提起链式存储结构,其与数组是两个非常基础的数据结构,每当提到链式存储结构时,一般情况下我们都会将其与数组放到一块儿来比较。
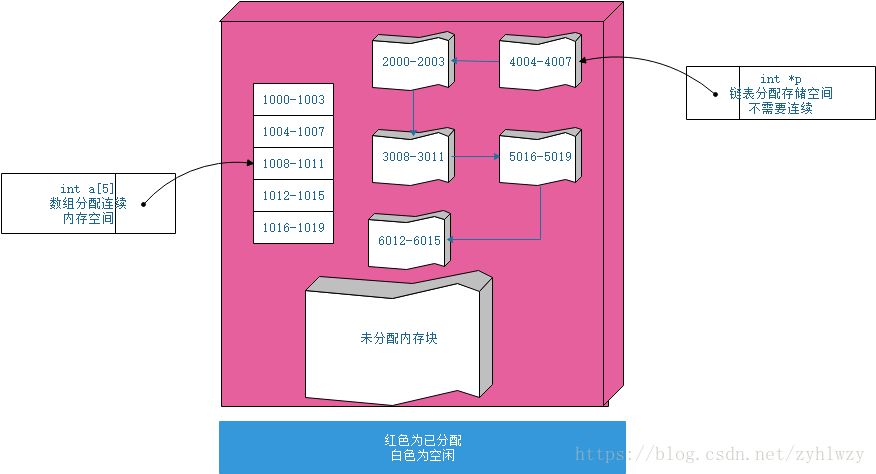
对于数组与链表,从结构上来看,数组是需要一块连续的内存空间来存储数据,对内存的要求非常高,比如说我们申请一个100M大小的数组,而如果我们的内存可用空间大于100M,但是没有连续的100M可用空间,那即便是我们的内存空间充足,在申请空间时也会申请失败。
而对于链表来说,他对内存空间的要求就不会有那么高,它并不需要一块连续的内存空间,只要内存空间充足,即使内存空间存在碎片,只要碎片的大小足够存储一个链表节点的数据,该碎片的空间都有可能被分配,链表通过指针或者引用的方式将一组零散的空间串联起来使用。所以如果一个链表需要100M的空间,但是如果内存空间充足,但是没有一个连续的空间大于100M,也不会影响链表的空间分配。
对于链式存储结构,一般情况下我们遇到最多且最常用的大概有单向链表,双向链表,循环链表三种。
链表是通过指针或者引用将分散的内存块链接在一起,我们把串联在链表上的每一个内存块称为链表的节点。
单向链表
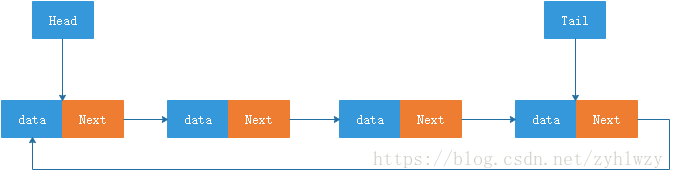
在链表结构中,每个节点仅存储本身需要存储的数据和下一个节点地址的这种链表结构,我们称为单链表结构,其示意图如下:

如图所示,在单链表中的每个节点中,除了数据区域外,还有一个区域存储了当前节点的下一节点的地址,我们把这个记录下个结点地址的指针或引用叫作后继指针或引用Next。
在我们的单链表结构中,有两个节点比较特殊,那就是第一个节点和最后一个节点。在链式存储结构中,我们将第一个节点称为头结点,将最后一个节点称为尾节点。头节点记录链表的起始地址,有了这个地址,我们就可以遍历整个链表。尾节点的后继指针或者引用不是指向一个具体的节点,而是指向一个空地址NULL,从而表示该节点为链表的尾节点。
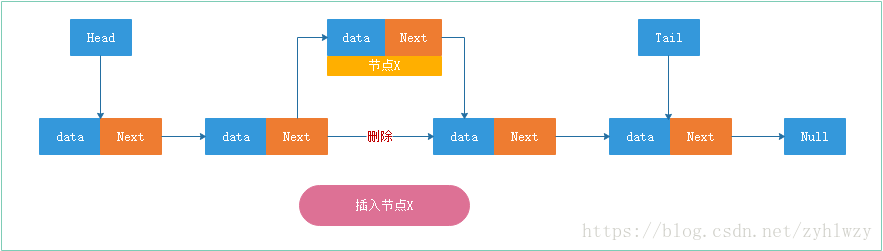
与数组一样,链表也支持数据的插入、查找、删除。
但是我们都知道,数组在进行数据的插入,删除操作时,为了保证内存数据的连续性,往往需要做大量的数据搬移工作,所以时间复杂度是O(n)。而在链表中插入或删除数据时,因为链表结构中的节点并不需要连续的存储空间,所以在链表中进行数据的插入和删除时并不需要搬移节点。对于链表的删除和插入操作,我们只需要调整相邻节点的后继指针即可,所以对应的时间复杂度是O(1)。
和数组相比,链表如果需要访问第k个元素,就没有数组那么简单了。因为数组的内存数据是连续的,当我们需要访问第k个元素时,通过基地址(base_address)和数据类型大小就可以随机访问到数据所在的内存地址。
array[k]_address=base_address+k*data_type_size;
但是对于链表来讲,因为链表中各个节点的数据在内存中时分散的,不像数组那样是连续的存储空间,所以要访问链表中的第k个元素,只能从头结点开始,根据节点间的后继指针或引用逐一遍历,直到找到相应的节点,所以链表的随机访问的性能没有数组好,时间复杂度为O(n)。
