从线性分类器谈起
给定一些数据集合,他们分别属于两个不同的类别。例如对于广告数据来说,是典型的二分类问题,一般将被点击的数据称为正样本,没被点击的数据称为负样本。现在我们要找到一个线性分类器,将这些数据分为两类(当然实际情况中,广告数据特别复杂,不可能用一个线性分类器区分)。用X表示样本数据,Y表示样本类别(例如1与-1,或者1与0)。我们线性分类器的目的,就是找到一个超平面(Hyperplan)将两类样本分开。对于这个超平面,可以用以下式子描述:
对于logistic回归,有:
其中
这个公式,对机器学习稍微有点了解的同学可能都特别熟悉,不光在logistic回归中,在SVM中,在ANN中,都能见到他的身影,应用特别广泛。大部分资料在谈到这个式子时候,都是直接给出来。但是不知道大家有没有想过,既然这个式子用途这么广泛,那我们为什么要用它呢?
是不是已经有好多人愣住了。大家都是这么用的。书上都是这么写的啊。是的,但是当一个东西老在你眼前晃来晃去的时候,你是不是应该想想为什么呢?反正对于我来说,如果一个东西在我眼前都出现了第三次了而我还不知其所以然,我一定会去想方设法弄明白为什么。
为什么要用Logistic函数
学过模式识别的同学肯定学过各种分类器。分类器中最简单的自然是线性分类器,线性分类器中,最简单的应该就属于感知器了。在上个世纪五六十年代,感知器就出现了:
感知器的思想,就是对所有特征与权重做点积(内积),然后根据与阈值做大小比较,将样本分为两类。稍微了解一点神经网络的同学,对一下这幅图一定不陌生:

没错,这幅图描述的就是一个感知器。
我考研考的是控制原理,如果学过控制原理或者学过信号系统的同学,就知道感知器相当于那两门课中的阶跃函数:
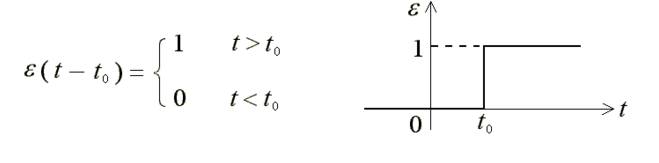
这两者的本质都是一致的,即通过划定一个阈值,然后比较样本与阈值的大小来分类。
这个模型简单直观,实现起来也比较容易(要不怎么说是最简单的现行分类器呢)。但是问题在于,这个模型不够光滑。第一,假设
啰啰嗦嗦写了这么多了,终于轮到logistic函数出场了。对比前面的感知器或者阶跃函数,他有什么优点呢?
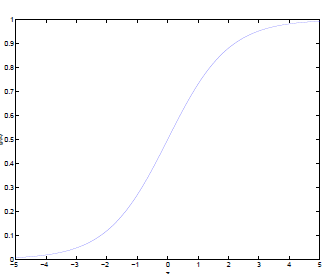
通过logistic函数的图像,我们很容易总结出他的以下优点:
1.他的输入范围是
2.他是一个单调上升的函数,具有良好的连续性,不存在不连续点。
写到这里,小伙伴们应该都明白为什么要使用logistic函数了吧。
敬请期待logistic系列后续文章。