版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/tianrolin/article/details/52586975
全连接层InnerProductLayer的原理很简单,说白了就是矩阵乘法运算。正向传导时输出数据等于输入数据乘上权重,如果有偏置项就再加上偏置项。写成公式就是:
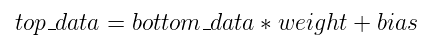
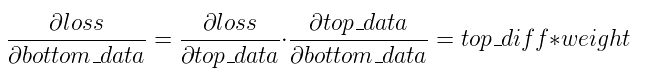
矩阵乘法在CPU端采用OpenBLAS实现,在GPU端则采用NVIDIA cuBLAS实现加速。
inner_product_layer.hpp定义如下,
template <typename Dtype>
class InnerProductLayer : public Layer<Dtype> {
public:
explicit InnerProductLayer(const LayerParameter& param)
: Layer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "InnerProduct"; }
virtual inline int ExactNumBottomBlobs() const { return 1; }
virtual inline int ExactNumTopBlobs() const { return 1; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
// 矩阵乘法参数(M, K) * (K, N) = (M, N)
int M_; // 输入数据的数量, 即patch_size
int K_; // 单个输入数据包含的元素个数
int N_; // 输出层的神经元个数
// 是否包含偏置项
bool bias_term_;
// 偏置项乘子
Blob<Dtype> bias_multiplier_;
// 是否转置
bool transpose_; ///< if true, assume transposed weights
};inner_product_layer.cpp定义如下,
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int num_output = this->layer_param_.inner_product_param().num_output();
bias_term_ = this->layer_param_.inner_product_param().bias_term();
transpose_ = this->layer_param_.inner_product_param().transpose();
N_ = num_output;
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
// 如果输入图像的维度是(N, C, H, W),则K_ = C * H * W
K_ = bottom[0]->count(axis);
// 确认是否需要初始化权重
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
// 如果包含偏置项,则将blobs_的size设为2
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// 设置权重的维度
vector<int> weight_shape(2);
if (transpose_) {
weight_shape[0] = K_;
weight_shape[1] = N_;
} else {
weight_shape[0] = N_;
weight_shape[1] = K_;
}
this->blobs_[0].reset(new Blob<Dtype>(weight_shape));
// 初始化权重(使用xavier初始化方法)
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// 如果包含偏置项,则将偏置项初始化为0
if (bias_term_) {
vector<int> bias_shape(1, N_);
this->blobs_[1].reset(new Blob<Dtype>(bias_shape));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// 确认维度
const int axis = bottom[0]->CanonicalAxisIndex(
this->layer_param_.inner_product_param().axis());
const int new_K = bottom[0]->count(axis);
CHECK_EQ(K_, new_K)
<< "Input size incompatible with inner product parameters.";
// M_等于patch_size
M_ = bottom[0]->count(0, axis);
// 将输出项top[0]的维度置为(patch_size, N_)
vector<int> top_shape = bottom[0]->shape();
top_shape.resize(axis + 1);
top_shape[axis] = N_;
top[0]->Reshape(top_shape);
// 设置偏置项乘子
if (bias_term_) {
vector<int> bias_shape(1, M_);
bias_multiplier_.Reshape(bias_shape);
// 将偏置项乘子bias_multiplier_初始化为1
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}
// CPU正向传导
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = top[0]->mutable_cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();
// bottom_data为M*K矩阵,权重为K*N矩阵,top_data为M*N矩阵
// top_data = bottom_data * weight
caffe_cpu_gemm<Dtype>(CblasNoTrans, transpose_ ? CblasNoTrans : CblasTrans,
M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., top_data);
// 如果包含有偏置项
if (bias_term_) {
// top_data += bias_multiplier * bias
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,
bias_multiplier_.cpu_data(),
this->blobs_[1]->cpu_data(), (Dtype)1., top_data);
}
// 因此两步合并的结果就是 top_data = bottom_data * weight + bias_multiplier * bias
}
// CPU反向传导
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
const vector<Blob<Dtype>*>& bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* bottom_data = bottom[0]->cpu_data();
// 求权重的偏导,weight_diff += top_diff * bottom_data
if (transpose_) {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
K_, N_, M_,
(Dtype)1., bottom_data, top_diff,
(Dtype)1., this->blobs_[0]->mutable_cpu_diff());
} else {
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans,
N_, K_, M_,
(Dtype)1., top_diff, bottom_data,
(Dtype)1., this->blobs_[0]->mutable_cpu_diff());
}
}
// 求偏置项的偏导,bias_diff += top_diff * bias_multiplier
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bias
caffe_cpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.cpu_data(), (Dtype)1.,
this->blobs_[1]->mutable_cpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
// 求bottom数据的偏导,bottom_data_diff = top_diff * weight
if (transpose_) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->cpu_data(),
(Dtype)0., bottom[0]->mutable_cpu_diff());
} else {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans,
M_, K_, N_,
(Dtype)1., top_diff, this->blobs_[0]->cpu_data(),
(Dtype)0., bottom[0]->mutable_cpu_diff());
}
}
}
// 如果CPU_ONLY模式则禁止Forward_gpu和Backward_gpu函数
#ifdef CPU_ONLY
STUB_GPU(InnerProductLayer);
#endif
扫描二维码关注公众号,回复:
3844699 查看本文章
