版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/tianrolin/article/details/52522662
Caffe网络正向传导时,首先进行的是DataLayer数据层的传导。该层从文件读取数据,加载至它的上一层卷积层。反向传播时,因为数据层不需要反传,所以它的Backward_cpu()和Backward_gpu()都是空函数。下面看一下DataLayer类图关系。
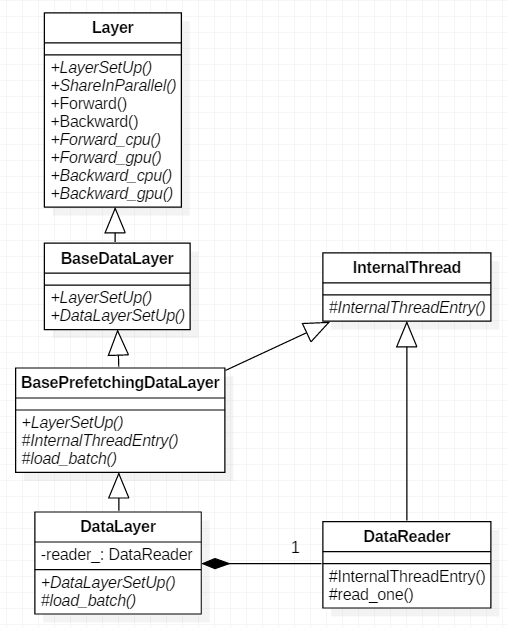
首先从父类BaseDataLayer开始看源码,base_data_layer.hpp头文件:
template <typename Dtype>
class BaseDataLayer : public Layer<Dtype> {
public:
// 构造函数
explicit BaseDataLayer(const LayerParameter& param);
// 实现一般数据层构建,并调用DataLayerSetup函数
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// 数据层可在并行时共享
virtual inline bool ShareInParallel() const { return true; }
// 空的构建函数(该函数为虚函数,待子类重载)
virtual void DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {}
// 数据层没有bottom层,因此Reshape函数为空函数
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {}
// 反向传播,空函数
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {}
virtual void Backward_gpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {}
protected:
TransformationParameter transform_param_;
shared_ptr<DataTransformer<Dtype> > data_transformer_;
// 是否包含有输出标签
bool output_labels_;
};base_data_layer.cpp实现文件
// 构造函数
template <typename Dtype>
BaseDataLayer<Dtype>::BaseDataLayer(const LayerParameter& param)
: Layer<Dtype>(param),
transform_param_(param.transform_param()) {
}
template <typename Dtype>
void BaseDataLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
// 如果top层size大于1,则包含有标签
if (top.size() == 1) {
output_labels_ = false;
} else {
output_labels_ = true;
}
data_transformer_.reset(
new DataTransformer<Dtype>(transform_param_, this->phase_));
// 初始化随机数生成器
data_transformer_->InitRand();
// 调用构建虚函数
DataLayerSetUp(bottom, top);
}接下来看一下子类BasePrefetchingDataLayer类,该类不仅继承了BaseDataLayer类,还继承自InternalThread类。因此该类重载了InternalThread类的虚函数InternalThreadEntry()。
template <typename Dtype>
class BasePrefetchingDataLayer :
public BaseDataLayer<Dtype>, public InternalThread {
public:
explicit BasePrefetchingDataLayer(const LayerParameter& param);
// 构建函数
void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// CPU正向传导函数
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// GPU正向传导函数
virtual void Forward_gpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// 预取数据块大小
static const int PREFETCH_COUNT = 3;
protected:
// 线程函数,虚函数重载
virtual void InternalThreadEntry();
// 加载batch,纯虚函数,由子类DataLayer实现
virtual void load_batch(Batch<Dtype>* batch) = 0;
Batch<Dtype> prefetch_[PREFETCH_COUNT];
BlockingQueue<Batch<Dtype>*> prefetch_free_;
BlockingQueue<Batch<Dtype>*> prefetch_full_;
Blob<Dtype> transformed_data_;
};base_data_layer.cpp实现文件
template <typename Dtype>
BasePrefetchingDataLayer<Dtype>::BasePrefetchingDataLayer(
const LayerParameter& param)
: BaseDataLayer<Dtype>(param),
prefetch_free_(), prefetch_full_() {
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_free_.push(&prefetch_[i]);
}
}
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
// 先调用父类LayerSetUp
BaseDataLayer<Dtype>::LayerSetUp(bottom, top);
// 线程开启前先分配内存&显存,防止在某些GPU上报错
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_[i].data_.mutable_cpu_data();
if (this->output_labels_) {
prefetch_[i].label_.mutable_cpu_data();
}
}
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
for (int i = 0; i < PREFETCH_COUNT; ++i) {
prefetch_[i].data_.mutable_gpu_data();
if (this->output_labels_) {
prefetch_[i].label_.mutable_gpu_data();
}
}
}
#endif
DLOG(INFO) << "Initializing prefetch";
// 初始化随机数生成器
this->data_transformer_->InitRand();
// 开启线程
StartInternalThread();
DLOG(INFO) << "Prefetch initialized.";
}
// 线程函数,由StartInternalThread开启
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::InternalThreadEntry() {
#ifndef CPU_ONLY
// 在GPU上启用stream异步加载
cudaStream_t stream;
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaStreamCreateWithFlags(&stream, cudaStreamNonBlocking));
}
#endif
try {
while (!must_stop()) {
Batch<Dtype>* batch = prefetch_free_.pop();
// 加载batch,该函数由子类DataLayer实现
load_batch(batch);
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
batch->data_.data().get()->async_gpu_push(stream);
CUDA_CHECK(cudaStreamSynchronize(stream));
}
#endif
prefetch_full_.push(batch);
}
} catch (boost::thread_interrupted&) {
// Interrupted exception is expected on shutdown
}
#ifndef CPU_ONLY
if (Caffe::mode() == Caffe::GPU) {
CUDA_CHECK(cudaStreamDestroy(stream));
}
#endif
}
// CPU正向传导
template <typename Dtype>
void BasePrefetchingDataLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
