使用scrapy爬取妹子图
欢迎转载,转载请注明出处http://blog.csdn.net/aaronjny
前言
博主大三了,该找工作实习咯。想搞数据采集方面,应聘爬虫工程师,看到很多招聘都要求会使用scrapy,会分布式采集,所以打算先学习学习scrapy,写两个小项目练练手,熟悉一下。看到很多人都在爬妹子图,那我就也爬妹子图得了。百度搜索一下妹子图,得到两个域名meizitu.com和mmjpg.com,我就把两个站都爬了。废话不多说,下面上干货(scrapy新手入门,大佬勿喷,有错求指点)。
爬取meizitu.com的代码,是接触scrapy当天写的,mmjpg.com部分则是第二天写的,所以有些小白的地方是肯定的,还请见谅(我以前使用beautifulsoup和requests写过不少爬虫代码,有一些爬虫底子,所以拿到scrapy,熟悉了一下就开始写了)。
代码编写前
在编写项目之前,先分析网站,想出爬取方案。我先爬取的是meizitu.com,从这个开始说。
打开浏览器,访问站点http://www.meizitu.com/,可以看到页面里是一个个的图集,如下:
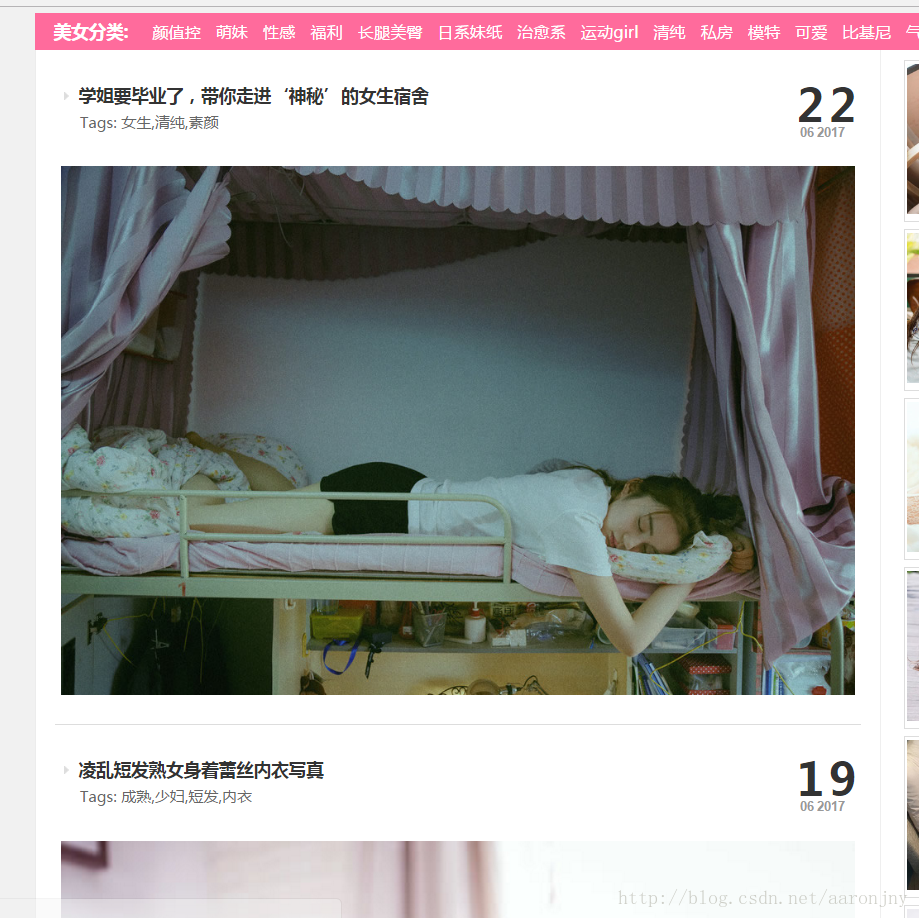
右键点击美女分类位置,选择检查(我使用的是谷歌浏览器),查看源码信息:
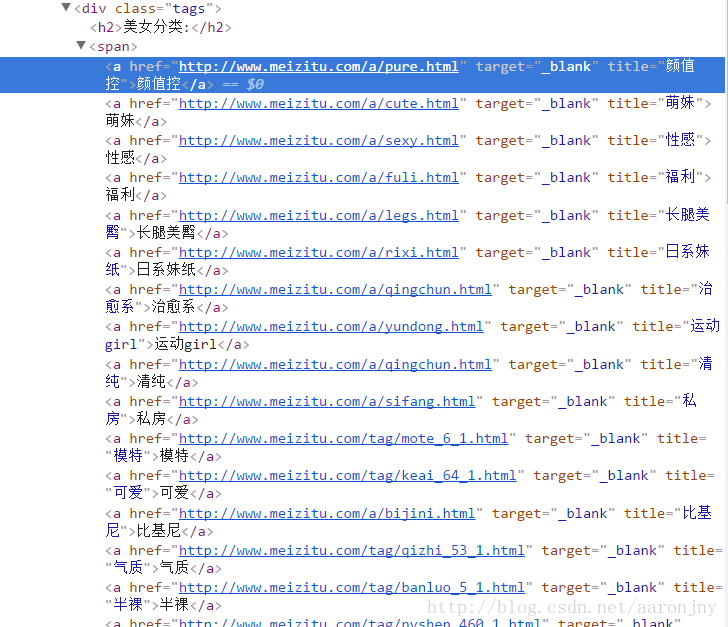
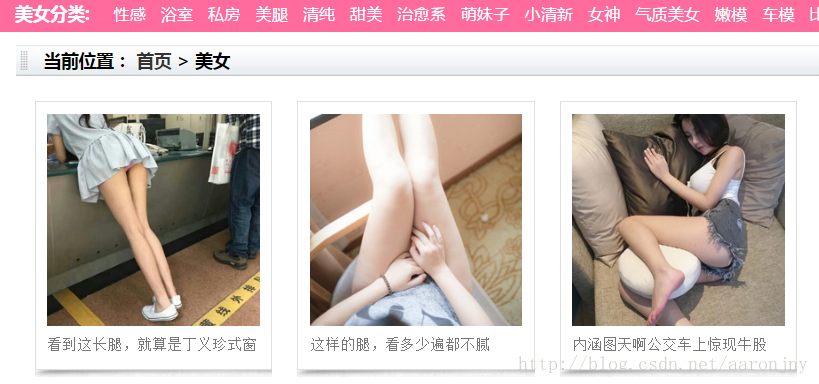
可以发现,分类的链接大多都是以http://www.meizitu.com/a/开头,于是,我猜测http://www.meizitu.com/a/是一个列表地址,我将地址复制到浏览器中访问,得到的果然是个列表页面,列出了一个个图集(PS:猜猜又无妨,分析url规律很多时候都是靠直觉的,大胆去猜,如果不是,我们还可以从首页开始爬嘛,没多大区别):
将网页滚动到最下方,可以看到翻页按钮:

而点击翻页按钮之后,页面模式与http://www.meizitu.com/a/类似,只是url不同,如第五页:http://www.meizitu.com/a/list_1_5.html。
多点开几页就能发现,列表页面地址的构成方式是:
- 第1页
http://www.meizitu.com/a/ - 第n页
http://www.meizitu.com/a/list_1_n.html
查看列表页面的源码:

观察图集的链接,比如http://www.meizitu.com/a/5529.html、http://www.meizitu.com/a/5527.html,可以看出,图集地址的构成方式是:
地址:
http://www.meizitu.com/a/{若干数字}.html
匹配正则式:http://www.meizitu.com/a/\d+.html
选择一个图片集点击进去,能看到属于这个图片集的所有图片:

查看网页源码,可以看到这个图集里所有图片的链接:

观察图片链接,可以发现,一个图集里图片地址(img/@src)的构成方式为:
地址:
http://mm.howkuai.com/wp-content/uploads/2017a/05/11/01.jpg
地址格式:
http://mm.howkuai.com/wp-content/uploads/20{数字}a/{数字}/{数字}/{数字}.jpg
匹配正则式:
http://mm.howkuai.com/wp-content/uploads/20\d{2}a/\d{2}/\d{2}/\d+.jpg
并且,在图集页面,也是存在指向其他图集的链接的,格式依旧满足
http://www.meizitu.com/a/\d+.html
至此,我们可以整理出来一个抓取思路:
[1] 将所有的列表页面地址放在一个列表里,假设为links。
