去年10月份写过《Node.js 2小时爬取驴妈妈8W+条旅游数据》。之前做的是使用request 做网路请求和 cheerio做DOM解析。
后来在网上看见了crawler,昨天就把crawler把玩了了一把。感觉使用起来还可以,他的作用和上面的两个包的作用是一样的。

这次我爬取的是妹子图。
在爬取之前,还是建议先看看crawler怎么使用。其实它的是有还是很简单的。这里不再赘述,请自行查阅文档。
再则就是好好看看妹子图这个网页地址的规律,是不是有防刷机制(同一个IP,短期内多次访问,自定义的概念)。这里我找到的规律是妹子图的首页:http://www.meizitu.com和http://www.meizitu.com/a/more_1.html打开的效果是一样的。而第2个链接地址,直接就可以显示当前访问的是第多少页。
实操步骤:
1.计算总页数
var c = new Crawler({
maxConnections : 10, // 最大链接数 10
retries: 5, // 失败重连5次
// This will be called for each crawled page
callback : function (error, res, done) { // 执行下面的回调,这个回调不会执行
if(error){
console.log(error);
}else{
var $ = res.$;
console.log($("title").text());
}
done();
}
});
c.queue([{
uri: 'http://www.meizitu.com/a/more_1.html',
jQuery: true,
callback: function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$; // 这就可以想使用jQuery一个解析DOM了
var total_pag = 0;
$('#wp_page_numbers li a').each(function(index,item){
