<Boosting,AdaBoost,Haar分类器>算法
1.Haar分类器方法
Haar分类器实际上是Boosting算法的一个应用,Haar分类器用到了Boosting算法中的AdaBoost算法,只是把AdaBoost算法训练出的强分类器进行了级联,并且在底层的特征提取中采用了高效率的矩形特征和积分图方法。
Haar分类器 =
Haar-like特征 + 积分图方法 + AdaBoost + 级联;

1.Haar-like特征
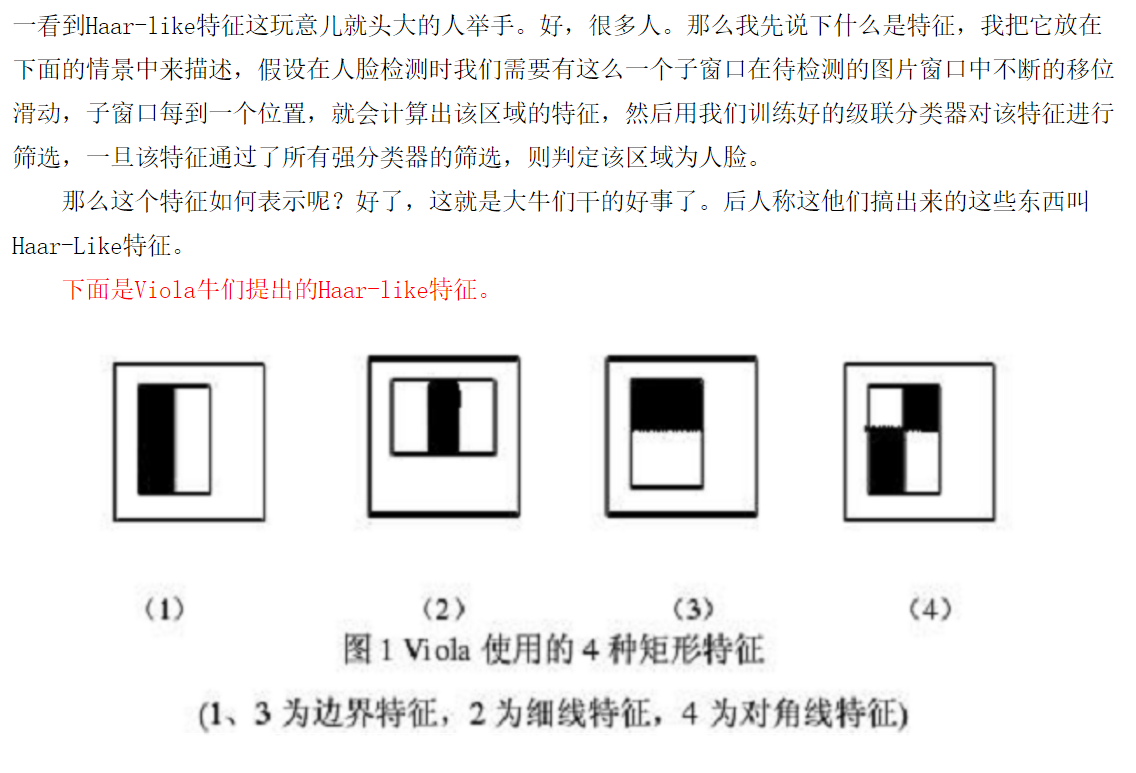
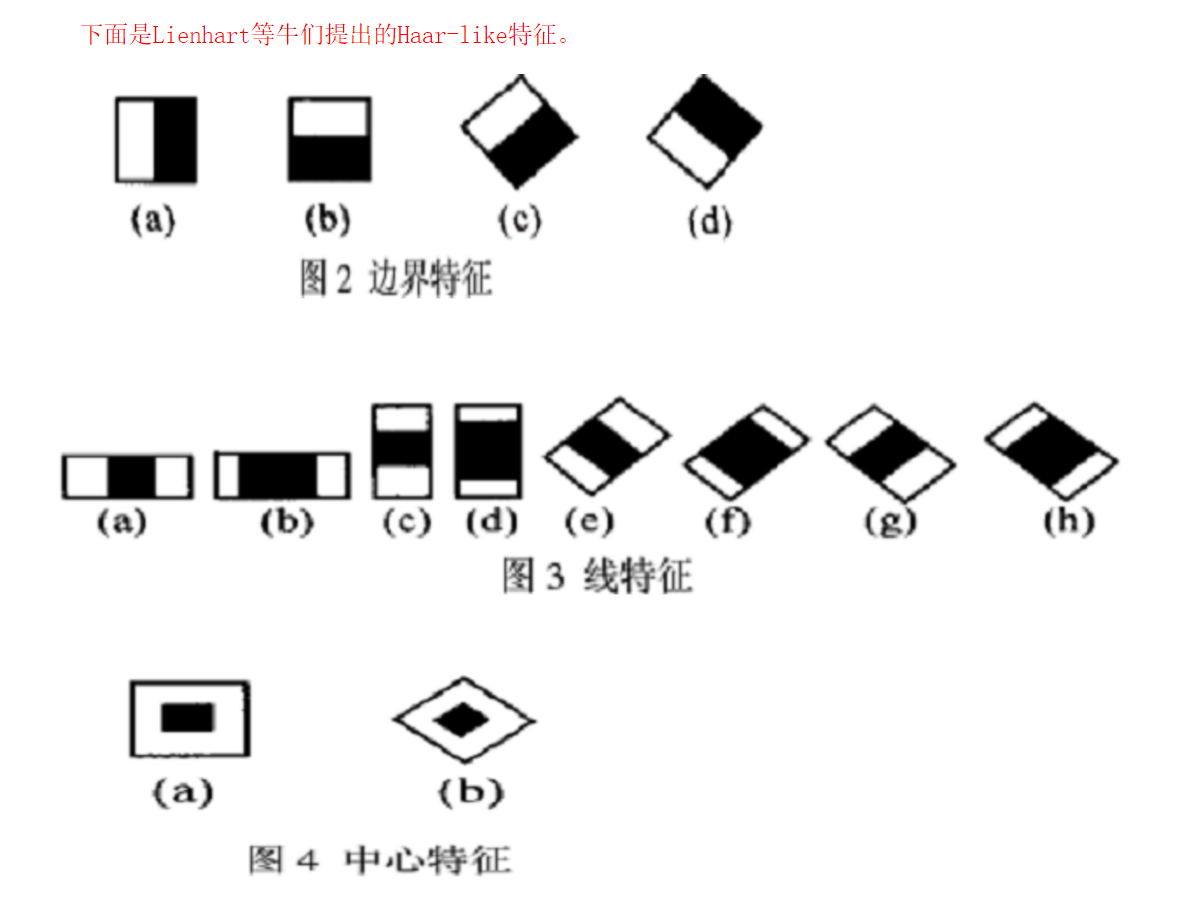
这些所谓的特征不就是一堆堆带条纹的矩形么,到底是干什么用的?我这样给出解释,将上面的任意一个矩形放到人脸区域上,然后,将白色区域的像素和减去黑色区域的像素和,得到的值我们暂且称之为人脸特征值,如果你把这个矩