根据现有的知识,写了一个下载妹子图(meizitu.com)Scrapy脚本,把全站两万多张照片下载到了本地。
网站的分析
网页的网址分析
打开网站,发现网页的网址都是以 http://www.meizitu.com/a/+某个数+.html组成,
例如:http://www.meizitu.com/a/5585.html
于是,我就想着在 start_urls 中就按照这三部分来组合。
name = 'meizi'
allowed_domains = ['www.meizitu.com']
baseURL = 'http://www.meizitu.com/a/'
offset = 4633
end = '.html'
start_urls = [baseURL+str(offset)+end]网页的页面分析
打开某一页网址,图片的链接在 id="picture"下的 img 标签下,
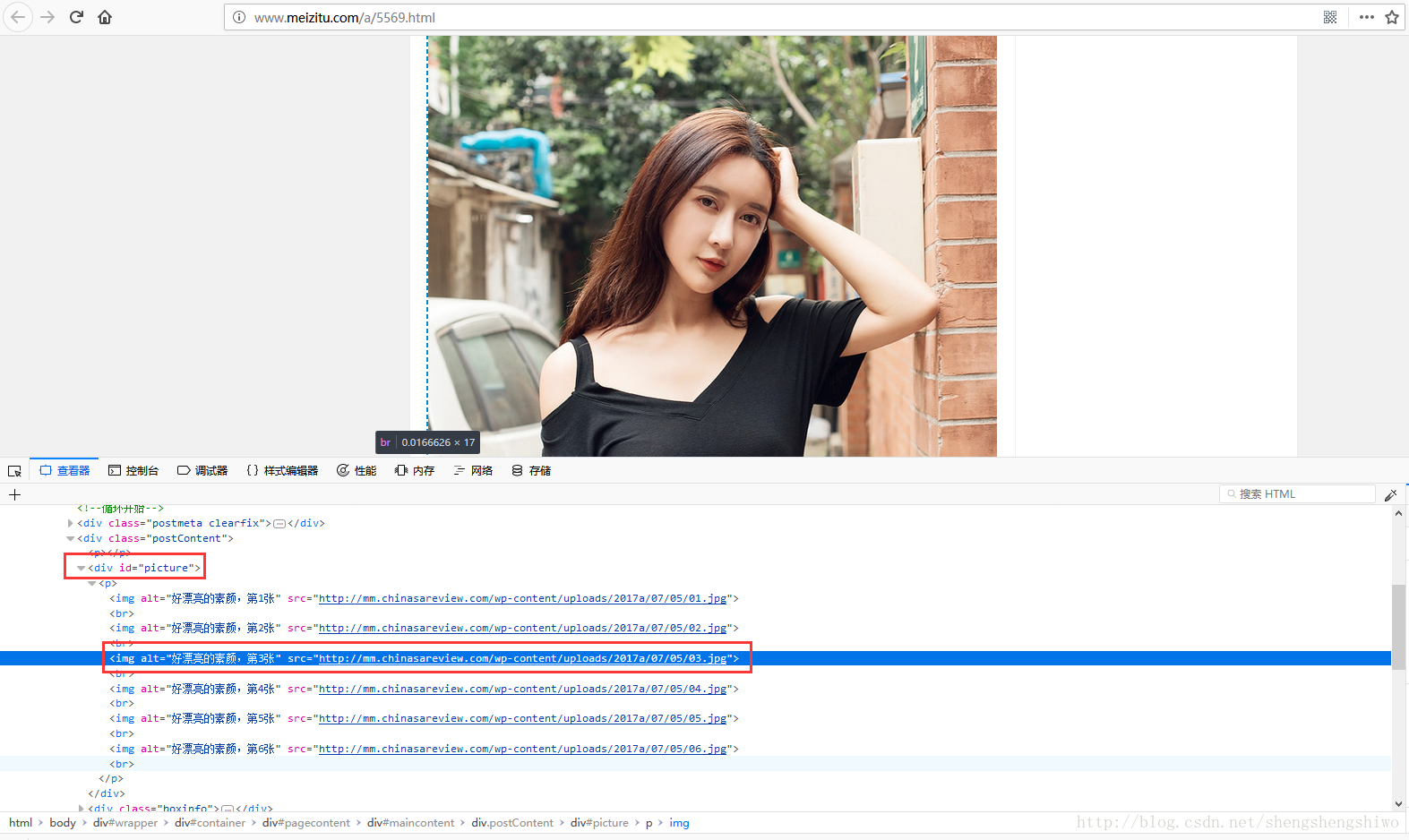
获取图片地址:
srcs = response.css("#picture img::attr(src)").extract()写一个循环,遍历网站所有网址:
for src in srcs :
item = MeizituItem()
item['picLink'] = src
print(src)
yield item
self.offset +=1写一个打印函数,便于监视程序运行情况:
print('addr'+str(self.offset))
if self.offset > 5586:
return
time.sleep(1)
url = self.baseURL + str(self.offset)+self.end
print ("url:"+url)
交给 Request 进行下载
yield scrapy.Request(url, callback=self.parse)Spider 函数全部代码
# -*- coding: utf-8 -*-
import scrapy
from meizitu.items import MeizituItem
import time
class MeiziSpider(scrapy.Spider):
name = 'meizi'
allowed_domains = ['www.meizitu.com']
baseURL = 'http://www.meizitu.com/a/'
offset = 4633
end = '.html'
start_urls = [baseURL+str(offset)+end]
def parse(self, response):
srcs = response.css("#picture img::attr(src)").extract()
for src in srcs :
item = MeizituItem()
item['picLink'] = src
print(src)
yield item
self.offset +=1
print('addr'+str(self.offset))
if self.offset > 5586: #stop at 5400,for 404
return
time.sleep(1)