[2] 对于每一个links中的列表页面,查找其中的图集地址,加入到一个列表中,假设为articleLinks。
[3] 对于每一个articleLinks中的图集页面,查找其中的图片地址,加入到一个列表中,假设为img_srcs。因为我们要将同一个图集下的图片放在同一个文件夹中,所以要记录每个图片地址来自于哪个图集。
[4] 对于每一个img_srcs中的图片,进行下载,并写入到对应的文件夹中。
这样,就完成了对全站图片的爬取。下面,开始编码~
爬虫环境
爬虫环境为python2和scrapy,如果没安装请先安装。安装的方式网上有许多,百度一下就可以了,这里就不赘述了。
使用的开发工具为pycharm。
创建scrapy项目
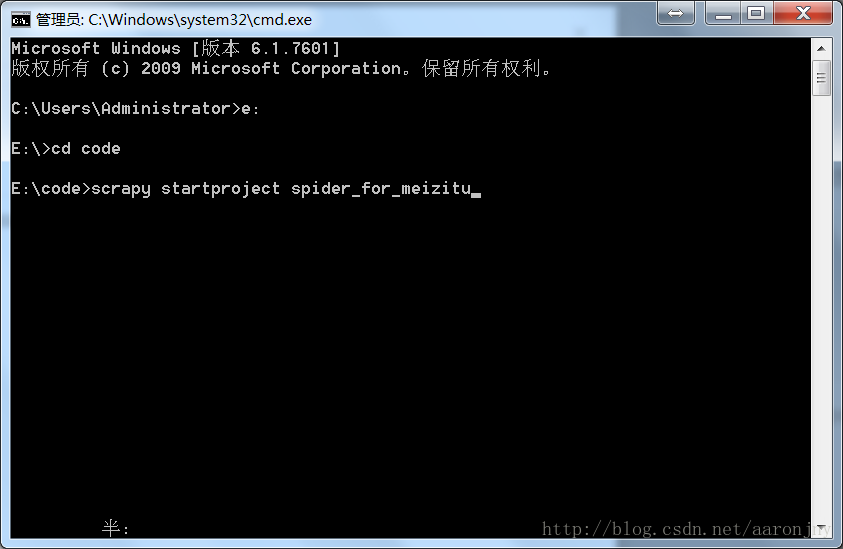
打开命令行,切换到想存放项目的目录,这里,我把项目放在放在
E:\code。windows:
e:
cd code
linux(假设存放位置为home/workspace/python):
cd ~/workspace/python输入
scrapy startproject spider_for_meizitu,并回车,其中spider_for_meizitu是项目名。
3. 使用pycharm打开刚刚创建的项目。
(PS:我的项目是已经写完的了,所以里面有我创建的main.py和image文件夹,刚创建的项目里面是没有的)
4. 在项目里新建一个image文件夹,用来存放图片。
编写Spider
1.在spiders目录下,创建文件MeizituSpider.py。
2.在文件里创建我们的spider类,这个类要继承scrapy.spiders.Spider。并设置相关属性。
#coding=utf-8
import scrapy
from scrapy.http import Request,HtmlResponse
import os
class MeizituSpider(scrapy.spiders.Spider):
name='meizitu'#爬虫名
allowed_domians=["meizitu.com"]#允许域名列表
start_urls=['http://www.meizitu.com/a/',]#起始链接列表
for i in range(2,91):
start_urls.append('http://www.meizitu.com/a/list_1_'+str(i)+'.html')3.在浏览器中观察网站的请求消息头,并在代码中设置。
正常情况下,网站服务器对爬虫都是不欢迎的,所以我们要将自己伪装成浏览器。最常用的一种伪装方法就是设置请求消息头,通过User-Agent伪装身份。
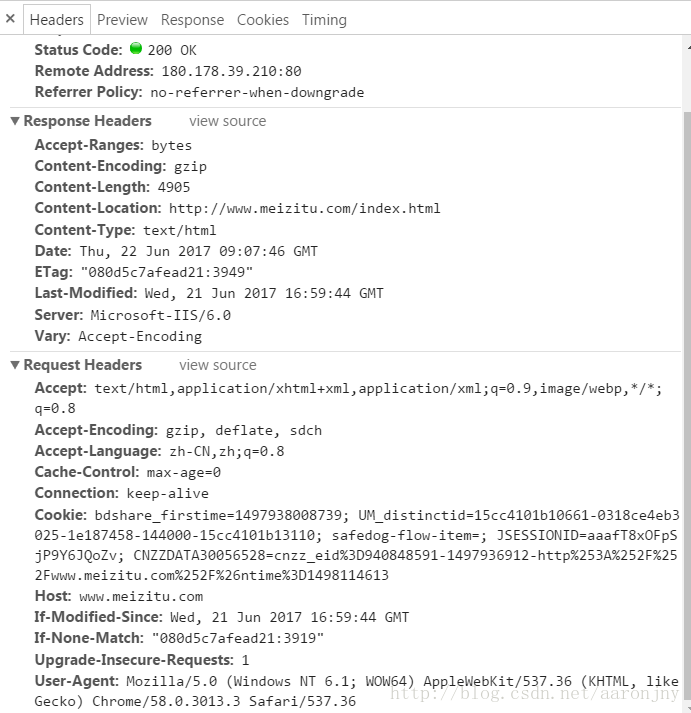
在MeizituSpider添加代码如下:
#请求头
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Host':'www.meizitu.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3013.3 Safari/537.36'
}4.重写make_requests_from_url方法,来指定headers
(PS:怎么用settings来设置请求头,后面爬取另外一个站的时候会说明。)
#重写方法,设置请求头(其实有更简单的方法,在settings里设置default-headers就行了)
def make_requests_from_url(self,url):
return Request(url, headers=self.headers,dont_filter=True)5.准备工作结束了,开始解析工作。当scrapy项目运行时,scrapy会自动从start_urls中取出url进行请求,并交由parse函数来解析。所以我们接下来要重写类的parse方法。