形放到一个非人脸区域,那么计算出的特征值应该和人脸特征值是不一样的,而且越不一样越好,所以这些方块的目的就是把人脸特征量化,以区分人脸和非人脸。
Haar-like特征值无非就是两个矩阵像素和的差
为了增加区分度,可以对多个矩形特征计算得到一个区分度更大的特征值,那么什么样的矩形特征怎么样的组合到一块可以更好的区分出人脸和非人脸呢,这就是AdaBoost算法要做的事了。
2.积分图是一个加速器
无论是训练还是检测,每遇到一个图片样本,每遇到一个子窗口图像,我们都面临着如何计算当前子图像特征值的问题,一个Haar-like特征在一个窗口中怎样排列能够更好的体现人脸的特征,这是未知的,所以才要训练,而训练之前我们只能通过排列组合穷举所有这样的特征,仅以Viola牛提出的最基本四个特征为例,在一个24×24size的窗口中任意排列至少可以产生数以10万计的特征,对这些特征求值的计算量是非常大的。
而积分图就是只遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大的提高了图像特征值计算的效率。

3.adaboost
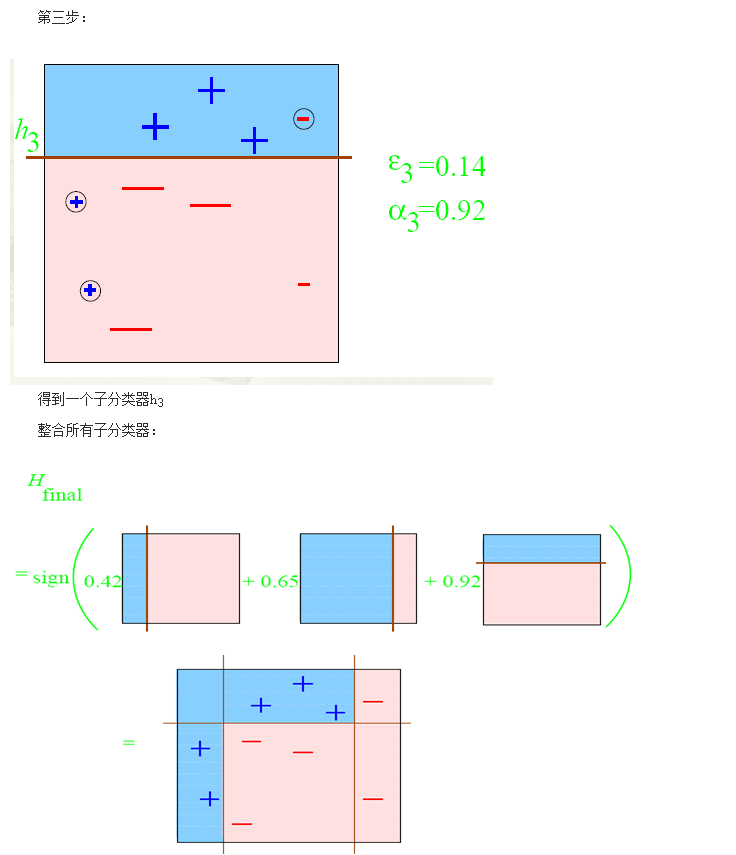

adaboost算法框架
1特征:矩形特征和积分图
将矩形作为人脸检测的特征向量,称为矩形特征。
2分类器:基于Adaboost提升算法
Adaboost算法是一种分类器算法,是由Freund和RobertE.Schapire在1995年提出的,其基本思想是利用大量的分类能力一般的简单分类器(weaker classifier)通过一定方法叠力(boost)起来,构成一个分类能力很强的强分类器。理论证明,只要每个简单分类器分类能力比随机猜测要好,当简单分类器个数趋向于无穷时,强分类器的错误率将趋于零。
Adaboost算法流程图
