1.Introduction to Non-Personalized Recommenders
依据群众的average选择推荐,简单有效,但是不够个性化。例如,我想给冰淇淋加点酱,结果给我推荐的是最受欢迎的番茄酱。这显然和我的context不符合,于是引入association recommenders缓解该问题,现在可能会给用户推荐巧克力酱啦。但association recommenders本身会有item popularity的问题,例如,香蕉是超市最爆的item,那么无论user买过什么,只要没买过香蕉,都会给他推荐香蕉,这就得引入compensate overall popularity
- To understand the value of non-personalized recommenders, and domains where they are most useful
- To understand the drawbacks of nonpersonalized recommender systems
- To understand the basics of:
– Aggregated opinion recommenders
– Basic product association recommenders - Review examples of the above …
Zagat
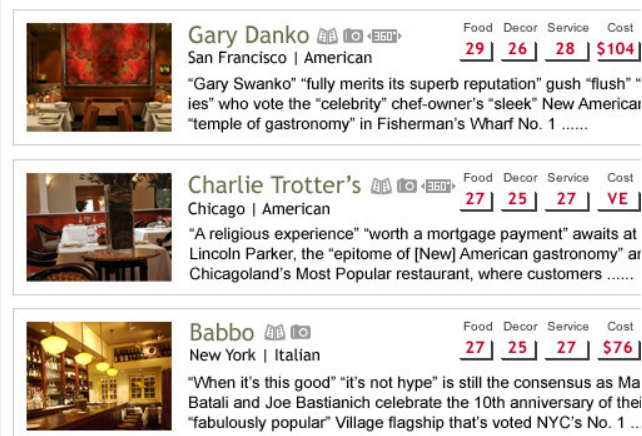
The “secret” formula
Rating = {0, 1, 2, 3}
Score = round (MEAN(ratings) * 10)
– OK, maybe not so secret – but effective!
crystal cruises
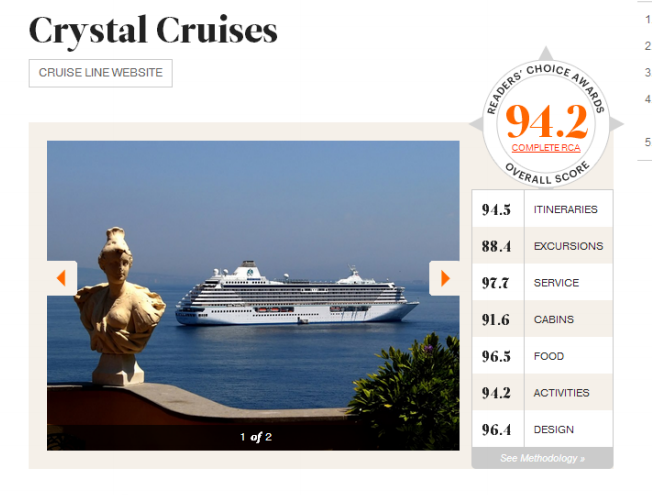
Same idea, different formula
- Conde Nast Traveller tallies the percentage of people who rate a particular hotel, cruise,etc. as “very good” or “excellent”
- Relative merits of the two techniques …
– How do we treat a score of “good” vs. “awful”
Averages can be Misleading
• Later this module … we’ll discuss ways to mislead using averages.
• See if you can come up with examples or ideas (post to the class forum, and vote up the ones you find most compelling)
我没想到……
Averages Lack Context …
- Ordering an ice-cream sundae
– You want a recommendation for a sauce
– Do you want to hear that ketchup is the most popular sauce?
虽然ketchup是most popular sauce,但和ice-cream sunda不搭! - One interesting context is a current product(or set of products) – what sauce is mostcommonly associated with a sundae??
