首先,我们应该先了解计算机内部的物理存储结构。
计算机的主要外存就是软盘和硬盘,现在光说硬盘,硬盘是由一个个盘面组成的,每个盘面上由两个磁头读取数据(正反面)。
每个盘面上分为若干个扇区。

这里主要用到堆和栈。
堆是存储的是数组和对象(其实数组就是对象),凡是new建立的都是在堆中,堆中存放的都是实体(对象),实体用于封装数据,而且是封装多个(实体的多个属性),如果一个数据消失,这个实体也没有消失,还可以用,所以堆是不会随时释放的,但是栈不一样,栈里存放的都是单个变量,变量被释放了,那就没有了。堆里的实体虽然不会被释放,但是会被当成垃圾,Java有垃圾回收机制不定时的收取。
栈首先是一片内存区域,存储的都是局部变量,凡是定义在方法中的都是局部变量(方法外的是全局变量),for循环内部定义的也是局部变量,是先加载函数才能进行局部变量的定义,所以方法先进栈,然后再定义变量,变量有自己的作用域,一旦离开作用域,变量就会被释放。栈内存的更新速度很快,因为局部变量的生命周期都很短。
而存储数据主要是线性结构、链式结构。
线性结构也叫顺序结构,他是把相邻的节点存储在物理位置相邻的存储单元里,通常借助于程序设计中的数组方式来具体实现,所以对应的,数组存储的优缺点也是线性结构存储的优缺点。下面再详细说说两种存储方式的优缺点。
链式结构,它不要求逻辑上相邻的节点在物理位置上也相邻,节点间的逻辑关系是由附加的指针字段表示的,通常借助于程序设计中的指针结构来实现。
下面再说说两者存储方式的优缺点:
线性结构的优点是可以实现随机读取,时间复杂度为O(1),空间利用率高,缺点是进行插入和删除操作时比较麻烦,时间复杂度为O(n),同时容量受限制,需要事先确定容量大小,容量过大,浪费空间资源,过小不能满足使用要求,会产生溢出问题。
链式存储结构的优点主要是插入和删除非常简单,前提条件是知道操作位置,时间复杂度是O(1),但如果不知道造作位置则要定位元素,时间复杂度为O(n),没有容量的限制,可以使用过程中动态分配的分配内存空间,不用担心溢出问题,但是它并不能实现随机读取,同时空间利用率不高。
下面用java示例程序分析链式存储结构。
首先创建一个实体类Person.class,用来作为链表的数据。
public class Person {
public String name;
public int age;
public String xueli;
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + ", xueli=" + xueli + "]";
}
}其次,创建一个链表类:LinkNode.class,用来作为链表的单个节点。
public class LinkNode<M> {
public M data;
public LinkNode nextNode;
@Override
public String toString() {
return "LinkNode [data=" + data + ", nextNode=\n" + nextNode + "]";
}
}
这里面,M作为泛型限制着data的类型,也就是上面的Person类,还有一个类似于指针功能的nextNode用来指向下一个节点。
最后创建一个测试类:MainTest.class 里面创建了一个具有一个101个节点的链表。
public class MainTest {
public static void main(String [] ddd) {
//根节点
LinkNode<Person> personLink0 = new LinkNode<Person>();
//节点内的数据
Person xizhuang = new Person();
xizhuang.age = 22;
xizhuang.name ="王喜壮";
personLink0.data =xizhuang;
//创建一个节点,不实例化,只做指针的功能,用来指向最后一个节点,现在personLink0就是最后一个节点
LinkNode<Person> personLinkLast = personLink0;
//循环生成100个节点,并将他们连起来
for(int i = 0; i < 100; i++) {
//生成新的节点
LinkNode<Person> personLinknext = new LinkNode<Person>();
//放入不同的数据
Person personi = new Person();
personi.age = 30 + i;
personi.name ="张彤" + i;
personLinknext.data = personi;
//现在把新生成的节点添加到原来链表的后边。
personLinkLast.nextNode = personLinknext;
//更改最后一个节点的指向,指向现在新生成的节点。直到完成循环。
personLinkLast = personLinknext;
}
System.out.println(personLink0);
}
}
输出结果为:
LinkNode [data=Person [name=王喜壮, age=22, xueli=null], nextNode=
LinkNode [data=Person [name=张彤0, age=30, xueli=null], nextNode=
LinkNode [data=Person [name=张彤1, age=31, xueli=null], nextNode=
LinkNode [data=Person [name=张彤2, age=32, xueli=null], nextNode=
......................................