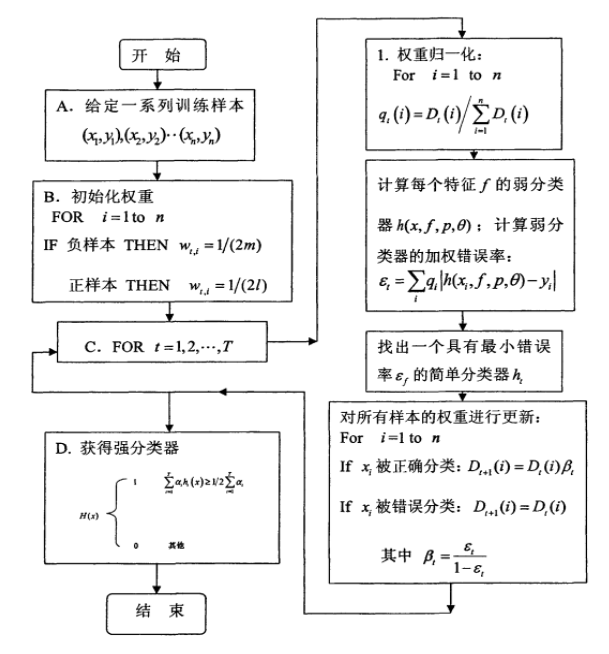

Haar+Adaboost人脸检测方法是使用每种Haar特征构成一个弱分类器
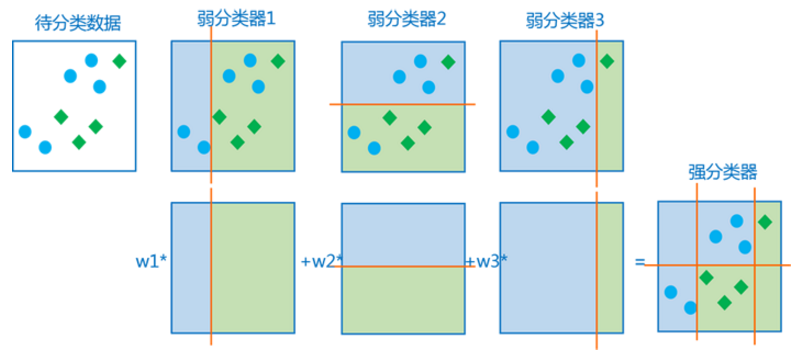
3层叠分类器
层叠分类器是一系列强分类器的组合,其中每一层都是Adaboos算法训练得到的一个强分类器。组成强分类器的弱分类器个数随着级数的增加而增加。每层的强分类器经过阈值(分类的界线,每个分类器带一个自己的阈值)调整,使得每一层都能让几乎全部的人脸样本通过,而拒绝很大一部分非人脸样本。
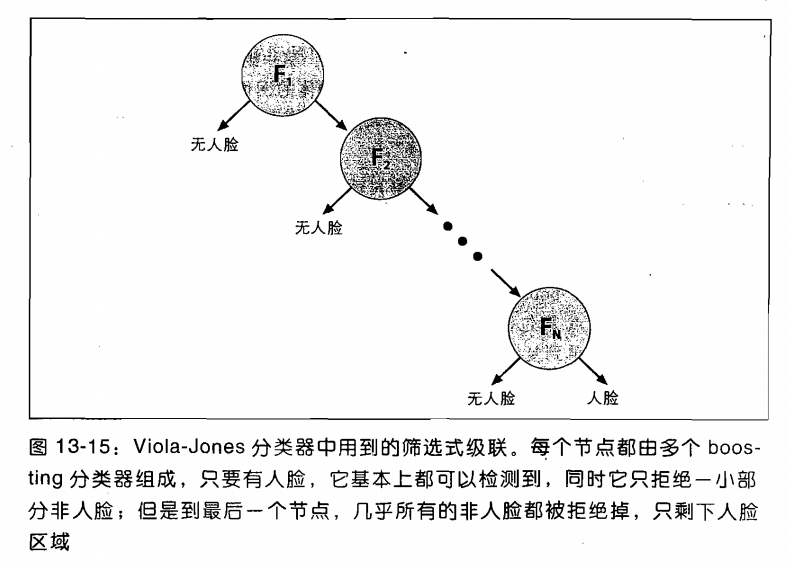
构造层叠分类器时要考虑两个平衡:
a.增加弱分类器个数在降低误识率的同时也增加了计算时间
b. 降低强分类器的阈值在增加检测率同时也增加了误识率
高检测率会导致高误识率,这是强分类阈值的划分导致的,要提高强分类器的检测率要降低阈值,要降低强分类器的误识率就要提高阈值
