兴趣是最好的老师,学爬虫的兴趣之一就是如何抓取妹子图。下面是我对妹子图抓取的详细过程,记录下来。
本篇教程采用的是Python3编写,运行的时候需要使用Python3的开发环境。
需要的库
- Requests 是urllib的升级版本打包了全部功能并简化了使用方法(点我查看官方文档)
- beautifulsoup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.(点我查看官方文档)
- LXML 一个HTML解析包 用于辅助beautifulsoup解析网页
第一步:导入Python库
import requests ##导入requests
form bs4 import BeautifulSoup ##导入bs4中的BeautifulSoup
import os 利用python爬虫的一般步骤:
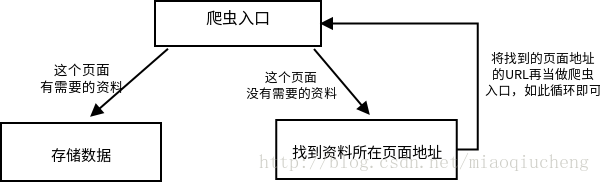
爬虫入口:顾名思义我需要程序从什么地方开始获取网页
存储数据:如果获取的网页有你需要的内容则取出数据保存
找到资料所在的地址:如果你你获取到的网页没有你需要的数据、但是有前往该数据页面的地址URL、则获取这个地址URL,再获取该URL的页面内容(也就等于当作爬虫入口了)
- 下面是我们的第一段代码:用作获取http://www.mzitu.com/all这个页面。
import requests