if ($(item).text() == '末页') {
total_pag = $(item).attr('href');
var regexp = /[0-9]+/g;
total_pag = total_pag.match(regexp)[0]; // 总页数
}
})
}
done();
}
}]);这一步的操作是先看看这个有多少页,计算出总页数。
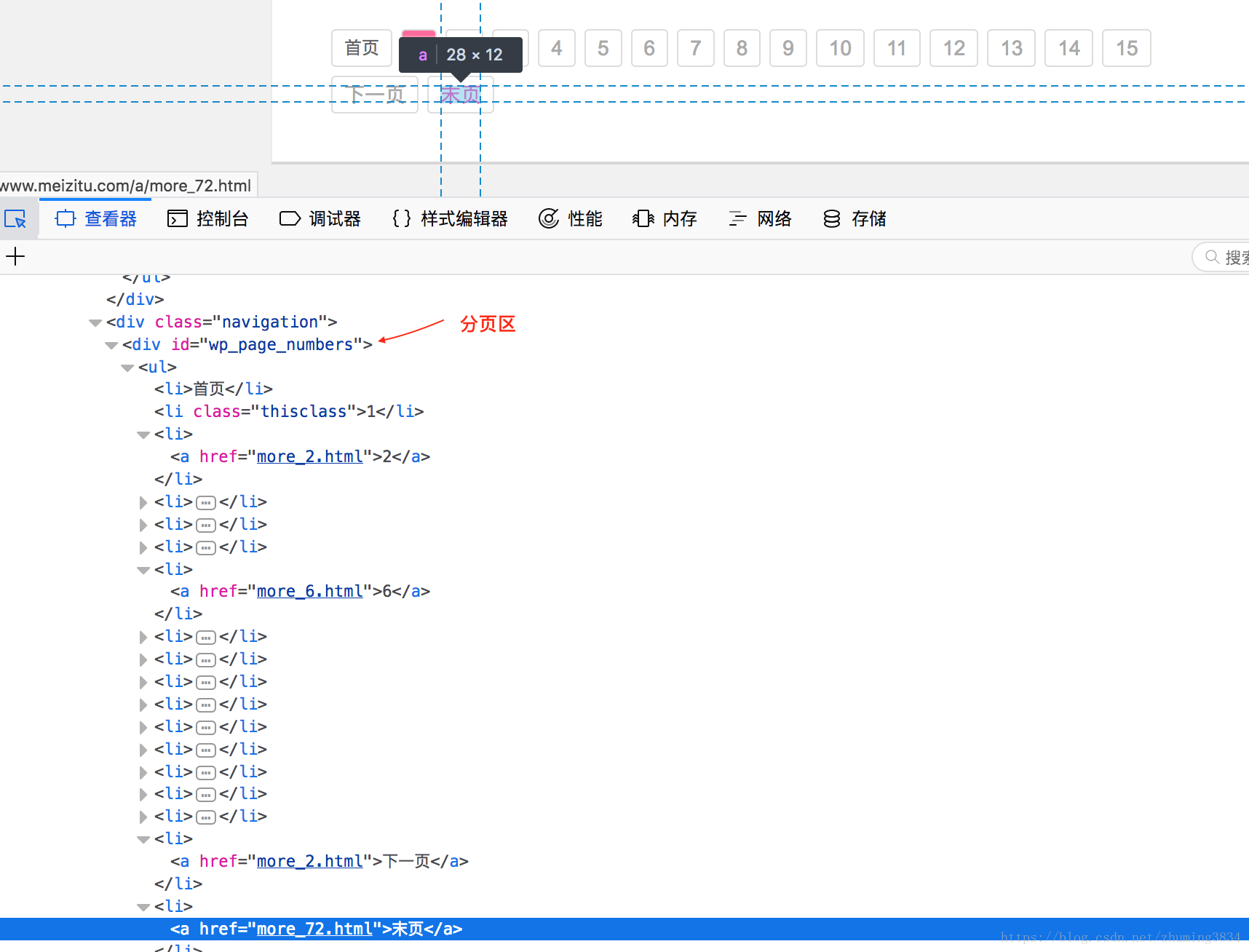
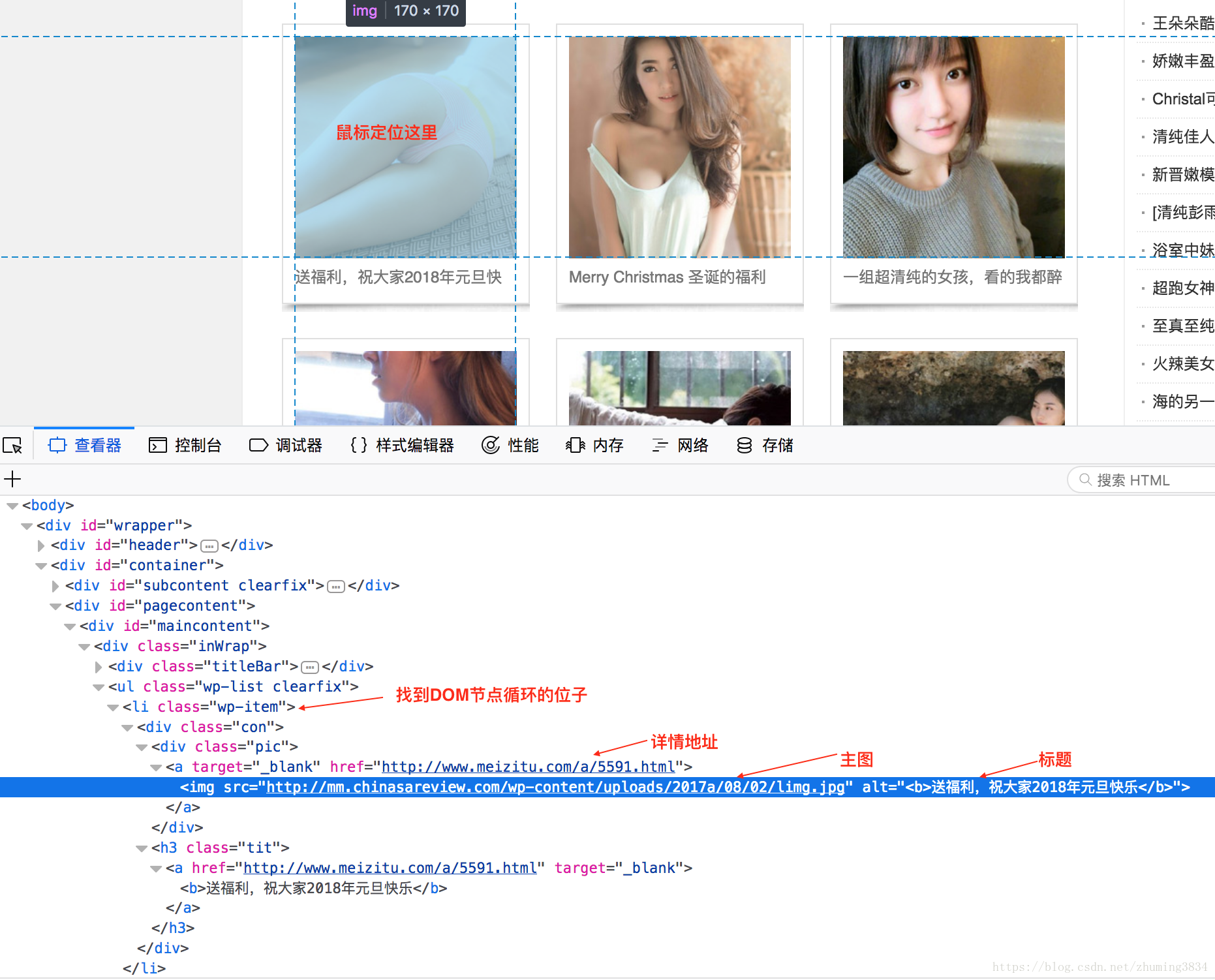
这里的每一页显示的是一个主题,每个主题点进去才是详情,我做的是先下载主题。
2.下载主题
function downloadContent(i,c){
var uri = 'http://www.meizitu.com/a/more_' + i + '.html';
c.queue([{
uri: uri,
jQuery: true,
callback: function (error, res, done) {
if(error){
console.log(error);
}else{
var $ = res.$;
var meiziSql = '';
$('.wp-item .pic a').each(function(index,item){
var href = $(item).attr('href'); // 获取路径uri
var regexp = /[0-9]+/g;
var artice_id = href.match(regexp)[0]; // 获取文章ID
var title = $(item).children('img').attr('alt');
title = title.replace(/<[^>]+>/g,""); // 去掉 <b></b> 标签
var src = $(item).children('img').attr('src');
var create_time = new Date().getTime();
if (href == 'http://www.meizitu.com/a/3900.html') {
