前言:
今天学习最常用的Adaboost算法结合Haar-like特征。该算法首先在人脸检测中得到广泛运用,而后也被用于其它有关目标检测中。adaboost 是一套机器学习的框架,根据给出的正样本和副样本训练一个用于识别正样本一类物体的模型。这个模型的本质就是分类器,又叫做级联(cascade)分类器。本文主要是学习使用OpenCV自带的adaboost+haar特征程序,并展示其用于人脸检测的效果,最后学习如何训练自己的分类器。
一、代码演示
OpenCV支持的目标检测的方法是利用样本的Haar特征进行的分类器训练,得到的级联boosted分类器(Cascade Classification)。
#include <opencv2/opencv.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main( )
{
String cascadeFilePath = "D:\\OpenCV3.1\\opencv\\build\\etc\\haarcascades\\haarcascade_frontalface_alt.xml"; //反斜杠’\‘表示转义字符,所以绝对路径需要如是表示
CascadeClassifier face_cascade;
if (!face_cascade.load(cascadeFilePath)) // 用load函数加载XML分类器文件
{
printf("could not load the haar data...\n");
return -1;
}
Mat src_img, gray_img;
src_img = imread("test16.jpg");
cvtColor(src_img, gray_img, COLOR_BGR2GRAY);
equalizeHist(gray_img, gray_img); //直方图均衡化
imshow("原图", src_img);
vector<Rect> faces; // faces是一个容器,用来接收检测到的人脸
face_cascade.detectMultiScale(gray_img, faces, 1.1, 2, 0, Size(10, 10), Size(30, 30)); //寻找人脸
for (auto t = 0; t < faces.size(); ++t)
{
rectangle(src_img, faces[t], Scalar(0, 0, 255), 2, 8, 0); // 用红色矩形框出人脸
}
namedWindow("检测结果", CV_WINDOW_AUTOSIZE);
imshow("检测结果", src_img);
waitKey(0);
return 0;
}
运行程序如下:
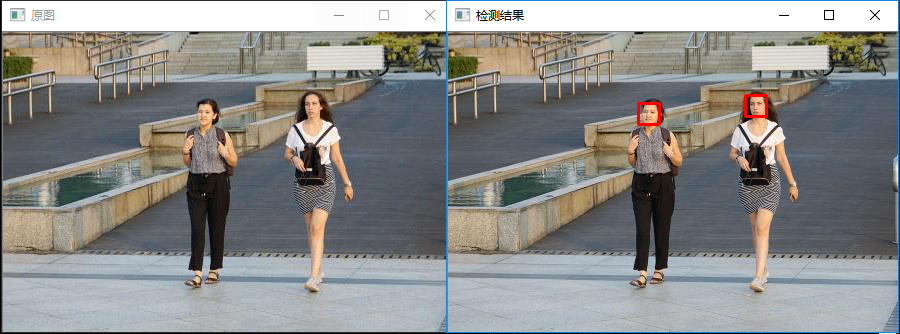
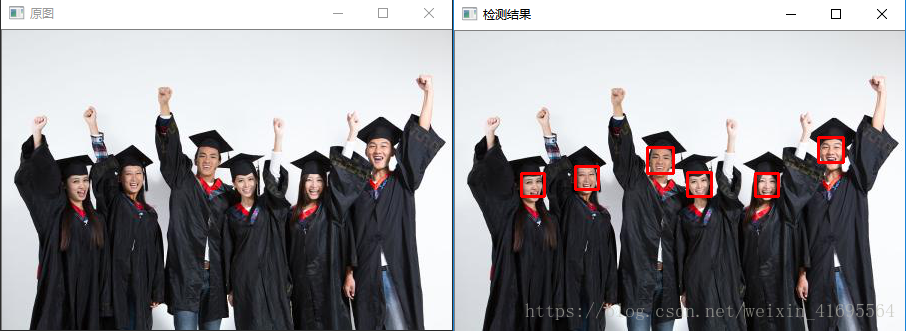
我们换张人多的照片试试:
注意事项:
(1)在xml文件的路径当中,我们用到了“\\”,为什么呢?且听我娓娓道来:
在Unix/Linux中,路径的分隔采用正斜杠"/",比如"/home/hutaow";而在Windows中,路径分隔采用反斜杠"\",比如"C:\Windows\System"。 有时我们会看到这样的路径写法,"C:\\Windows\\System",也就是用两个反斜杠来分隔路径,这种写法在网络应用或编程中经常看到,事实上,上面这个路径可以用"C:/Windows/System"来代替,不会出错。但是如果写成了"C:\Windows\System",那就可能会出现各种奇怪的错误了。至于上述问题出现的原因,要从字符串解析这方面来分析。学过编程的人都应该知道,在C里面,输出字符串时,如果想输出一个换行,那就要加上'\n'这个标志,类似的,输出一个TAB,就加上'\t',也就是说,反斜杠("\")这个符号会把跟在它后面的字符结合起来转义成其它字符。根据这个原理,如果想输出双引号('"'),就需要输入'\"',这样才会将包含了双引号的字符串正确的写入内存中。那么如果想输入一个反斜杠呢?很简单,只要敲'\\'就可以了。
看到这里或许有些人已经看出眉目了,如果"C:\Windows\System"这个路径字符串交给C编译器编译,实际写入内存的字符串并没有包含反斜杠"\",甚至紧跟在反斜杠后面的字母也一起被转义成了其它的字符,再次调用的话势必会出问题。