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用Requests中的get方法来获取all_url(就是:http://www.mzitu.com/all 这个地址)的内容,headers为上面设置的请求头,务必参考Requests官方文档解释
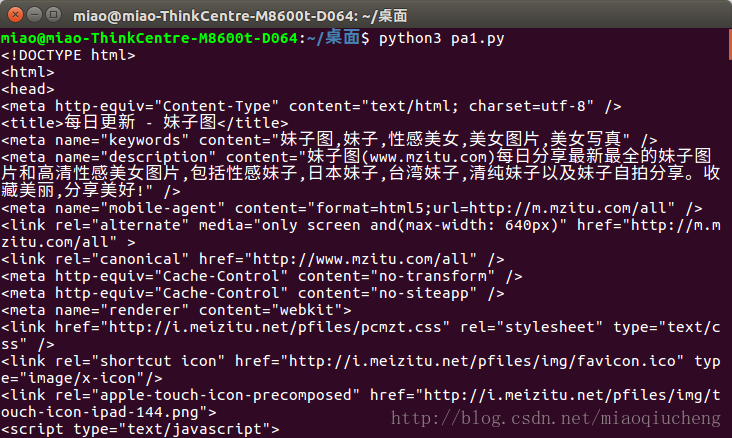
print(start_html.text) ##打印出start_html(content是二进制的数据,一般用于下载图片、视频、音频等多媒体内容才使用content,对于打印网页内容使用text)运行之后会在打印出下图所示的内容。

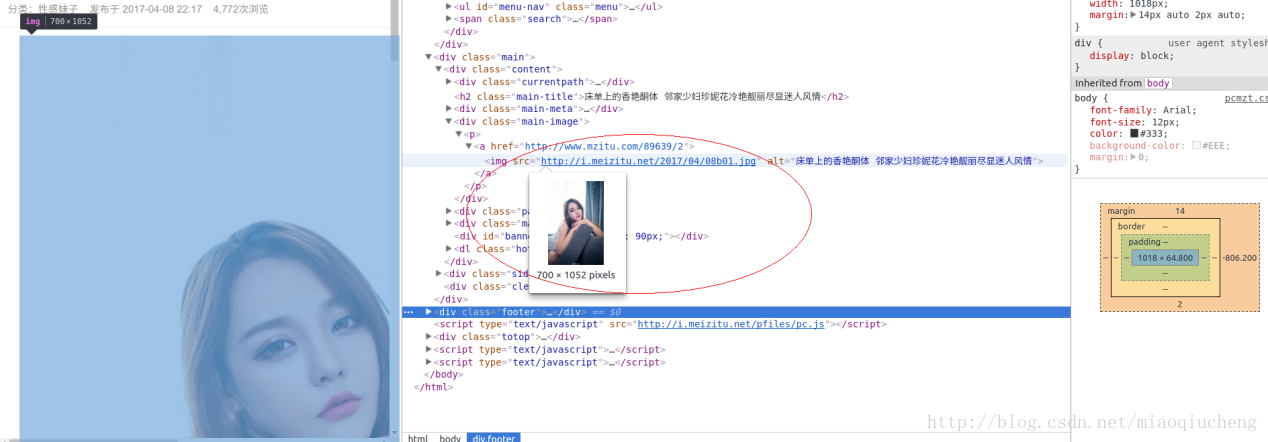
随便打开一个标签,当我们把鼠标放在红圈内的网址区域时,会弹出一副小小的图片,如下图所示。这就标明图片的内容就在这个标签内。
实现逻辑就是:先找到页面中的全部 <li>标签、然后提取出中间<a>标签的href属性值与<a>标签的类容,前者我们用来继续请求html看看会不会有我们需要的图片下载地址,后者我们存储的时候给文件夹命名使用。
下面我们使用BeautifulSoup中的find_all来获取所有pi标签内的内容:
import requests
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} ##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用Requests中的get方法来获取all_url(就是:http://www.mzitu.com/all 这个地址)的内容,headers为上面设置的请求头,务必参考Requests官方文档解释