(PS:不知道为什么,csdn的markdown对这部分代码解析的时候,格式缩进显示有点问题,但是我复制下来,粘贴进ide里,格式是正确的,应该不影响。)
#解析start_urls的响应
def parse(self,response):
#获取图片集链接
links=response.xpath('//a[re:test(@href,"http://www.meizitu.com/a/\d+.html")]/@href').extract()
print links
#对所有的图片集进行请求
for url in links:
yield Request(url,headers=self.headers,callback=self.parseImageArticle)
通过parse函数,我们能够从列表页面中获得该页面上所有的图片集地址,scrapy会对每个图片集进行请求,并交给我们设置的回调函数(callback=self.parseImageArticle)parseImageArticle处理。
6.编写parseImageArticle方法,从图片集页面中提取属于该图片集的所有图片的地址,以及能够到达的其他图片集的地址。
#解析单个图片集的响应
def parseImageArticle(self,response):
#获取图片链接列表
src_links=response.xpath('//img[re:test(@src,"http://mm.howkuai.com/wp-content/uploads/20\d{2}a/\d{2}/\d{2}/\d+.jpg")]/@src').extract()
#获取图片集名称,用以创建文件夹
base_path=os.path.join("image",response.xpath('//div[contains(@class,"metaRight")]/h2/a/text()').extract()[0])
#下载图片请求头
header={
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3013.3 Safari/537.36'
}
#文件夹不存在则创建
if not os.path.exists(base_path):
os.makedirs(base_path)
#下载图片
for i in range(len(src_links)):
#获取用以存储的文件名
file_path = os.path.join(base_path, str(i)+'.jpg')
#传递文件名,并使用imageDownload方法解析
yield Request(src_links[i],meta={'file_path':file_path},headers=header,callback=self.imageDownload)
#获取当前页面的其他图片集链接
links = response.xpath('//a[re:test(@href,"http://www.meizitu.com/a/\d+.html")]/@href').extract()
print links
#请求其他图片集,使用此方法解析
for url in links:
yield Request(url, headers=self.headers, callback=self.parseImageArticle)从此页面上提取到的其它图片集的链接,由scrapy请求后,仍将响应结果交给回调函数(callback=self.parseImageArticle)parseImageArticle来解析。而图片链接则在scrapy请求后交由下载函数处理(callback=self.imageDownload)。