字符串解析不仅仅局限于C编译器,Java编译器、一些配置文件的解析、Web服务器等等,都会遇到对字符串进行解析的这个问题,由于传统的Windows采用的是单个斜杠的路径分隔形式,导致在对文件路径进行解析的时候可能发生不必要的错误,所以就出现了用双反斜杠"\\"分隔路径的形式。不管解析引擎是否将反斜杠解析成转义字符,最终在内存中得到的都是"\",结果也就不会出问题了。
二、相关函数API介绍
2.1 直方图均衡化
有什么,图像的视觉缺陷并不是它使用的强度值范围太窄,而是由于部分强度值的使用频率比其他强度值要高很多。例如,一副图像,它的中等灰度的强度值非常多,而较暗和较亮的像素值则非常稀少,通常认为,对所有的可用像素强度值都均衡使用,才是一副高质量的图像。这正是直方图均衡化这一概念背后的思想,也就是让图像的直方图尽可能的平稳。
OpenCV提供了一个简单好用的函数,用于直方图均衡化处理,这个 equalizeHist ()函数的声明如下:
C++: void equalizeHist(InputArray src, OutputArray dst)
在VS2015的提示为: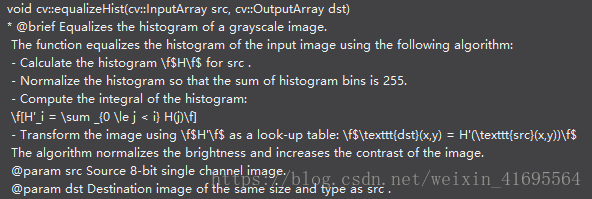
直方图均衡化是通过拉伸像素强度分布范围来增强图像对比度的一种方法,均衡化指的是把一个分布 (给定的直方图) 映射 到另一个分布 (一个更宽更统一的强度值分布),所以强度值分布会在整个范围内展开。其原理如下:
在一个完全均衡的直方图中,所有bins所包含的像素数量是相等的。这意味着50%像素的强度值小于128,25%像素的强度值小于64,依次类推。假设输入图像为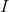
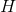
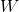
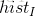
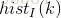
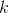
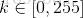
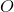
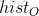
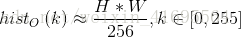
那么对于任意的灰度级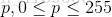
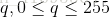
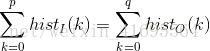
其中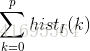
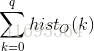
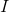
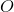
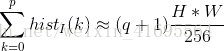
化简上式可得:
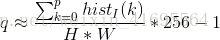
上式给出了一个从亮度级为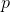
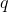

其中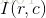
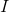


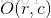
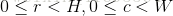
2.2 detectMultiScale函数
detectMultiScale函数,它可以检测出图片中所有的人脸,并将人脸用vector保存各个人脸的坐标、大小(用矩形表示),函数由分类器对象调用,其函数声明如下:
void detectMultiScale( InputArray image,
CV_OUT std::vector<Rect>& objects,