循环链表
说完单链表,我们继续来看一下循环链表。循环链表是一种特殊的单链表,特殊之处在于,我们在单链表中,尾节点的后继指针或者引用不是指向一个具体的节点,而是指向一个空地址NULL,表示这就是最后一个节点。而将单链表的尾节点从指向空地址NULL调整为指向头结点Head,就形成了循环链表。
和单链表相比,循环链表的优点是从链尾到链头比较方便。当要处理的数据具有环型结构特点时,就特别适合采用循环链表。比如著名的约瑟夫问题,尽管用单链表也可以实现,但是用循环链表实现的话,代码就会简洁很多。
双向链表
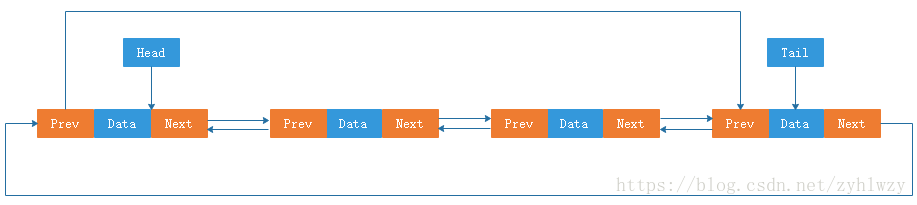
单向链表是单向的,只有一个后继指针或者引用Next指向后面的节点,而双向链表,指的是一个链表结构,它支持两个方向,每个节点不止只有一个后继指针或者引用Next指向后继节点,还有一个前驱指针或者引用Prev指向前面的节点。

从图中可以得知,双向链表需要额外的空间来存储后继节点和前驱节点的地址,所以,存储同样多的数据,双向链表要比单向链表需要的存储空间要多。虽然两个指针或者引用比较浪费存储空间,但可以支持双向遍历,这样也带来了双向链表操作的灵活性。
从双向链表的结构看,双向链表可以在O(1)的时间复杂度下找到前驱节点,基于此特性,在某些特殊的场景下,对节点的删除和插入操作,双向链表比单向链表会更高效。
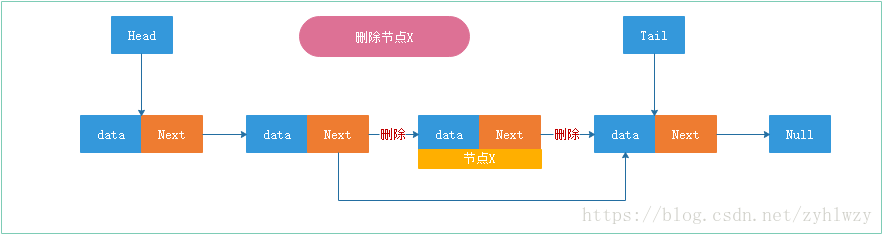
我们先看一下删除指定指针或引用指向的节点操作。
- 要删除指定指针或引用指向的节点,首先我们需要遍历整个链表,找到指定的节点X;
- 找到节点X之后,我们需要找到其前驱节点,对于单向链表来说,他是不支持直接获取前驱节点的,所以我们还需要重新再遍历一遍整个链表,找到节点X的前驱节点才能执行删除操作;
- 对于双向链表来说,这种情况就比较有优势了,找到指定节点X之后,它并不需要重新再遍历一遍链表寻找前驱节点,因为双向链表中的结点已经保存了前驱结点的指针或者引用;
- 所以对于找到了指定节点X并删除节点的情况,单向链表删除操作需要O(n)的时间复杂度,而双向链表只需要O(1)的时间复杂度;
如果我们希望在链表的某个指定结点X前面插入一个结点,双向链表比单向链表也有很大的优势。双向链表可以在O(1)的时间复杂度内完成,而单向链表需要O(n)的时间复杂度才能完成。具体原因和我们上述的删除类似。
基于双向链表在特定情况下相对于单向链表的优势,所以在我们实际的开发过程中,尽管双向链表相对耗内存,但是还是比单向链表应用广泛。比如在Java语言中LinkedHashMap 的实现原理也用到了双向链表。
双向循环链表
上面我们说了单向链表、循环链表、双向链表,我们将循环链表和双向链表整合在一起,就形成了双向循环链表。
通过前面内容的探讨,我们应该已经知道,数组和链表是两种截然不同的内存组织方式。正是因为内存存储的区别,它们插入、删除、随机访问操作的时间复杂度正好相反。
不过,数组和链表的对比,并不能局限于时间复杂度。而且,在实际的软件开发中,不能仅仅利用复杂度分析就决定使用哪个数据结构来存储数据,一切都要根据具体情况具体分析,合适最好,共勉之。