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器)
li_list = Soup.find_all('li') ##使用BeautifulSoup解析网页过后就可以用来寻找li标签。(find_all是查找制定网页内的所有标签的意思,find_all返回的是一个列表。)
for li in li_list:
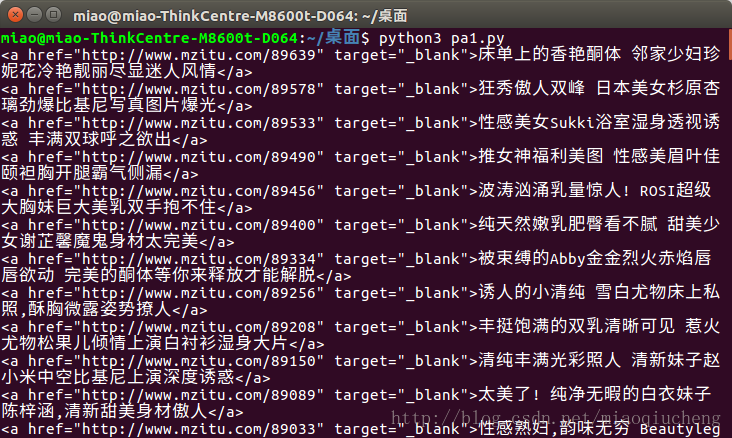
print(li)运行之后的结果如下所示:
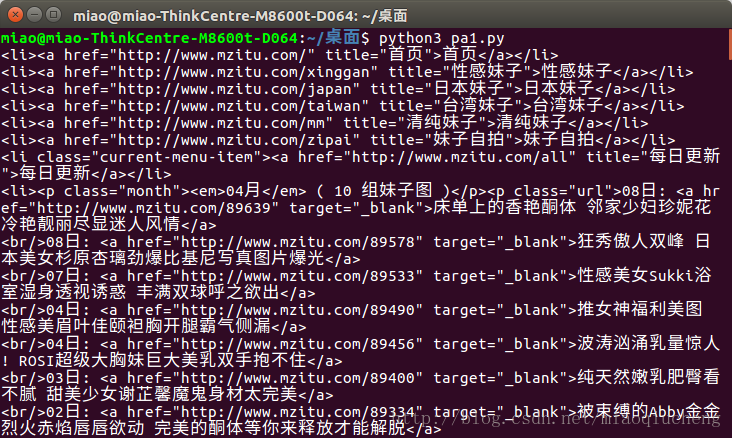
但是,注意上图中的内容,最上面的li标签里面有好多无关的内容,如:首页,性感妹子等。
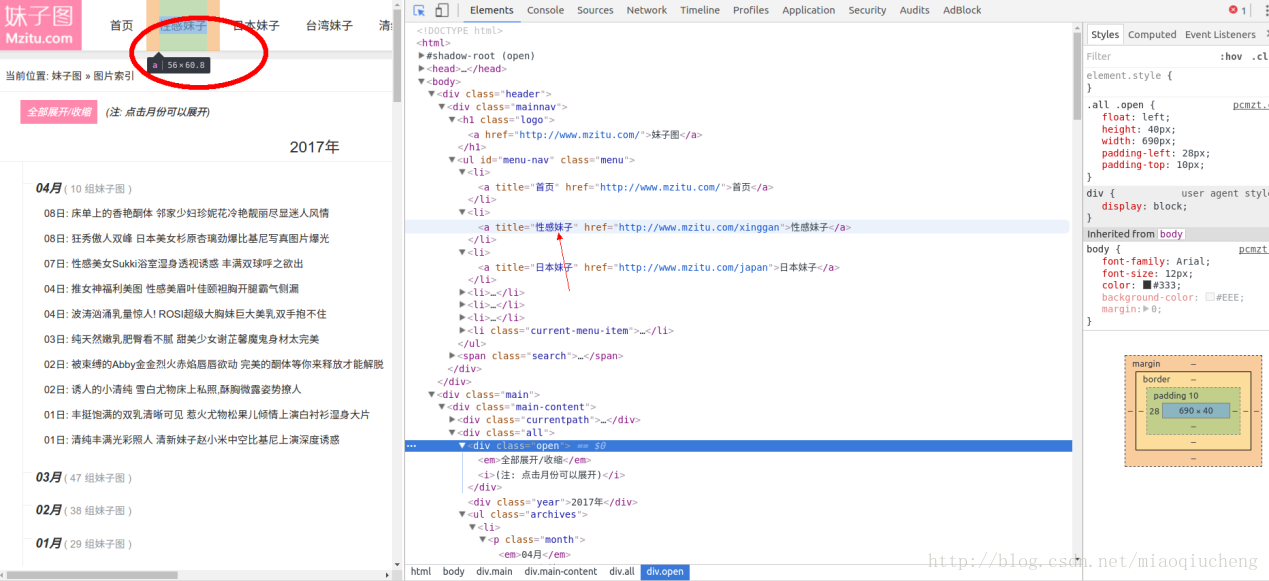
我们检查发现,上图中箭头所指的内容中也有li标签。

经过仔细的检查之后发现,我们要找的内容全在红色圈圈里,而这些li标签全都在<div class="all">这个标签内,那么我们不就可以先找到<div class="all">这个标签,然后再找到li标签,这样的话不就可以只保留我们需要的内容了吗!修改代码如下所示:
import requests