- This leads to the concept of product association recommenders
or non-personalized product association
People who X also Y …
Great idea, but how to formalize
First, what’s our dataset
- User profiles (people who ever bought one and the other)? – not good for ketchup
依据买过ice-cream sunda的人,找出他们最喜欢的sauce,结果可能还是ketchup,所以X和Y在购买时间跨度上不能太长,否则就会沦落为profiles啦 - Transaction data (people who bought them at the same time)? – not good for follow-up sales
- User profiles but time-constrained (within a month, afterwards, …)?
associate的时间窗太长会变成profile,太短不便于 follow-up sales
Computing the ranking
Start simple: percentage of X-buyers who also bought Y
- Intuitively right, but is it useful? What if X is anchovy paste and Y is bananas?
banana是超市最热门的商品,比如100个买了anchovy的人中,有95个会买banana,所以热门的商品容易被推荐,这样的推荐不太合适,即使用户会买单,也不符合我们想卖掉更多样产品的初衷 - Challenge – doesn’t compensate for overall popularity of Y
Take two – does X make Y more likely?
将人群分成两组,买过X和没买过X(!X),比较和Y的关联性
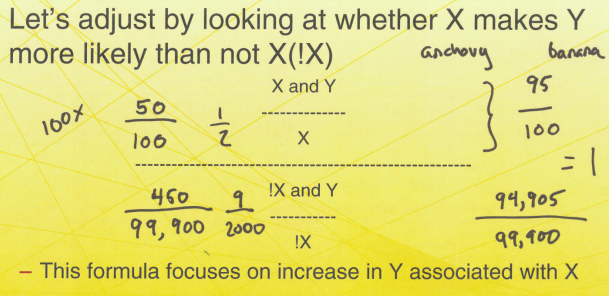
Association rule
Association rule mining brings us the lift metric:
- This looks at non-directional assocation
不清楚因果关系,是因为买了啤酒才买尿布?,还是买了尿布才买啤酒?
上一种方法也会如此呀!该怎样才能知道呢?时间先后?
- More generally association rules look at baskets of products, not just individuals
Back to Zagat
Some early Zagat fans argue the guide has been getting worse. Why? – Too many mediocre restaurants with good scores – Too many excellent restaurants with mediocre scores • What’s happening here? – **Self-selection bias** 如果你觉得不好,一般不会再去,而再去的人一般是觉得还可以,所以他们会一直给好评,这样会拉高rate – Increased diversity of raters 萝卜白菜,各有所爱Some take-away lessons
- Non-personalized averages can be effective in the right application
Need to understand relationship between average and user need; correct average
比如,我对电脑的性能有要求,average 电脑 不适合我们这种专业客户,而对于我父母是可以的,我需要个性化推荐 - Product associations can provide useful non personalized recommendations in a context
- Need to identify context; data source/scope
purchase together or purchase sequence? - Still face challenges in a clustered diverse population (e.g., maybe we don’t all want bananas)
2.Preferences and Ratings
这一节是走马观花的节奏,难在弄清楚各种rating信息的适用场景
To recommend, we need data (what users like, what goes together, etc.)
Data comes from users, is collected somehow
This lecture’s topic: what data we collect, how,and what it means
Learning Objectives
- Understand what data recommenders can use to learn what users like
- Identify types of data collected from users
- Understand when different data types are possible and appropriate
- Be able to identify types of preference data likely used in a system
Preference Model
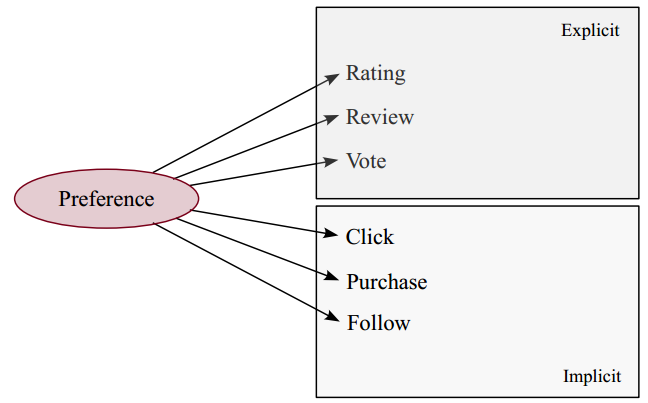
Explicit Ratings
Just ask the users what they think!
Star Ratings
- Widely-used interface
- Several design decisions
– 5? 7? 10?
– Half-stars?
– Provide meaning/calibration?