7.编写下载函数imageDownload。当scrapy对图片链接进行请求后,我们要对其进行解析。简单来说,就是把下载下来的流以适当的路径写入到本地磁盘中。
#下载图片
def imageDownload(self,response):
file_path=response.meta['file_path']
with open(file_path,'wb') as f:
f.write(response.body)这样,spider部分就编写完成了,这个爬虫的大部分都在这里。下面是MeizituSpider.py完整代码:
#coding=utf-8
import scrapy
from scrapy.http import Request,HtmlResponse
import os
class MeizituSpider(scrapy.spiders.Spider):
name='meizitu'#爬虫名
allowed_domians=["meizitu.com"]#允许域名列表
start_urls=['http://www.meizitu.com/a/',]#起始链接列表
for i in range(2,91):
start_urls.append('http://www.meizitu.com/a/list_1_'+str(i)+'.html')
#请求头
headers={
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'zh-CN,zh;q=0.8',
'Connection':'keep-alive',
'Host':'www.meizitu.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3013.3 Safari/537.36'
}
#重写方法,设置请求头(其实有更简单的方法,在settings里设置default-headers就行了)
def make_requests_from_url(self,url):
return Request(url, headers=self.headers,dont_filter=True)
#下载图片
def imageDownload(self,response):
file_path=response.meta['file_path']
with open(file_path,'wb') as f:
f.write(response.body)
#解析单个图片集的响应
def parseImageArticle(self,response):
#获取图片链接列表
src_links=response.xpath('//img[re:test(@src,"http://mm.howkuai.com/wp-content/uploads/20\d{2}a/\d{2}/\d{2}/\d+.jpg")]/@src').extract()
#获取图片集名称,用以创建文件夹
base_path=os.path.join("image",response.xpath('//div[contains(@class,"metaRight")]/h2/a/text()').extract()[0])
#下载图片请求头
header={
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3013.3 Safari/537.36'
}
#文件夹不存在则创建
if not os.path.exists(base_path):
os.makedirs(base_path)
#下载图片
for i in range(len(src_links)):
#获取用以存储的文件名
file_path = os.path.join(base_path, str(i)+'.jpg')
