版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a_step_further/article/details/79383405
书接上回(文章 http://blog.csdn.net/a_step_further/article/details/79360613 使用了python去爬取微博评论消息,再使用spark做预处理,用R做可视化),这次再换个姿势练习一下,思路是相近的,换换工具练手的目标仍然是活跃下思维。
任务说明
- 爬取新浪微博消息;这一次使用java处理
- 中文文本预处理,这次的聚焦点在于文本中姓名的提取;这一次使用java处理
- 文字云展示; 这一次仍使用R处理
1. 数据获取
这次我们选取新浪微博春晚官方账号下的评论消息来玩数据,看看大家对于哪些明星提及次数最多 :)
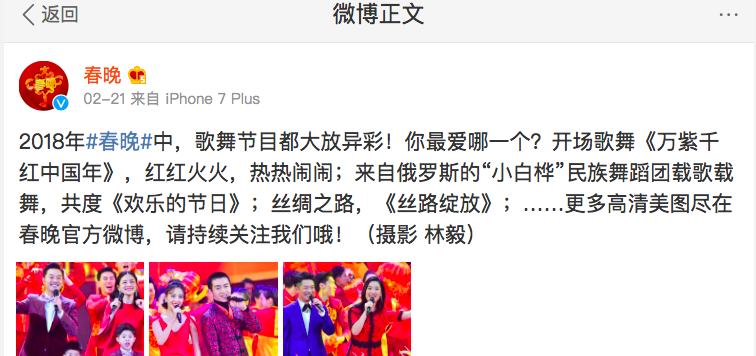

有了上篇文章的基础,网页上评论内容格式不再赘述,直接上完整代码:
import net.sf.json.JSONArray;
import net.sf.json.JSONObject;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
public class spider {
public static ArrayList<String> getWeiboComment(String url) throws IOException{
ArrayList<String> commentStr = new ArrayList<String>();
Document doc = Jsoup.connect(url).userAgent("User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/604.5.6 (KHTML, like Gecko) Version/11.0.3 Safari/604.5.6").ignoreContentType(true).get();
//获取纯文本内容,注意不要使用doc.html(),否则返回的是html格式,会自动添加一大堆属性标签,反而不利于后续使用
JSONObject jo = JSONObject.fromObject(doc.text());
//根据页面内容的格式,定制化数据解析的方法
if(! jo.getString("msg").equals("数据获取成功")){
return commentStr;
}
JSONObject innerData = JSONObject.fromObject(jo.get("data"));
JSONArray ja = JSONArray.fromObject(innerData.get("data").toString());
for(int i = 0; i < ja.size(); i ++){
JSONObject j = ja.getJSONObject(i);
JSONObject user = j.getJSONObject("user");
String userID = user.getString("id"); //评论者微博ID
String userWeiboNick = user.getString("screen_name"); //评论者微博账号
String commentMsg = j.get("text").toString(); //评论消息
// System.out.println(userID + "\t" + userWeiboNick + "\t" + commentMsg);
commentStr.add(commentMsg);
}
return commentStr; //这里仅返回评论来使用
}
public static void main(String[] args) throws IOException {
String url = "https://m.weibo.cn/api/comments/show?id=4209863149676685";
//取前N页评论
ArrayList<String> allComment = new ArrayList<String>();
for(int i = 0;i < 30; i++){
ArrayList<String> tmp = getWeiboComment(url + "&page=" + i);
allComment.addAll(tmp);
}
System.out.println("共爬取到" + allComment.size() + "条微博评论消息,分别为:");
for(String s: allComment){
System.out.println(s);
}
//写入本地文件
System.out.println("开始写入本地文件");
String filename = "~/weibo_comment.txt";
BufferedWriter bw = new BufferedWriter(new FileWriter(filename));
for(String s: allComment){
bw.write(s + "\n");
}
System.out.println("写入本地文件完成");
bw.close();
}
}
执行结果如下图所示:

2. 中文文本预处理
有了评论消息后,我们来提取出其中的人名,仍然使用HanLP这个包,它可以识别中国人名,将词性标注为nr: 。 添加maven依赖:
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.2.8</version>
</dependency>要想提取人名,首先得能识别,运行结果如下图:

可以看到不少人名都被标注为了nr的属性,but, 细看一下,貌似有个“易烊/nr, 千/m, 玺/ng”,这个看上去有点眼熟,百度了一下才知道这四个字是一个完整的人名(请原谅一个80后对于现如今娱乐圈的陌生),通过在分词词典中添加自定义词语可以实现完整的提取,如下所示:

呃,发现这个词被标注为了nz的属性(其他专名),暂时在分词这里忽略它吧,无关大局,重点是知道怎样添加新词到词典中。
以下是完整代码:
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.corpus.tag.Nature;
import com.hankcs.hanlp.dictionary.CustomDictionary;
import com.hankcs.hanlp.seg.Segment;
import com.hankcs.hanlp.seg.common.Term;
import java.io.*;
import java.util.*;
public class extractName {
public static void main(String[] args) throws IOException {
String filename = "~/weibo_comment.txt";
InputStream file = new FileInputStream(new File(filename));
BufferedReader in = new BufferedReader(new InputStreamReader(file,"utf-8"));
String line;
ArrayList<String> allComment = new ArrayList<String>();
while((line = in.readLine()) != null){
allComment.add(line);
}
HashMap<String, Integer> nameFreq = new HashMap<String, Integer>();
Segment segment = HanLP.newSegment().enableNameRecognize(true).enableCustomDictionary(true); //开启姓名识别的选项
CustomDictionary.add("易烊千玺");
for(String comment: allComment){
System.out.println(comment);
List<Term> termList = segment.seg(comment); //分词
// System.out.println(termList);
//对于同一个评论消息,可能反复提及一个人名,为了不重复计数,每条消息中提到的每个人名仅计算1个频次
HashSet sameMsgName = new HashSet();
for(Term word: termList){
if(word.nature.equals(Nature.nr)){
String name = word.toString().replace("/nr","");
sameMsgName.add(name);
// System.out.println(name);
}
}
//统计每个名字的词频
Iterator it = sameMsgName.iterator();
while(it.hasNext()){
String name = it.next().toString();
if(nameFreq.keySet().contains(name)){
nameFreq.put(name, nameFreq.get(name) + 1);
}else{
nameFreq.put(name, 1);
}
}
}
//同时写入本地文件,便于下个环节的使用
String writeFile = "~/weibo_comment_name_freq.txt";
BufferedWriter bw = new BufferedWriter(new FileWriter(writeFile));
Iterator it = nameFreq.entrySet().iterator();
while(it.hasNext()){
HashMap.Entry entry = (HashMap.Entry) it.next();
String name = entry.getKey().toString();
Integer freq = Integer.parseInt(entry.getValue().toString());
// System.out.println(name + "\t" + freq);
bw.write(name + "," + freq.toString() + "\n");
}
bw.close();
}
}
3. 文字云可视化
使用与上篇文章同样的方法,
library(wordcloud2)
data = read.delim("文件路径",sep=",",header = FALSE)
wordcloud2(data = data,figPath = "引入一个背景图片")