– More not necessarily better
the more -> the less reliable ,but 能让用户happy,因为可以让user更自由地表示。如此,对于选择恐惧症患者呢? - 5, with or without ½, very common
Thumbs and Likes
- Vote up/down
- Or just ‘Like’/‘+1’
- Common with ephemeral items
– News aggregation (Reddit, Digg)
– Q&A (StackOverflow)
– YouTube - Very low cost to rate
Other Interfaces
- Continuous scales
- Pairwise preference
不是对单一item的绝对评价,而是多个item pk 的相对 rate,比如,宝宝,你更喜欢麻麻,还是更喜欢芭比 - Hybrid (e.g. 1-100 + never again)
1-100是什么意思?
- Temporary (e.g. Pandora 30-day suspend)
When are ratings provided?
- Consumption — during or immediately after experiencing the item
It provides a very close-to-the-experience way of getting user preference that doesn’t suffer from memory effects.
可是我觉得有些东西,当下的rate可能是不理性的 - Memory — some time after experience
- Expectation — the item has not been experienced
For high cost, low volume items such as houses or apartments or cars,例如,房子的喜好,每个人一生也就买过几套房子,可以通过描述房子来获得preference
Joke ratings
被玩坏的rating
Difficulties with Ratings
- Are ratings reliable and accurate?
一般不会,比如,你现在给5star,过了一个星期再评论可能就只有4star - Do user preferences change?
- What does a rating mean?
有些用户,通通都是给4star,那他的rating就意义不大了
不同用户对不同rating 量级认识不同,比如我认为4是很好,而有人可能觉得5是很好
Implicit Data
- Data collected from user actions
- Key difference: user action is for some other purpose, not expressing preference
我觉得是交集的关系吧 - Their actions say a lot!
哈哈,我很懒,我不评论……
Reading Time
- Early implicit data: how long did user read?
- Listening and watching
– IMMS
– Video services
Binary actions
- Click on link (ad, result, cross-reference)
- Don’t click on link
- Purchase
- Follow/Friend
关注某一主题/person
Subtleties and Difficulties
- What does the action mean?
– Purchase: they might still hate it
– Don’t click: expect bad, or didn’t see - How to scale/represent actions?
点赞?+1?rating?,最终要整合到推荐系统中! - Lots of opportunity to be creepy
– Education may help
– So can respecting privacy
???
Conclusion
- Recommenders mine what users say and what they do to learn preferences
- Ratings provide explicit expressions of preference
- Implicit data benefits from greater volume
3. Predictions and Recommendations
Predictions 和 Recommendations 内在实现逻辑很类似(下一节会讲到Recommendations的关键步骤,ranking),只是展示形式前者更高调而已,感觉现在都用比较低调的方式。不过rating统计,也可以算是一种Predictions
Learning Objectives
- To understand the ways in which recommender output can be used