#传递文件名,并使用imageDownload方法解析
yield Request(src_links[i],meta={'file_path':file_path},headers=header,callback=self.imageDownload)
#获取当前页面的其他图片集链接
links = response.xpath('//a[re:test(@href,"http://www.meizitu.com/a/\d+.html")]/@href').extract()
print links
#请求其他图片集,使用此方法解析
for url in links:
yield Request(url, headers=self.headers, callback=self.parseImageArticle)
#解析start_urls的响应
def parse(self,response):
#获取图片集连接
links=response.xpath('//a[re:test(@href,"http://www.meizitu.com/a/\d+.html")]/@href').extract()
print links
#对所有的图片集进行请求
for url in links:
yield Request(url,headers=self.headers,callback=self.parseImageArticle)
settings.py的设置
刚接触scrapy,settings.py里面的配置,有些我也搞不清楚,这里就说我使用的配置。如果有哪里配置的不合适的地方,请斧正。
#这部分会自动生成
BOT_NAME = 'spider_for_meizitu'
SPIDER_MODULES = ['spider_for_meizitu.spiders']
NEWSPIDER_MODULE = 'spider_for_meizitu.spiders'
#设置下载延迟0.25ms
DOWNLOAD_DELAY = 0.25
#不遵守robot.txt
#ROBOTSTXT_OBEY = True
#不启用cookies
COOKIES_ENABLED = False创建main.py以启动爬虫
至此,爬虫的编写工作已经基本完成了,现在已经可以通过命令行运行爬虫了,只需要打开命令行,输入scrapy crawl meizitu并回车即可。
但是,在命令行里运行爬虫,不利于我们调试,如果想直接通过pycharm运行scrapy爬虫的话,需要新建一个main.py,并在里面写入如下代码:
# coding=utf-8
from scrapy import cmdline
cmdline.execute("scrapy crawl meizitu".split())可以看出,其实这段代码的真实功能跟上面是一样的,就是执行scrapy crawl meizitu这个命令。
运行main.py,就可以启动爬虫,然后,享受需要的数据渐渐写入硬盘的过程吧~
爬虫源码(GitHub)
爬虫源码,可以参考我的GitHub,戳这里
如果觉得代码风格不好的话,请原谅我。。。
结束语
终于写完了,好累啊(感觉写博客比写代码还累。。。),今天先写这么多,爬取mmjpg.com部分改天再写。因为是初学scrapy,很多地方写的都不规范。比如说下载部分,应该编写item类,在spider中返回item并交给管道下载,等等。在爬取mmjpg.com的代码中,我尽量避免了,但仍会存在许多不足,比如没有设置随机User-Agent和代理IP池等,还要多多学习。
以上,记一次scrapy实战。如有疑问的地方,可以给我留言,我看到后会回复的。如果我有什么做的不好的地方,也请路过的大牛指点指点。
更多:爬取妹子图(mmjpg.com)
代码已完成,博客未撰写。。。待更新。