Batch<Dtype>* batch = prefetch_full_.pop("Data layer prefetch queue empty");
// Reshape成与batch数据同一维度
top[0]->ReshapeLike(batch->data_);
// 将batch数据拷贝至top层blob[0]
caffe_copy(batch->data_.count(), batch->data_.cpu_data(),
top[0]->mutable_cpu_data());
DLOG(INFO) << "Prefetch copied";
// 如果包含输出标签
if (this->output_labels_) {
// Reshape成batch标签同一维度
top[1]->ReshapeLike(batch->label_);
// 将batch标签拷贝至top层blob[1]
caffe_copy(batch->label_.count(), batch->label_.cpu_data(),
top[1]->mutable_cpu_data());
}
prefetch_free_.push(batch);
}
// 如果CPU_ONLY模式则禁止Forward_gpu和Backward_gpu函数
#ifdef CPU_ONLY
STUB_GPU_FORWARD(BasePrefetchingDataLayer, Forward);
#endif最后分析下最终的子类DataLayer,由于很多方法由它的父类实现了,该类功能很简单了,只重载了两个虚函数DataLayerSetUp()和load_batch()。
template <typename Dtype>
class DataLayer : public BasePrefetchingDataLayer<Dtype> {
public:
explicit DataLayer(const LayerParameter& param);
virtual ~DataLayer();
// 构建函数,重载虚函数
virtual void DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
// DataLayer uses DataReader instead for sharing for parallelism
virtual inline bool ShareInParallel() const { return false; }
virtual inline const char* type() const { return "Data"; }
virtual inline int ExactNumBottomBlobs() const { return 0; }
virtual inline int MinTopBlobs() const { return 1; }
virtual inline int MaxTopBlobs() const { return 2; }
protected:
// 加载batch,重载虚函数
virtual void load_batch(Batch<Dtype>* batch);
// DataReader对象
DataReader reader_;
};cpp文件如下,
// 构造函数
template <typename Dtype>
DataLayer<Dtype>::DataLayer(const LayerParameter& param)
: BasePrefetchingDataLayer<Dtype>(param),
reader_(param) {
}
// 析构函数
template <typename Dtype>
DataLayer<Dtype>::~DataLayer() {
// 终止线程
this->StopInternalThread();
}
template <typename Dtype>
void DataLayer<Dtype>::DataLayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top) {
const int batch_size = this->layer_param_.data_param().batch_size();
// 读取一个dataum,用来初始化top blob维度
Datum& datum = *(reader_.full().peek());
// 从datum获取单个数据维度
vector<int> top_shape = this->data_transformer_->InferBlobShape(datum);
this->transformed_data_.Reshape(top_shape);
// 加上batch尺寸
top_shape[0] = batch_size;
// Reshape
top[0]->Reshape(top_shape);
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
// Reshape,并分配data内存
this->prefetch_[i].data_.Reshape(top_shape);
}
// 输出尺寸信息
LOG(INFO) << "output data size: " << top[0]->num() << ","
<< top[0]->channels() << "," << top[0]->height() << ","
<< top[0]->width();
// label
if (this->output_labels_) {
vector<int> label_shape(1, batch_size);
top[1]->Reshape(label_shape);
for (int i = 0; i < this->PREFETCH_COUNT; ++i) {
// Reshape,并分配label内存
this->prefetch_[i].label_.Reshape(label_shape);
}
}
}
// 该函数被InternalThreadEntry线程函数调用
template<typename Dtype>
void DataLayer<Dtype>::load_batch(Batch<Dtype>* batch) {
CPUTimer batch_timer;
batch_timer.Start();
double read_time = 0;
double trans_time = 0;
CPUTimer timer;
CHECK(batch->data_.count());
CHECK(this->transformed_data_.count());
// 读取一个dataum,用来初始化top blob维度,同上
const int batch_size = this->layer_param_.data_param().batch_size();
Datum& datum = *(reader_.full().peek());
vector<int> top_shape = this->data_transformer_->InferBlobShape(datum);
this->transformed_data_.Reshape(top_shape);
top_shape[0] = batch_size;
batch->data_.Reshape(top_shape);
Dtype* top_data = batch->data_.mutable_cpu_data();
Dtype* top_label = NULL; // suppress warnings about uninitialized variables
if (this->output_labels_) {
top_label = batch->label_.mutable_cpu_data();
}
// 循环加载batch
for (int item_id = 0; item_id < batch_size; ++item_id) {
timer.Start();
// 读取数据datum
Datum& datum = *(reader_.full().pop("Waiting for data"));
// 统计读取时间
read_time += timer.MicroSeconds();
timer.Start();
// 计算指针offset
int offset = batch->data_.offset(item_id);
this->transformed_data_.set_cpu_data(top_data + offset);
// 将datum数据拷贝到batch中
this->data_transformer_->Transform(datum, &(this->transformed_data_));
// 拷贝标签
if (this->output_labels_) {
top_label[item_id] = datum.label();
}
// 统计拷贝时间
trans_time += timer.MicroSeconds();
reader_.free().push(const_cast<Datum*>(&datum));
}
timer.Stop();
// 统计加载batch总时间
batch_timer.Stop();
// 输出时间开销
DLOG(INFO) << "Prefetch batch: " << batch_timer.MilliSeconds() << " ms.";
DLOG(INFO) << " Read time: " << read_time / 1000 << " ms.";
DLOG(INFO) << "Transform time: " << trans_time / 1000 << " ms.";
}