title = title.replace(/'/g,''); // 这个的标题多了一个 单引号, mysql在插入的时候存在问题,所以这样处理了一下
}
var values = "'" + artice_id + "'" + ','
+ "'" + title + "'" + ','
+ "'" + href + "',"
+ "'" + src + "'" + ','
+ "'" + create_time + "'";
meiziSql = meiziSql + 'insert ignore into meizitu_all(artice_id,title,href,src,create_time) VALUES(' + values + ');';
})
pool.getConnection(function(err, connection) {
if(err){
console.log('数据库连接失败',i);
}
connection.query(meiziSql,function (err, results) {
connection.release();
if (err){
console.log(err,i);
}else{
console.log('插入成功',i);
}
})
})
}
done();
}
}]);
}
这样就可把把每页的每个主题下载下来了。
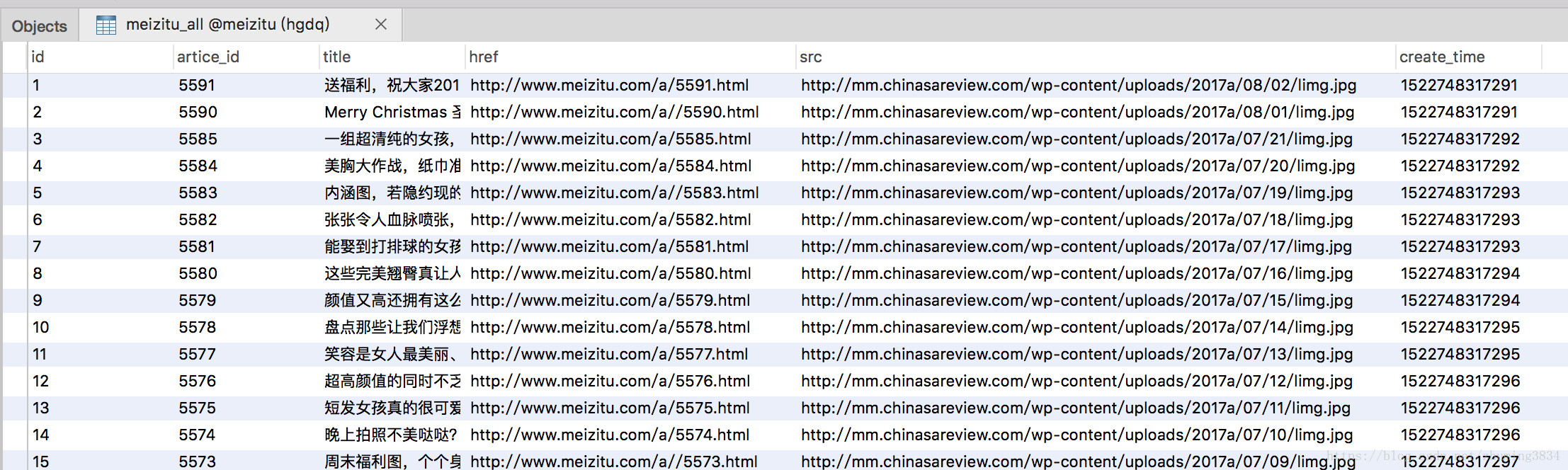
一共2806个,哈哈,足够看一年了,(如果你不会审美疲劳)。
看见了这里function downloadContent(i,c),不知道大家会不会有什么疑问?为什么还有两个参数,参数c好书,那么其中的i是做什么的呢?这里暂且不说他是做什么,下一篇大家就知道了。
这里只说crawler。通过代码大家也看见了,crawler既可以发起网络请求也可以将DOM转换成jQuery形式,以便解析。
这里所说了的爬虫,加上之前我做的,其实都发起网路请求,获取网页的DOM,然后解析DOM节点。下一篇是提高爬取效率的async的使用。