LinkNode [data=Person [name=张彤97, age=127, xueli=null], nextNode=
LinkNode [data=Person [name=张彤98, age=128, xueli=null], nextNode=
LinkNode [data=Person [name=张彤99, age=129, xueli=null], nextNode=
null]下面来堆栈的知识分析这个
首先,执行循环之前的操作,第一步:生成第一个节点,赋入数据,并把最后一个节点指向这个节点
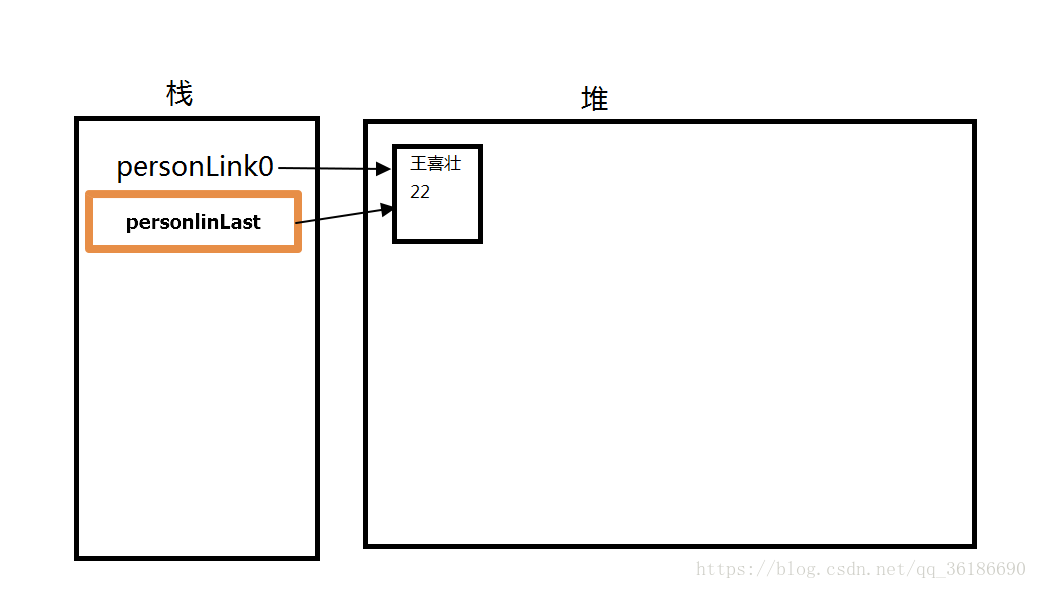
然后进入循环后的i=0时

i=1时
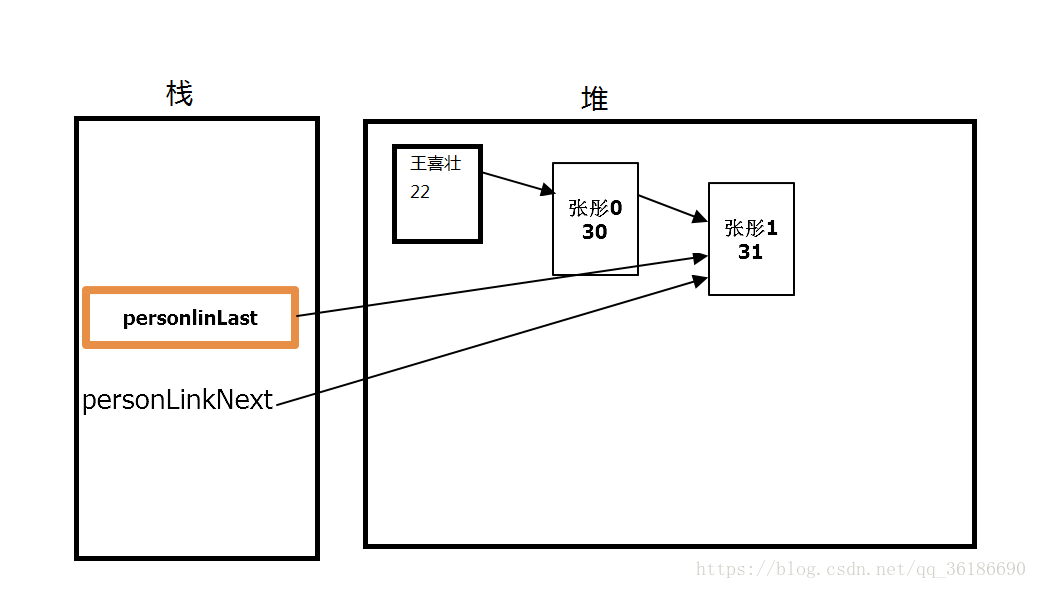