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"} ##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用Requests中的get方法来获取all_url(就是:http://www.mzitu.com/all 这个地址)的内容,headers为上面设置的请求头,务必参考Requests官方文档解释
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器)
all_a = Soup.find('div', class_='all').find_all('a')
for a in all_a:
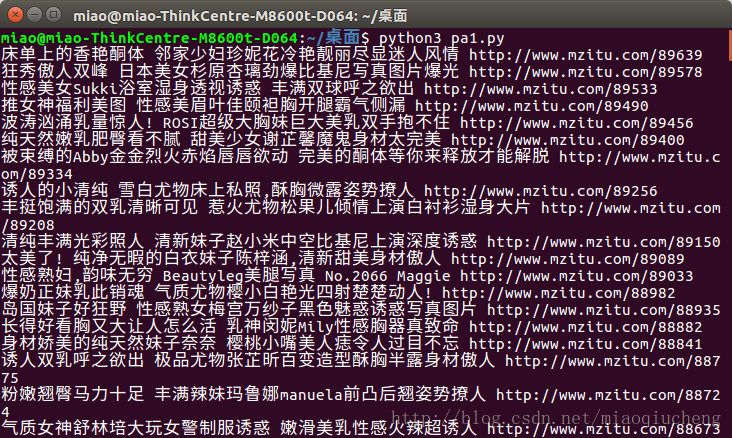
print(a)下图就是我们修改之后的运行结果,发现首页,性感妹子……都不见了,剩下的就是我们需要的内容。
好啦!现在我们该来提取我们想要的内容了!又该我们BeautifulSoup大展身手了。我们需要提取出<a>标签的href属性和文本。下面是对代码的修改,只是添加了两行代码。
import requests
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用Requests中的get方法来获取all_url(就是:http://www.mzitu.com/all 这个地址)的内容,headers为上面设置的请求头,务必参考Requests官方文档解释
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器)