构造层叠分类器的每层强分类器时就是要找到上述两个平衡的平衡点。构造层叠分类器的cascade(瀑布)算法如下:

4适用范围

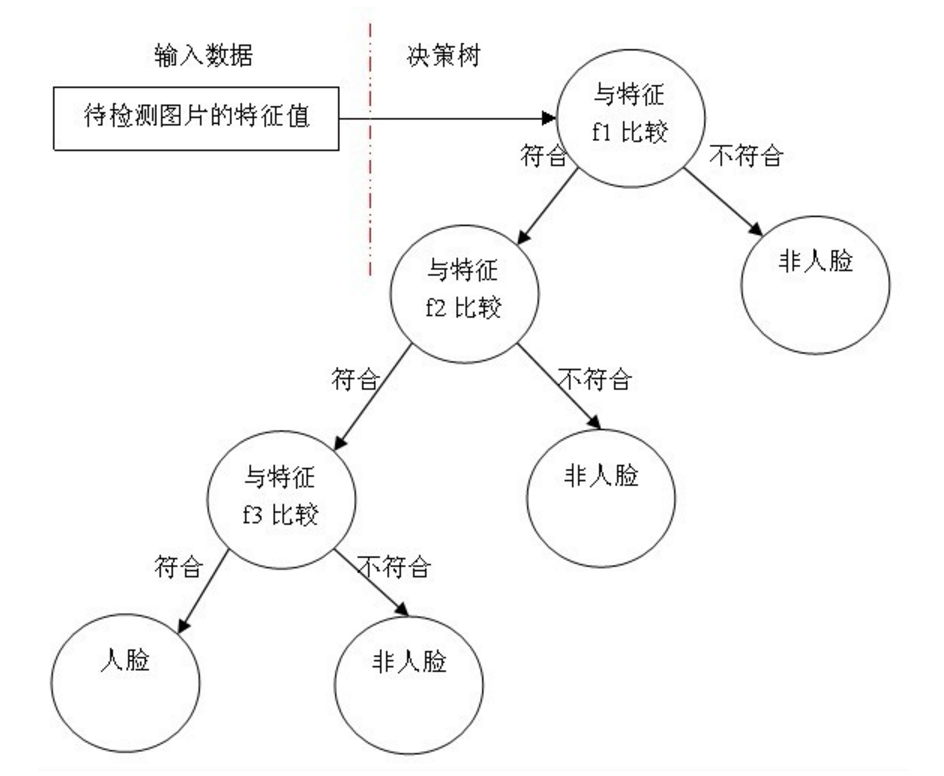
5决策树
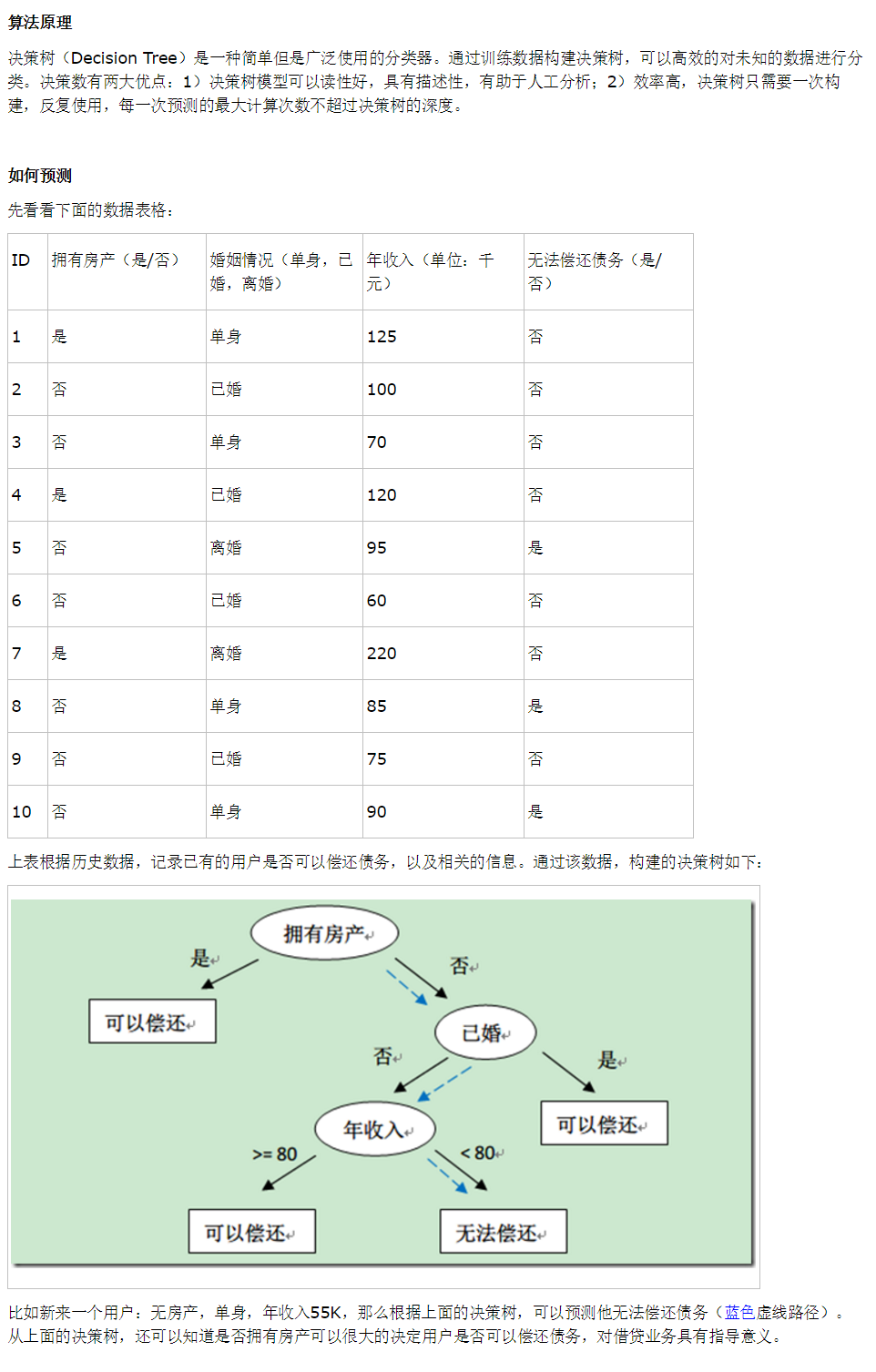
决策树(Decision Tree)是一种简单但是广泛使用的分类器。通过训练数据构建决策树,可以高效的对未知的数据进行分类。
决策树有两大优点:
1)决策树模型可以读性好,具有描述性,有助于人工分析;
2)效率高,决策树只需要一次构建,反复使用,每一次预测的最大计算次数不超过决策树的深度。

4.级联强分类器
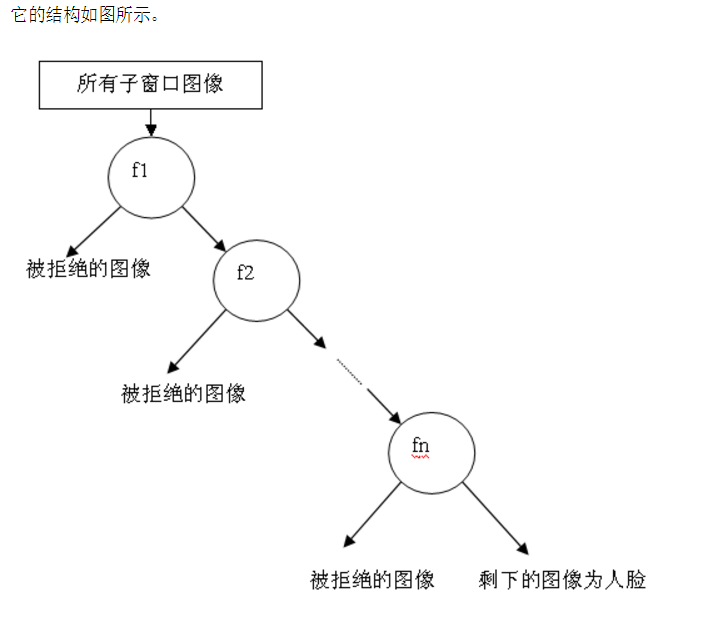