i=2时
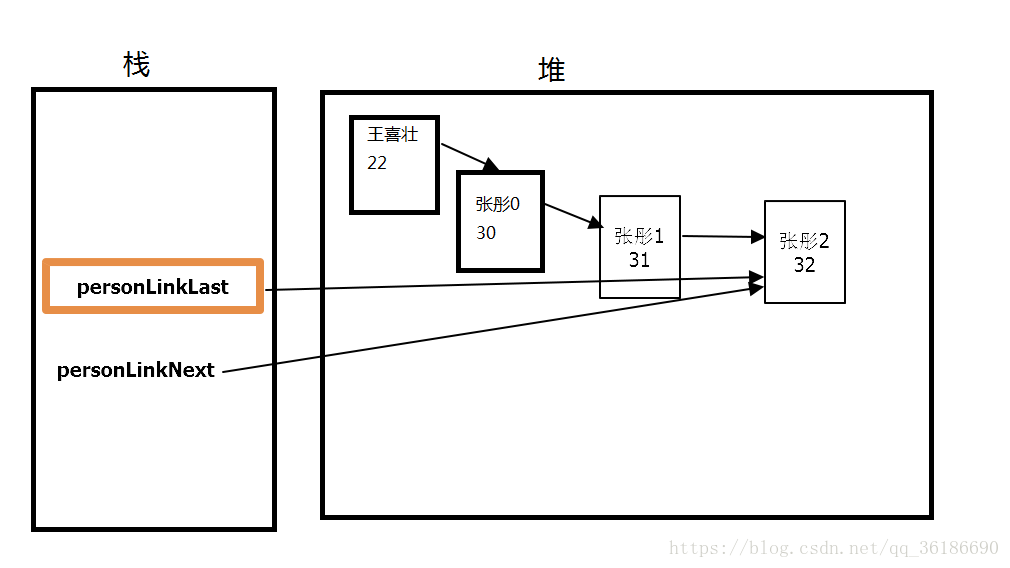
i=3时

以此类推,直到完全生成一个101个节点的链表。分析图以下省略。
注意,personlinkLast不能实例化,也就是new,因为实例化就等于在堆里分配了空间,他就会一直有一个空的内存块,占用着内存,虽然一个问题不是很大,但是如果多了。就会影响程序的运行速度。示例图如下。
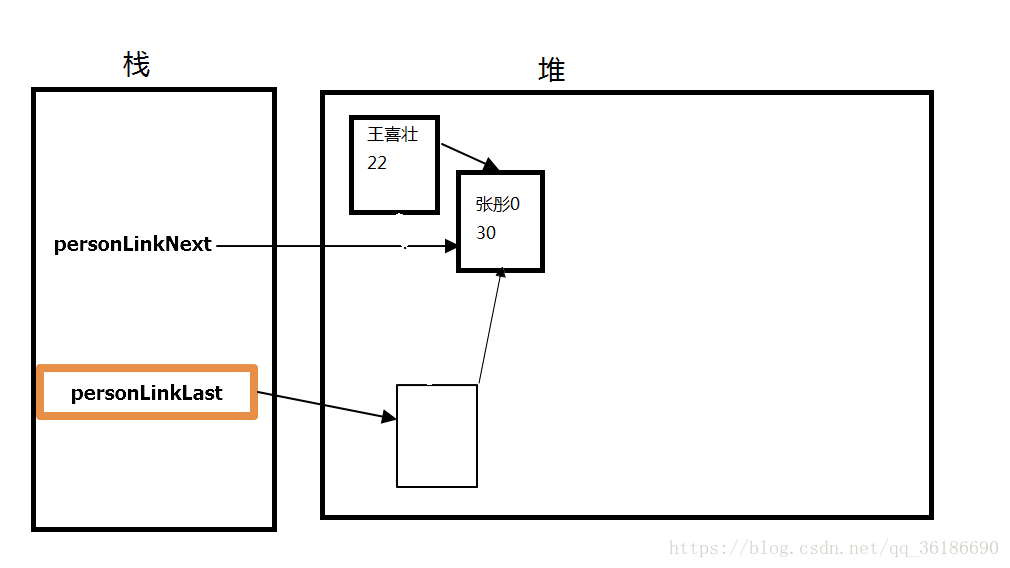
总结一下,这里主要了解了计算机的硬盘的物理存储结构,堆、栈的概念、和两种存储结构的优缺点,并用java演示并分析的链表的存储方式。
以下附上git方式下载的源文件,供大家参考,Test->Test0527