all_a = Soup.find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text() ##取出a标签文本
href = a['href'] ##取出a标签的href属性
print(title, href)下图就是我们修改代码之后打印出的内容。
上述过程分析完毕,接下来就是要正式的抓取图片了。首先,先查看一下图片页面有什么东西。你会发现一个页面只有一张图片啊!想要下载一套啊!你点一下面的 1 、2、3、4········ 你会发现地址栏里面的URL在变化啊!这就是我们的入手的地方了!
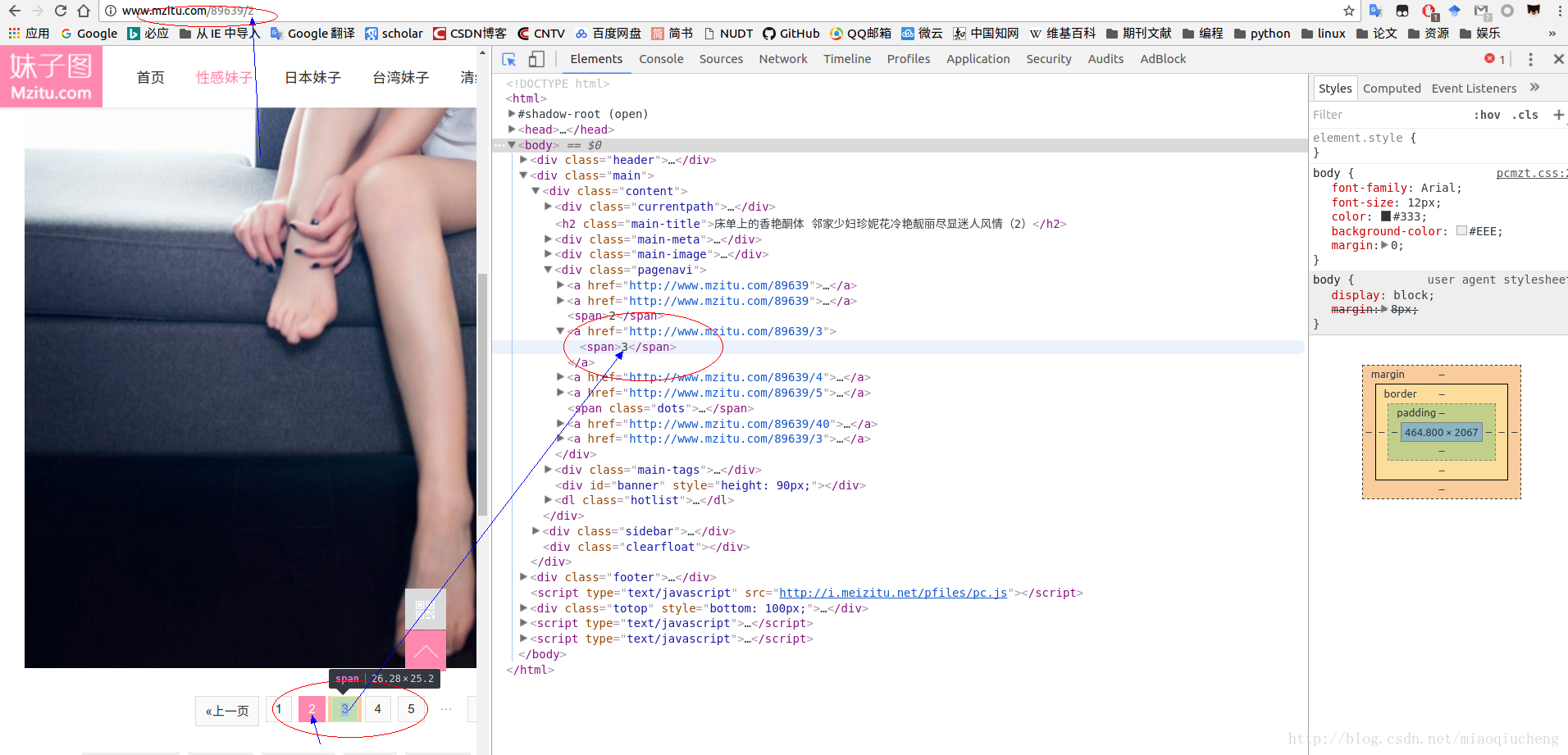
我们发现随着我们上下翻页,URL地址也发生了变化,在网页源代码中,我们发现页码是在<span>标签中。我们只需要获取最后一个页面的页码, 从 1 开始遍历,和我们上面获取的URL拼接在一起就是每张图片的页面地址啦!
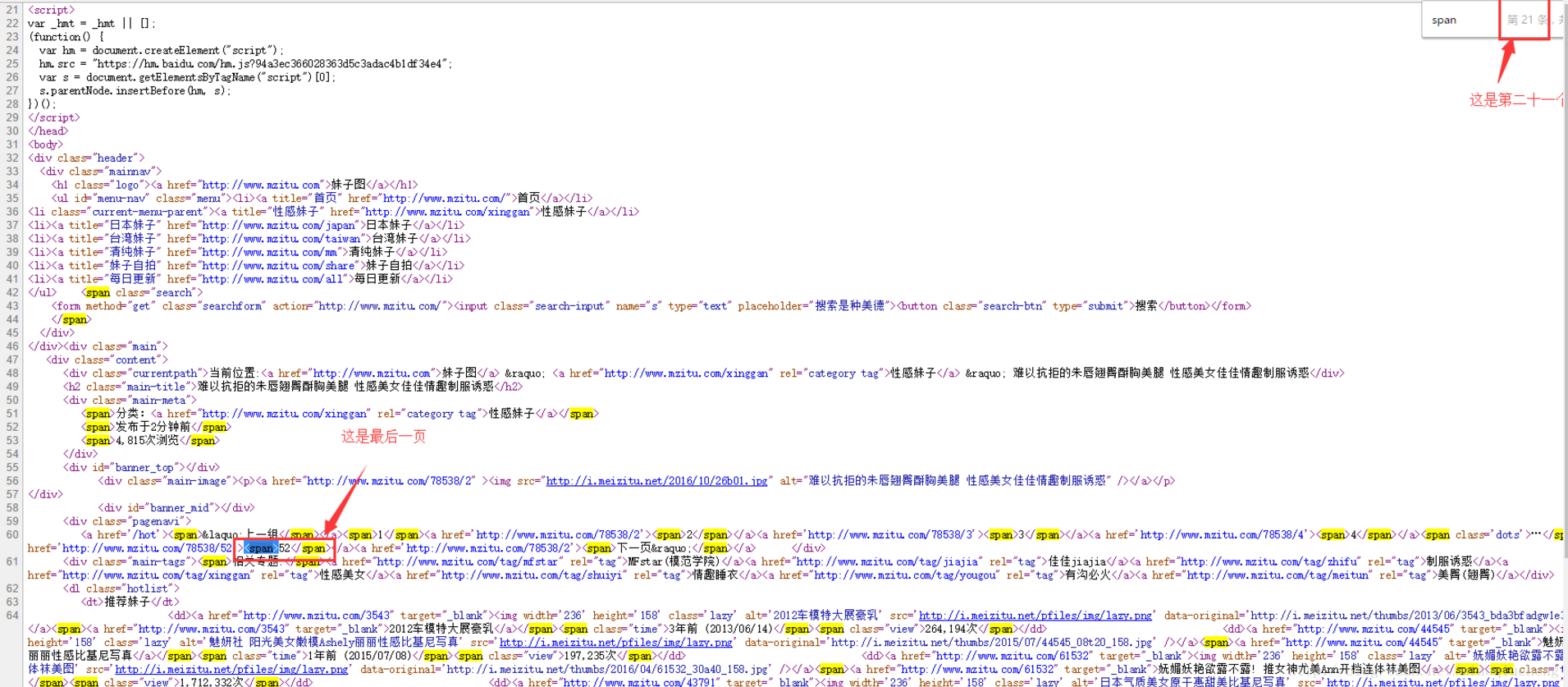
可以发现最后一个页面的<span>标签是第二十一个标签,因为在html中标签是成对的,所以我需要查找的是第十一个<span>标签(BeautifulSoup是以开始的标签定位,而不是结尾的。开始的标签是这样<>;结束的标签是这样</>。
下面我们对代码进行修改:
import requests
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用Requests中的get方法来获取all_url(就是:http://www.mzitu.com/all 这个地址)的内容,headers为上面设置的请求头,务必参考Requests官方文档解释