- To understand the distinction between predictions and recommendations
- To understand the distinction between organic and explicit presentation
- To review examples and understand which presentation makes most sense in different applications.
Predictions
Estimates of how much you’ll like an item
– Often scaled to match some rating scale
– Often tied to search or browsing for specific products
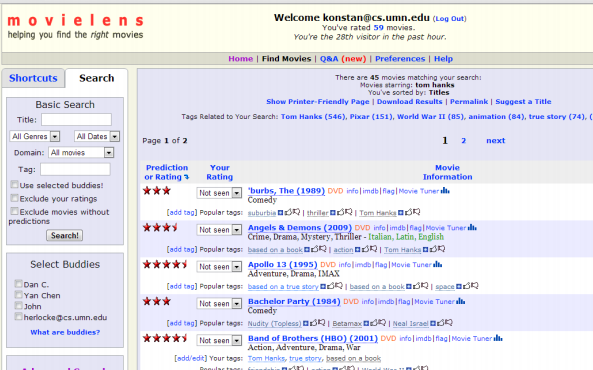
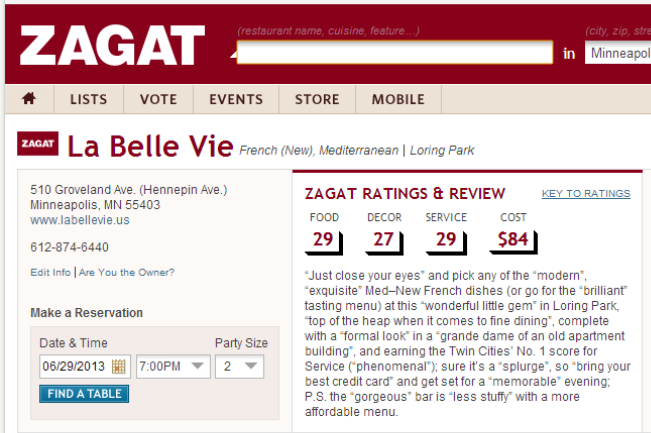
只是average,感觉乱入,当然咯,也可以认为是预测
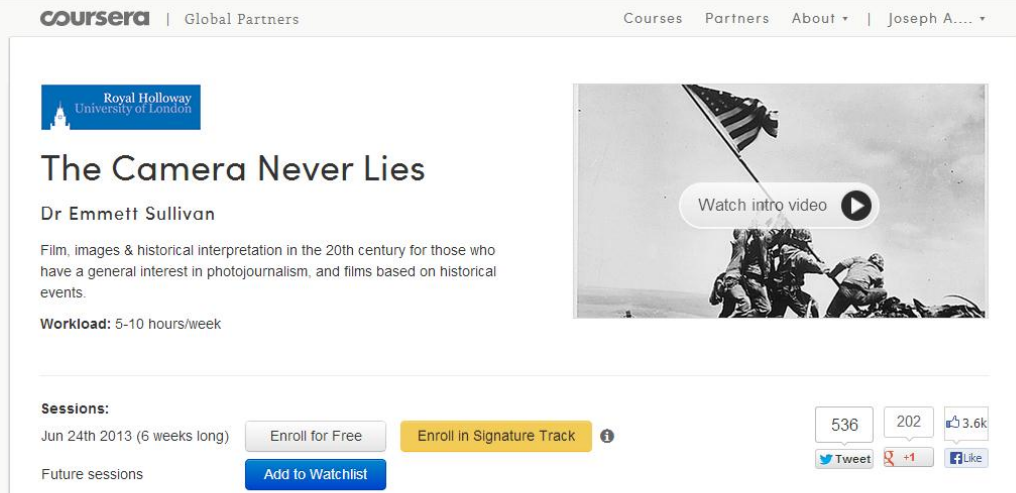
只是计数,non-personalized
Recommendations
Recommendations are suggestions for items you might like (or might fit what you’re doing)
– Often presented in the form of “top-n lists”
– Also sometimes just placed in front of you
已笑屎啦
Prediction vs Recommendation
Often, the two come together
- Predictions:
– Pro: helps quantify item
– Con: provides something falsifiable - Recommendations
– Pro: provides good choices as a default
– Con: if perceived as top-n, can result in failure to explore (if top few seem poor)
为什么要限制为top-n呢?像谷歌搜索一样,让user可以自由控制量,不过,搜索和推荐不同,搜索是用户主动要,而推荐是我们被动推,太多会骚扰用户,但是用户还是可以自己控制量呀!
if it doesn’t fall on the first page it’s lost phenomenon.
Another dimension to consider
How explicit is the prediction or recommendation (vs. organic)?
- Historical note: we paid for it, we’ll let you know hey,here’s something we picked just for you.
- Today: balance between explicit prediction (falsifiable) and coarser granularity (you might like this!)
- Today: balance between theses are the best (top-n) and softer presentation (here are some that might be interesting)
为什么会这样演变呢?
- 被陌生的系统深入了解是一件很恐怖的事情,本能的抗拒
- 用户容易觉得被操作,push for some reason
- 错误多了,容易失去用户的信任
4. Scoring and Ranking
Last 2 lectures:
– how to collect data
– what we present to users
This lecture: how to do it
– what predictions to show
– how to rank
这一节,的scoring感觉还是第2节的延伸,当然也是ranking的基础,从而引出依据这个基础直接ranking会有一些问题,比如,场景需要+一些business consideration;比如,当评论过少时,结果并不能很好地说明item popular;比如item的生命周期很短,再好的item过期了,也不应该上架等问题。然后就是怎样解决这三方面的问题,基本思想是+惯性+衰减
- Understand several ways of computing and displaying predictions
- Understand how to rank items with sparse,time-shifting data
- Understand several points in the design space for prediction and recommendation, and some of their tradeoffs
Goal of Display
To help users decide to buy/read/view the item.