CV_OUT std::vector<int>& numDetections,
double scaleFactor=1.1,
int minNeighbors=3, int flags=0,
Size minSize=Size(),
Size maxSize=Size() );
在VS2015中的提示为:

其参数解释如下:
image:待检测图片,一般为灰度图像以加快检测速度;
objects:vector<Rect>类型,为输出量,表示被检测物体的矩形框向量组;
scaleFactor:表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%;一般设置为1.1
minNeighbor:表示构成检测目标的相邻矩形的最小个数( 默认值为3)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。
flags:要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,因此这些区域通常不会是人脸所在区域;
minSize和maxSize:用来限制得到的目标区域的范围。
detectMultiscale函数为多尺度多目标检测,多尺度:通常搜索目标的模板尺寸大小是固定的,但是不同图片大小不同,所以目标对象的大小也是不定的,所以多尺度即不断缩放图片大小(缩放到与模板匹配),通过模板滑动窗函数搜索匹配;同一副图片可能在不同尺度下都得到匹配值,所以多尺度检测函数detectMultiscale是多尺度合并的结果。 多目标:通过检测符合模板匹配对象,可得到多个目标,均输出到objects向量里面。
2.3 加载分类器

Haar特征分类器就是一个XML文件,该文件中会描述人体各个部位的Haar特征值。包括人脸、眼睛、嘴唇等等。其中:haarcascade_frontalface_alt.xml与haarcascade_frontalface_alt2.xml都是人脸识别的Haar特征分类器了。如下所示:
三、训练自己的分类器
在OpenCV中有许多相应的特征分类器,例如OpenCV自带的库里的haar特征就有人脸、人脸的器官和人的身体,如果我们想用这个分类器来检测别的物体,比如定义针对中国车牌的分类器等,那就要用haartraining这个工具训练自己的分类器。 那么这些分类器是怎么得到的?OpenCV中有两个函数可以训练分类器,即opencv_haartraining.exe和opencv_traincascade.exe,前者只能训练haar特征,后者可以用HAAR、LBP和HOG特征训练分类器。
具体的训练过程可以参考教程:
http://note.sonots.com/SciSoftware/haartraining.html、http://www.cnblogs.com/tornadomeet/archive/2012/03/28/2420936.html、
https://blog.csdn.net/lixue20141529/article/details/46407939、https://blog.csdn.net/wuxiaoyao12/article/details/39227189。
接下来简单介绍HAAR特征训练方法:
训练流程
取得分类器的步骤如下:
1.准备正、负样本;
2.使用Createsamples应用程序创建正样本集;
3.使用Haartraining应用程序训练,得到最终的分类器模型(即最终生成的xml文件)。
准备
工具准备,确保Createsamples、Haartraining和Performance应用程序可用。
样本准备,至少需要5千到1万个样本图片,这些图片必须是各种类型的且从公共资源中取得。正样本是要进行训练和识别的图片的背景。负样本是不含正样本图片的任何图像。比如风景图片等。
训练
样本准备完毕之后,通过Createsamples应用程序生成正、负样本集以及描述文件后,就可以进行训练了。训练步骤如下:
1.启动Haartraining应用程序;
2.创建新HAAR特征;
3.载入正、负样本;
4.训练并判断是否达到指定目标(识别率和误报率),如果达到则生成相应的xml文件,否则进行一些纠偏工作继续训练直到达到符合要求的结果。
5.Haartraining结束。
测试
通过Performance应用程序可以对刚才生成的特征文件进行测试。如果不需要详细的测试报告,可以选择实时测试的方式进行。如果需要详细的测试报告,那么必须载入准备阶段准备的正、负样本。