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器)
all_a = Soup.find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text() ##取出a标签文本
href = a['href'] ##取出a标签的href属性
html = requests.get(href, headers=headers)
html_Soup = BeautifulSoup(html.text, 'lxml')
max_span = html_Soup.find('div', class_='pagenavi').find_all('span')[-2].get_text() ##查找所有的<span>标签,获取第十个<span>标签中的文本,也就是最后一个页面。
for page in range(1, int(max_span)+1):
page_url = href + '/' + str(page)
print(page_url) ##这个page_url就是每个图片的页面地址,但不是实际地址!下图就是运行结果:
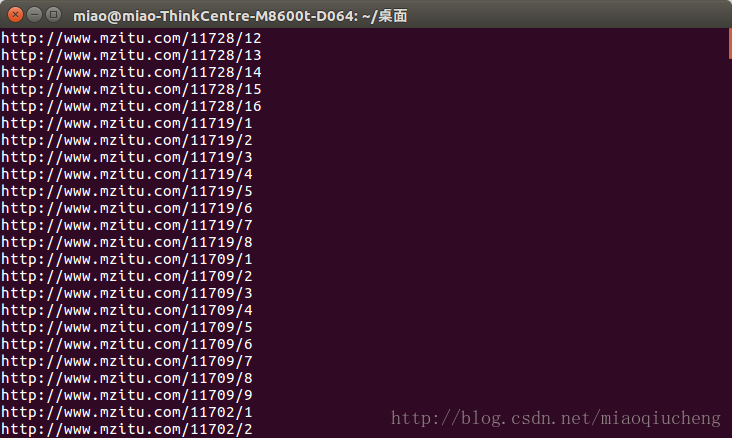
可以发现,运行后的结果正是我们想要的。下面开始保存了哦!哈哈!妹子马上就可以到你碗里去了!