Displaying Aggregate Preferences (predict)
Simple Display Approaches
- Average rating / upvote proportion
- Net upvotes / # of likes
upvotes-downvotes
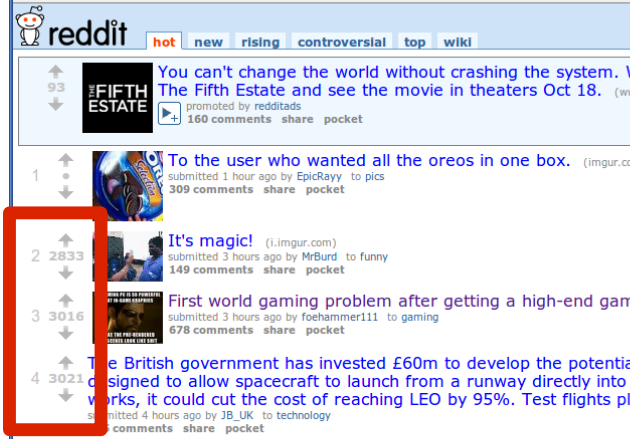
- % >= 4 stars (‘positive’)
- Full distribution
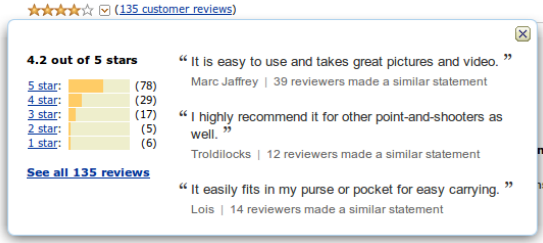
再分别深入探讨下
- Average rating / upvote proportion
- Of people who vote, do they like it?
- Doesn’t show popularity
No:比如对于新的item,可能只是一个人的评论,即使有很较多人评论,也有可能不靠谱!有可能只是适合特别奇葩的人群
Net upvotes / # of likes
– Shows popularity
net voting问题:5:0,5000:4995是一样的
– No controversy% >= 4 stars (‘positive’)
直观
能够处理部分不同人对好的scale不一样的问题- Full distribution
复杂
Ranking
- What do you put at the top of Reddit?
- What is at the top of the e-Bay search list?
- You don’t have to rank by prediction
Why not rank by score?
我之前就是这么天真的以为
- Too little data (one 5-star rating)
不具有相对参考意义 - Score may be multivariate (histogram)
例如,直方图,不便于降到一维比较 Domain or business considerations
- Item is old
- Item is ‘unfavored’
收益高的排前面……
Ranking Considerations
- Confidence
– How confident are we that this item is good? - Risk tolerance
– High-risk, high-reward
– Conservative recommendation - Domain and business considerations
– Age
– System goals
Damped means
- Problem: low confidence w/ few ratings
- Solution: assume that, without evidence,everything is average
- Ratings are evidence of non-averageness
- k controls strength of evidence required
∑urui+kμn+k
-
μ 是所有商品的average rate,当n=0 ,可以看得出来这就是,商品在没有评论之前的初始值 - k controls strength to overcome the global mean
例如k=5,μ=3 ,现在有5个 4 star,5个5 star,那么抵消初值之后的rate:
4∗5+5∗5+5∗310+5=6015=4 ,k 可以理解为初始评论μ 的惯性大小 - 如果n够大,那么初值的影响可以忽略不计,所以评论数少的时候,可以缓解取样不够的问题,评论多的时候,又不会影响真实的rate
- 用于comment
-
Confidence Intervals
- From the reading: lower bound of statistical confidence interval (95%)
- Choice of bound affects risk/confidence
– Lower bound is conservative: be sure it’s good
– Upper bound is risky: there’s a chance of amazing
这里的bound 是指 Confidence Intervals,而且是相对同样的置信水平,例如置信水平为95%,置信区间越窄,结果越靠谱,显然,数据量越多,置信区间就会越小 - Reddit uses Wilson interval (for binomial) to rank comments
Domain Consideration: Time
- Reddit: old stories aren’t interesting – even if they have many upvotes!