那么训练级联分类器的目的就是为了检测的时候,更加准确,这涉及到Haar分类器的另一个体系,检测体系,检测体系是以现实中的一幅大图片作为输入,然后对图片中进行多区域,多尺度的检测,所谓多区域,是要对图片划分多块,对每个块进行检测,由于训练的时候用的照片一般都是20*20左右的小图片,所以对于大的人脸,还需要进行多尺度的检测,多尺度检测机制一般有两种策略,一种是不改变搜索窗口的大小,而不断缩放图片,这种方法显然需要对每个缩放后的图片进行区域特征值的运算,效率不高,而另一种方法,是不断初始化搜索窗口size为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。在区域放大的过程中会出现同一个人脸被多次检测,这需要进行区域的合并,这里不作探讨。
无论哪一种搜索方法,都会为输入图片输出大量的子窗口图像,这些子窗口图像经过筛选式级联分类器会不断地被每一个节点筛选,抛弃或通过。
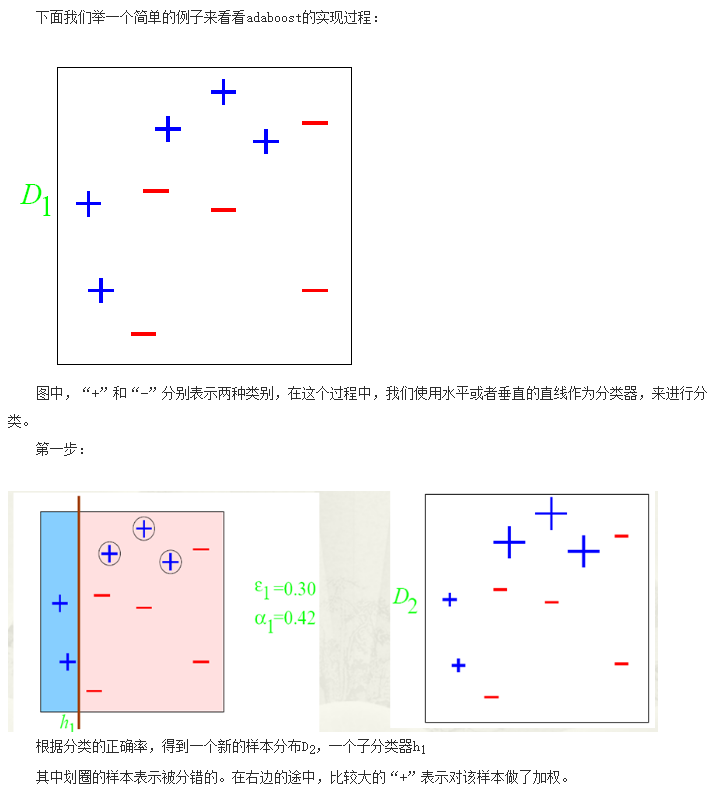
