栈的链式存储结构称为链栈,对于链栈来说,基本不存在栈满的情况,除非内存已经没用可以使用的空间,如果真的存在这种情况的话,那么就说明此时的计算机操作系统已经快要死机了,那么我们就没必要再去关注溢出的问题了
关于链栈的结构如下所示
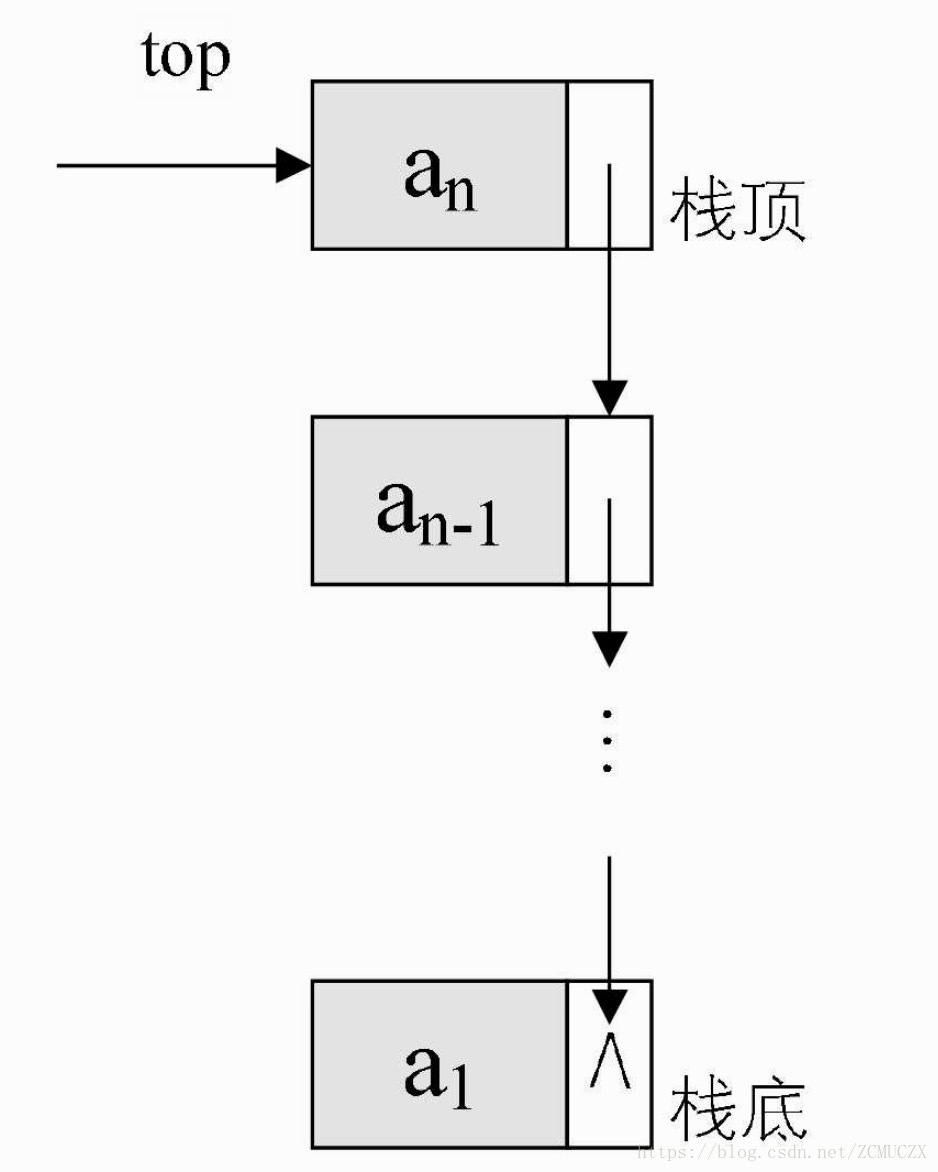
关于链栈的程序定义如下所示
typedef struct StackNode
{
SElemType data;
struct StackNode *next;
} StackNode, *LinkStackPtr;
typedef struct LinkStack
{
LinkStackPtr top;
int count;
} LinkStack;关于链栈的进栈操作如下所示
“/* 插入元素e为新的栈顶元素 */
Status Push(LinkStack *S, SElemType e)
{
LinkStackPtr s
= (LinkStackPtr)malloc(sizeof(StackNode));
s->data = e;
/* 把当前的栈顶元素赋值给新结点的直接后继 */
s->next = S->top;
/* 将新的结点s赋值给栈顶指针*/
S->top = s;
S->count++;
return OK;
}关于链栈的出栈操作的程序定义
/* 若栈不空,则删除S的栈顶元素,用e返回其值,
并返回OK;否则返回ERROR */
Status Pop(LinkStack *S, SElemType *e)
{
LinkStackPtr p;
if (StackEmpty(*S))
return ERROR;
*e = S->top->data;
/* 将栈顶结点赋值给p*/
p = S->top;
/* 使得栈顶指针下移一位,指向后一结点*/
S->top = S->top->next;
/* 释放结点p */
free(p);
S->count--;
return OK;
} 链栈的出栈和入栈操作都比较简单,时间复杂度都为O(1),顺序栈和链栈在时间复杂度上面是一样的
对于空间性能,顺序栈需要事先确定一个固定的长度,可能会存在内存空间浪费的问题,但它的优势是存取时定位很方便,而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。所以它们的区别和线性表中讨论的一样,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些
其实栈的引入就是为了简化程序设计的问题,划分了不同的关注的层次,这样可以使得我们的思考范围缩小,使我们能够更加聚焦于我们要解决的问题核心