不禁想起了,遗忘因子最小二乘 - eBay: items have short lifetimes
Scoring news stories
Hacker News
所以,该measure,是age和popular的平衡,P是惩罚项,不同种类的item P不一样,可以让获利高的商品更多的被推荐
- Net upvotes, polynomially decayed by age
- Old items scored mostly by vote
- Multiplied by item penalty terms
– incorporate community goals into score
Reddit algorithm (c. 2010)
U/D 与 time的作用分开
45000s =12.5h
ref:http://www.ruanyifeng.com/blog/2012/03/ranking_algorithm_reddit.html
- Log term applied to votes
– decrease marginal value of later votes - Time is seconds since Reddit epoch
- Buries items with negative votes
- Time vs. vote impact independent of age
- Scores news items, not comments
Ranking Wrap-Up
- There are some theoretically grounded approaches (confidence interval, damping)
- Many sites use ad-hoc methods
- Most formulas have constants, will be highly service-dependent
- Can manipulate for ‘good’ or ‘evil’
- Build based on domain properties, goals
Predict with sophisticated score?
- Theoretically a fine thing to do
- Be careful with transparency/scrutability
– If you say ‘average rating’ for damped mean, and show ratings, users may be confused
– Most important case (low ratings) also easiest to hand-verify
Conclusion
- Sparsity, inconsistency, temporal concerns make data messy
- Simple scoring doesn’t necessarily match the domain or business
- There are good ways to deal with this (decay,time, penalties, damping)
- We’ll see more normalizations later
5.Interview with Anthony Jameson
感觉这个心理学家像是来找茬的,不过从心理学角度分析,还是蛮有意思的
- rs 适合辅助,而不是直接给我们做决定
不过也要分情况,如果推荐音乐,rs不自作主张,用起来反而显得麻烦,如果是推荐房子这种高价值的item,必须是打辅助的模式呀 4种 用户决策模式
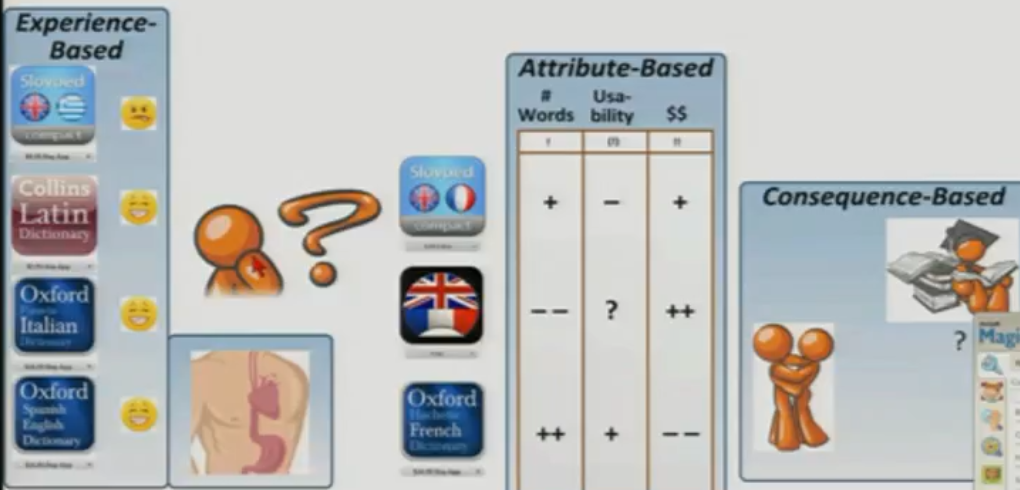

experience
依据过去的经验
similar to content-based or case-based
seems irrational: feel/emotion,but ofen the best wayattribute
理性评估自己的需求和商品的匹配程度- consequence
未来的受益 - social

没听懂,为什么基于过去不能用???
preference的挑战
一直坚持用的可能不一定是喜欢哦
比如,我一直在用的桌面美女,并不是我喜欢,只是我懒得换,习惯就好,此外,switch的cost高
preference 没有我们想象的solid
anchor effect
后面又扯到了锚定心理……