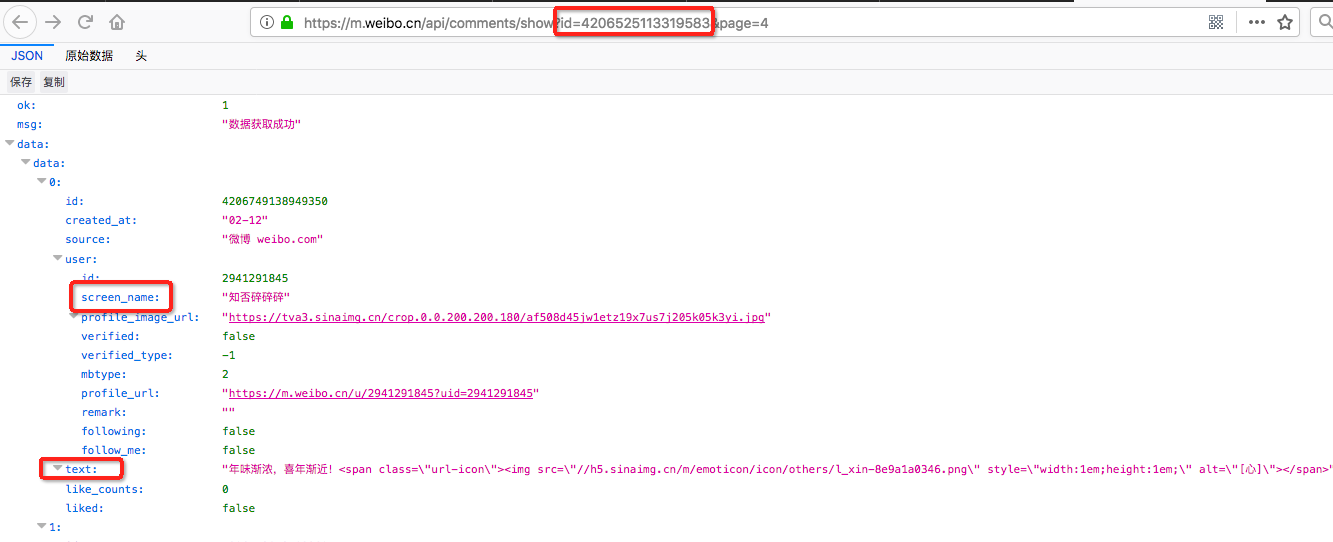
其中screen_name是评论者的微博账号,text是评论消息文本
接下来就是用python去批量爬取这类评论消息喽。直接上代码吧:
接下来就是用python去批量爬取这类评论消息喽。直接上代码吧:
#/usr/bin/env python
#coding:utf-8
import requests
from bs4 import BeautifulSoup
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# 保存评论者的ID,微波昵称,评论时间,评论内容
class comment_clss:
user_id = ""
user_screen_name = ""
comment_date = ""
comment_text = ""
def __init__(self, user_id, user_screen_name, comment_date, comment_text ):
self.user_id = user_id
self.user_screen_name = user_screen_name
self.comment_date = comment_date
self.comment_text = comment_text
def get_url_content(url):
mycookie = "这里替换为你自己的cookie"
User_Agent= '''这里替换为你自己的浏览器agent'''
headers = {"Cookie":mycookie, "User-Agent":User_Agent}
html = requests.get(url,headers)
return BeautifulSoup(html.text, "html.parser")
def get_comment_list(comment_url):
#从HTML评论页面中提取评价内容,并存储到LIST中
comment_str = json.loads(str(get_url_content(comment_url).text))
#判断评论页面是否有内容
ok_flag = comment_str['ok']
if ok_flag == 0:
return []
#数据转换
comment_list = []
for i in range(len(comment_str['data']['data'])):
comment_user_id = comment_str['data']['data'][i]['user']['id']
comment_user_nick = comment_str['data']['data'][i]['user']['screen_name']
#过滤掉天猫超市官方的回复
if comment_user_nick == u"天猫超市服务站":
continue
comment_date = comment_str['data']['data'][i]['created_at']
comment_content = comment_str['data']['data'][i]['text']
comment_instance = comment_clss(comment_user_id,comment_user_nick,comment_date,comment_content)
comment_list.append(comment_instance)
return comment_list
if __name__ == "__main__":
#猫超官微ID列表,取最近几条
mc_msg_id = ['4206525113319583','4206525113319583','4204017897256497','4203049012066799']
#对于每篇微博,提取前20页的评论
all_comment = []
for msg_id in mc_msg_id:
for i in xrange(20):
comment_url = "https://m.weibo.cn/api/comments/show?id=" + msg_id + "&page=" + str(i)
cur_list = get_comment_list(comment_url)
if cur_list == []:
continue
else:
all_comment.extend(cur_list)
# print len(all_comment)
print "总评论数量: %d" % len(all_comment)
#将结果写入本地文件
print "开始写入本地文件"
w_file = "替换为你自己的文件路径"
with open(w_file,'w') as file:
for cmt in all_comment:
file.write(cmt.user_screen_name)
file.write("\t")
file.write(cmt.comment_date)
file.write("\t")
file.write(cmt.comment_text)
file.write("\n")
print "写入文件完成"2. 文本处理
获取到文本后,接下来就是进行中文分词,词频统计,这里可用的工具就非常多了(python中常用jieba分词 ), 本文采用HanLP这个文本处理工具,并用spark作为执行脚本,代码如下:import com.hankcs.hanlp.HanLP
import com.hankcs.hanlp.dictionary.CustomDictionary
import com.hankcs.hanlp.dictionary.stopword.CoreStopWordDictionary
import com.hankcs.hanlp.tokenizer.StandardTokenizer
import org.apache.spark.{SparkConf, SparkContext}
object textAanlysis {
def main(args: Array[String]): Unit ={
val conf = new SparkConf().setAppName("textAnalysis").setMaster("local[1]")
val sc = new SparkContext(conf)
val filename = "替换为你自己的文件路径"
val text = sc.textFile(filename)
.map(_.split("\t"))
.map(x => x(2))
.map{ (line) =>
HanLP.Config.ShowTermNature = false
val segment = HanLP.newSegment().enableCustomDictionary(true).enableAllNamedEntityRecognize(false)
//增加一些需要过滤的无用词
CoreStopWordDictionary.add("快递")
CoreStopWordDictionary.add("天猫")
CoreStopWordDictionary.add("过年")
CoreStopWordDictionary.add("回复")
CoreStopWordDictionary.add("超市")
//分词
val list = segment.seg(line)
CoreStopWordDictionary.apply(list)
list.toString.replaceAll(", span>","").replaceAll("[<a> a-z]+","").replaceAll("[\\[\\]]","").replaceAll("\\/[a-z]+,", "")
}
text.take(10).foreach(println)
val wordFreq = text.flatMap(x => x.split(",")).filter(!_.isEmpty).map(x => (x,1)).reduceByKey(_+_).map(x => (x._2, x._1)).sortByKey(ascending = false).map(x => (x._2, x._1))
// wordFreq.foreach(println)
wordFreq.saveAsTextFile("替换为自己的文件路径")
sc.stop()
}
}3. 文字云可视化
使用wordcloud来进行词云展示,这个东东在python, R中都可以使用,这里使用R来处理,仅3行代码就可以搞定:library(wordcloud2)
data = read.delim("替换为你自己的文件路径",sep=",",header = FALSE)
wordcloud2(data = data,figPath = "引入天猫头像的图片,作为背景图片")