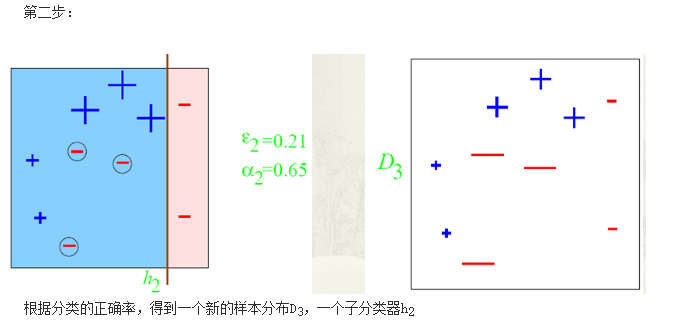
2.boosting
boosting中最基本的是adaboost,你要是弄清楚这个算法其他主要原理都差不多,只是实现手段或者说采用的数学公式不同。它是这样的:先对所有样本辅以一个抽样权重(一般开始的时候权重都一样即认为均匀分布),在此样本上训练一个分类器对样本分类,这样可以得到这个分类器的误差率,我们根据它的误差率赋以一个权重,大体是误差越大权重就越小,针对这次分错的样本我们增大它的抽样权重,这样训练的下一个分类器就会侧重这些分错的样本,然后有根据它的误差率又计算权重,就这样依次迭代,最后我们得到的强分类器就是多个弱分类器的加权和。我们可以看出性能好的分类器权重大一些,这就体现了boosting的精髓。
文档
http://pan.baidu.com/s/1nvEXmSp
参考资料