首先我们要给每套图建一个文件夹,然后将下载的图片以URL的 xxxxx.jpg 中的xxxxx命名保存在这个文件夹里面。直接上代码了!
import requests
from bs4 import BeautifulSoup
import os
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}##浏览器请求头(大部分网站没有这个请求头会报错、请务必加上哦)
all_url = 'http://www.mzitu.com/all' ##开始的URL地址
start_html = requests.get(all_url, headers=headers) ##使用Requests中的get方法来获取all_url(就是:http://www.mzitu.com/all 这个地址)的内容,headers为上面设置的请求头,务必参考Requests官方文档解释
Soup = BeautifulSoup(start_html.text, 'lxml') ##使用BeautifulSoup来解析我们获取到的网页(‘lxml’是指定的解析器)
all_a = Soup.find('div', class_='all').find_all('a')
for a in all_a:
title = a.get_text() ##取出a标签文本
path = str(title).strip() ##去掉空格
os.makedirs(os.path.join("/home/miao/桌面/meizit", path)) ##创建一个存放套图的文件夹,我的存储目录是放在了/home/miao/桌面/meizit中.Windows系统类似,可以放在D:\meizit中。
os.chdir("/home/miao/桌面/meizit/"+path) ##切换到上面创建的文件夹
href = a['href'] ##取出a标签的href属性
html = requests.get(href, headers=headers)
html_Soup = BeautifulSoup(html.text, 'lxml')
max_span = html_Soup.find('div', class_='pagenavi').find_all('span')[-2].get_text() ##查找所有的<span>标签,获取第十个<span>标签中的文本,也就是最后一个页面。
for page in range(1, int(max_span)+1):
page_url = href + '/' + str(page)
img_html = requests.get(page_url, headers=headers)
img_Soup = BeautifulSoup(img_html.text, 'lxml')
img_url = img_Soup.find('div', class_='main-image').find('img')['src']
name = img_url[-9:-4] ##取URL 倒数第四至第九位,做图片名字
img = requests.get(img_url, headers = headers)
f = open(name+'.jpg', 'ab') ##写入多媒体文件必须要b这个参数!必须要
f.write(img.content) ##多媒体文件要用content。
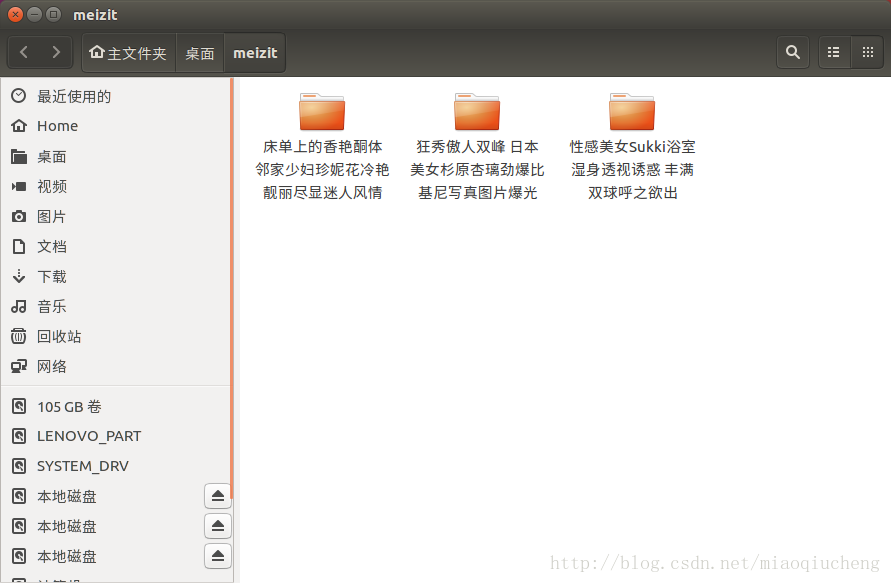
f.close()下图就是运行之后的结果,我们可以看到图片已经爬取下来了。
--END