本系列文章总共有七篇,目录索引如下:
AdaBoost 人脸检测介绍(1) : AdaBoost身世之谜
AdaBoost 人脸检测介绍(2) : 矩形特征和积分图
AdaBoost 人脸检测介绍(3) : AdaBoost算法流程
AdaBoost 人脸检测介绍(4) : AdaBoost算法举例
AdaBoost 人脸检测介绍(5) : AdaBoost算法的误差界限
AdaBoost 人脸检测介绍(6) : 使用OpenCV自带的 AdaBoost程序训练并检测目标
AdaBoost 人脸检测介绍(7) : Haar特征CvHaarClassifierCascade等结构分析
6. 使用OpenCV自带的 AdaBoost程序训练并检测目标
OpenCV自带的AdaBoost程序能够根据用户输入的正样本集与负样本集训练分类器,常用于人脸检测,行人检测等。它的默认特征采用了Haar,不支持其它特征。人脸目标检测分为三个步骤:样本创建、训练分类器、利用训练好的分类器进行目标检测。
6.1 准备工作
● OpenCV(版本2.4.10)
● OpenCV内建的两个可执行程序:opencv_createsamples.exe 和 opencv_haartraining.exe
● N张人脸照片:N当然越大越好,目前从CC主播截图裁剪了100多张人脸图像。
● N张非人脸照片:为了让程序分辨何为人脸、何为非人脸,这一步也是非常重要的。
准备好以上的内容之后在D盘下创建了一个face目录来放置这些内容,如下图:
其中bin目录存放了OpenCV的库和可执行程序,如图:

positive目录存放了108张人脸图像,大小为20 x 20;
negative 目录存放了336张非人脸图像,大小为140 x 140;
data目录用于存放训练过程中生成的各种分类器,目前暂时为空。
6.2 样本创建
训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片。
● 输入cmd打开Dos命令窗口,进入到negtive目录
● 输入 dir /b > negdata.dat,如图:

● 打开 negdata.dat文件,将最后一行的negdata.dat删除,保存退出,如图:

对于
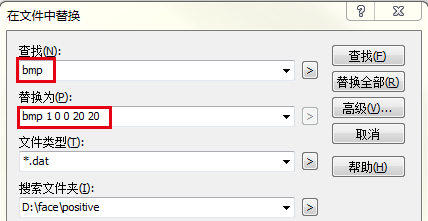
● 制作一个正样本描述文件,用于描述正样本文件名(包括绝对路径或相对路径),正样本数目以及各正样本在图片中的位置和大小。典型的正样本描述文件如下:
positive/1.bmp 1 0 0 20 20
positive/2.bmp 1 0 0 20 20
positive/3.bmp 1 0 0 20 20
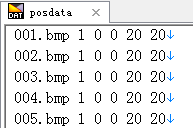
不过你可以把描述文件放在你的positive目录(即正样本目录)下,这样你就不需要加前面的相对路径了。同样它的生成方式可以用负样本描述文件的生成方法,最后用txt的替换工具将“bmp”全部替换成“bmp 1 0 0 20 20”就可以了,bmp后面那五个数字分别表示图片个数,目标的起始位置及宽高。这样就生成了正样本描述文件posdata.dat,如下图:

将最后一行的posdata.dat删除,接下来是将“bmp”全部替换成“bmp 1 0 0 20 20”:
完成之后的posdata.dat文件如下图所示:
● 运行CreateSample程序,如下图所示:
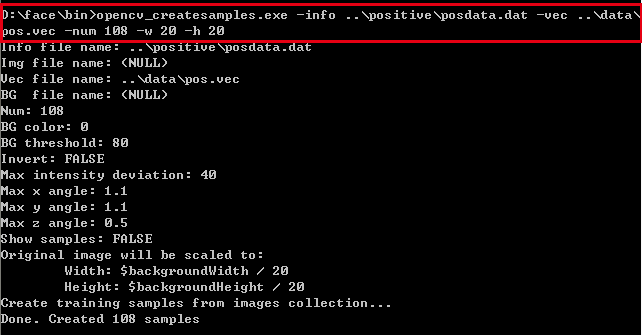
运行完之后在D:\face\data下生成 pos.vec文件,该文件包含正样本数目、宽高及所有样本图像数据。 Createsamples程序的一些常用命令行参数:
-vec 训练好的正样本的输出文件名。
-img 源目标图片(例如:一个公司图标)
-bg 背景描述文件。
-num 要产生的正样本的数量,和正样本图片数目相同。
-w 输出样本的宽度(以像素为单位)
-h 输出样本的高度,以像素为单位
### 6.3 训练分类器
样本创建之后,接下来就要训练分类器,这个过程是由haartraining程序来实现。该程序源码由OpenCV自带,且可执行程序在OpenCV安装目录的bin目录下。Haartraining的一些常用命令行参数如下:
-data 存放训练好的分类器的路径名。
-vec 正样本文件名
-bg 背景描述文件。
-npos 用来训练每一个分类器阶段的正样本。
-nneg 用来训练每一个分类器阶段的负样本。
-nstages 训练的阶段数。
-mem 预计的以MB为单位的可用内存,内存越大则训练速度越快。
-minhitrate 每个阶段分类器需要的最小的命中率,总的命中率为min_hit_rate的number_of_stages次方。
-maxfalsealarm 没有阶段分类器的最大错误报警率,总的错误警告率为max_false_alarm_rate的number_of_stages次方。
-w 训练样本的宽(以像素为单位),必须和训练样本创建的尺寸相同。
-h 训练样本的高(以像素为单位),必须和训练样本创建的尺寸相同。
一个训练分类器的例子如下图:

按下Enter键之后就开始训练,如图:
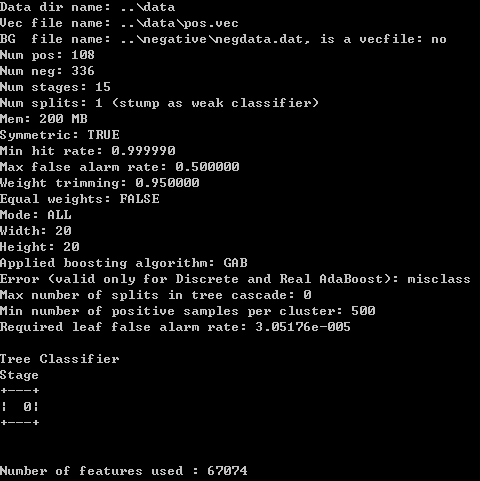
。。。 。。。
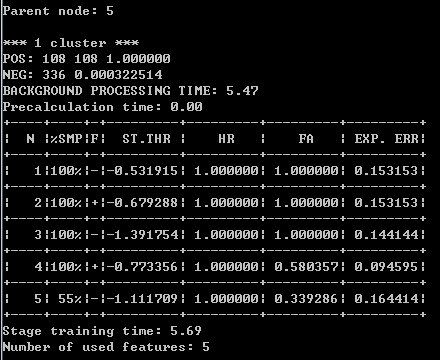
。。。 。。。

每一级的强训练器达到你预设的比例以后就跑去训练下一级了,那个HR比例不要设置太高,不然会需要好多样本,然后nstages不要设置太小,不然到时候拿去检测速度会很慢。训练结束之后在data目录下生成了9个目录,每个目录下存放了训练好的分类器,如图:

还会在D:\face目录下生成 data.xml,下一次就可以拿着这个xml文件去做检测了!

6.4 开始检测
采用前面训练得到的data.xml作为分类器来检测人脸,此处省略检测代码:

检测效果图省略!检测效果不是很理想,需要调整训练参数和样本数目,这就需要慢慢琢磨!
[同步本人网易博客的文章] AdaBoost 人脸检测介绍(6) : 使用OpenCV自带的 AdaBoost程序训练并检测目标