url = self.baseURL + str(self.offset)+self.end
print ("url:"+url)
yield scrapy.Request(url, callback=self.parse)细心地同学可能看到了,offset = 4633 为什么不是从 1 开始? 这是因为可能是建站时间的原因,之前的网站里的图片都是在 class="postContent"下的 img 标签里的
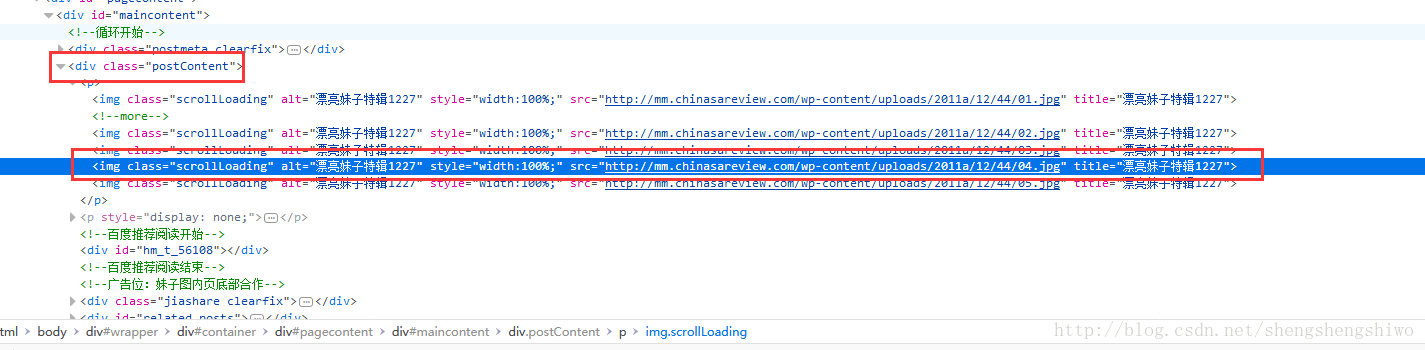
这部分 CSS 解析为:
srcs = response.css(".postContent img::attr(src)").extract()所以,想要爬取整个网站的图片,得分为两部分。爬完一半后,把 CSS 解析替换掉就可以了。
修改 Pipelines,下载图片
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class MeizituPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
pic_link = item['picLink']
print('pic_url'+pic_link)
yield scrapy.Request(pic_link)修改 items
import scrapy
class MeizituItem(scrapy.Item):
picLink = scrapy.Field()设置 settings
BOT_NAME = 'meizitu'
SPIDER_MODULES = ['meizitu.spiders']
NEWSPIDER_MODULE = 'meizitu.spiders'
IMAGES_STORE = "image"
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; …) Gecko/20100101 Firefox/58.0'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'meizitu.pipelines.MeizituPipeline': 300,
}写一个 main 函数,在 PyCharm 中执行
import sys
import os
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute(["scrapy", "crawl", "meizi"])通过实时看着程序运行,爬下来接近三万张照片,1.8G。挑了几张不漏的。。。。
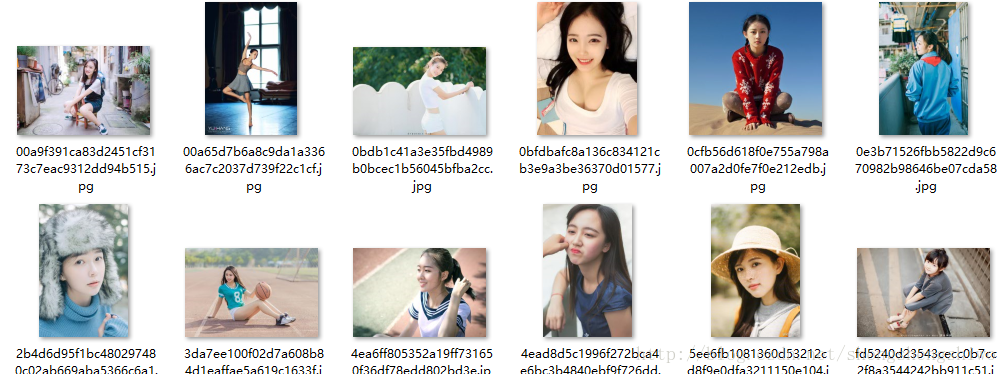
讲在最后:在程序运行过程中,会出现没全部爬完就停止,这是一位这网站
offset的值不是连续的,比如:http://www.meizitu.com/a/124.html网址不存在,
而http://www.meizitu.com/a/125.html网址就存在。现在这种异常还得手动修改,后期再看看能不能完善代码。程序代码我已经上传到码云上了,欢迎大家指正。
https://gitee.com/shengshengshiwo/Scrapy-meizitu.git
欢迎关注我的个人公众号。
