喝杯82年的Java压压惊
这次需要介绍的就是并查集
并查集的简单应用就是连通图—网络通信连接 等等
总之很重要
那么先说一下 这次的算法是
1. union-find (简单并查集)
2.quick-union (优化的并查集)
3.加权值quick-union(处理了2的最坏情况)
4.路径压缩加权值quick-union
如果只是想要一下算法,你可以直接跳到最后看第4个算法
接下来,我会套用一个比较形象的例子来说明并查集
在 <<啊哈算法>> 中有擒贼先擒王一说
就是一开始有n伙山贼, 他们各自为营 但是他们都是有野心的
第3伙强盗 打下了第5伙强盗 第5伙强盗的老大就是第3伙强盗
然后第7伙强盗一看想要让第5伙强盗成为伙伴 打完第5伙还得打第3伙强盗
还不如直接打第3伙 于是第7伙强盗就打赢了第3伙强盗 然后第3伙和第5伙都归第7伙了
…
接下来就是各自纷争 然后最后看还剩下了几伙强盗 并且每一伙强盗都是谁
union-find
故事大概就讲完了 很好理解吧. 其实算法也不难
让我们先看一下 API
加粗样式
public class UnionFind {
private int[] id; 存储这几伙强盗的逻辑关系 数组下标i代表第i伙强盗 值代表 他老大是谁
private int count; 表示一共有几个强盗团伙
public UnionFind(int N) 做初始化操作 N 代表一开始有几伙强盗
public int getCount() 获取强盗团伙的数量
public boolean connected(int p, int q) 判断 p 和 q 这两伙强盗 是不是一家的
public int find(int p) 找到第p伙强盗的老大
public void union(int p, int q) 联合两伙强盗
}
好了让我们一个一个方法来看 首先看构造函数
public UnionFind(int N) {
count = N;
id = new int[N];
for(int i = 0; i < N; i++) id[i] = i;
}
首先初始化的时候大家都是各自为营 所以强盗团伙的数量 就等于强盗数量本身 所以 count = N
然后new出这N伙强盗
最后一句话 大家各自为营 id[i] = i; 自己的老大就是自己
很简单把?来继续看
public int getCount() {
return count;
}
这个方法就不用介绍了吧?
public int find(int p) {
return id[p];
}
这个方法返回第P伙强盗的老大 id[p] 中存的值就是老大的下标
public boolean connected(int p, int q) {
return find(p) == find(q);
}
看看 两个的老大是不是同一个 也很简单把?
接下来就是最关键的一个方法了
联合 其实也不难
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
for(int i = 0; i < id.length; i++)
if(id[i] == pRoot) id[i] = qRoot;
count--;
}
两个参数 p 被 q 干掉了
前两句话 先分别找到p 和 q的老大
如果两个的老大都一样了 那说明同一伙强盗什么都不用做
否则的话p被q干掉
遍历数组 发现只要第i伙强盗的老大是p的老大也就是p所在的团伙 就让他们的老大变成q的
也就是说p所在的这个整个团伙就变成了q的
最后让团伙的数量减一;
完整代码
public class UnionFind {
private int[] id;
private int count;
public UnionFind(int N) {
count = N;
id = new int[N];
for(int i = 0; i < N; i++) id[i] = i;
}
public int getCount() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
return id[p];
}
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
for(int i = 0; i < id.length; i++)
if(id[i] == pRoot) id[i] = qRoot;
count--;
}
}
好了 让我们分析一下时间复杂度
最主要就是在这个union()的方法上
每一次的合并都需要遍历一次这个数组 合并n次就需要O(n^2)的时间复杂度
但是这个现实的应用可能处理的n是几百万 甚至几千万几亿的时候 这个时间复杂度的开销可能就有点问题了
通过上面的问题 我们需要优化一下算法
quick-union
其他方法不用变 只需要 修改 find() 和 union的两个方法就可以 首先看一下 find()
public int find(int p) {
while(p != id[p]) p = id[p];
return p;
}
迭代遍历的是什么? 只要id[p]表示第p伙强盗的 老大
只要老大不是自己就寻找真正的老大
要注意这里你可以有点误区 因为其实我们的union() 方法也改了 这次做的并不是统一老大
上一个版本 我们3干掉了5 3就是5的老大 然后7干掉了3 3的老大和5的老大都变成了7
这次我们是3干掉了5 3就是5的老大 7干掉了3 3的老大是7 5的老大还是3
所以7是5的老大的老大
所以先看一下 union()方法
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
id[pRoot] = qRoot;
count--;
}
那么有人问这你不就是把循环写到find里了吗?有什么区别.
区别就是 第一个真正的遍历了所有数组 而第二个 可能连接起来的也就是几个
其实可以表示成一颗树
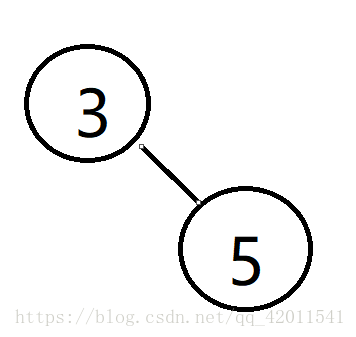
这里3干掉了5 就给3和5 连一条线 并且 ip[5] = 3;
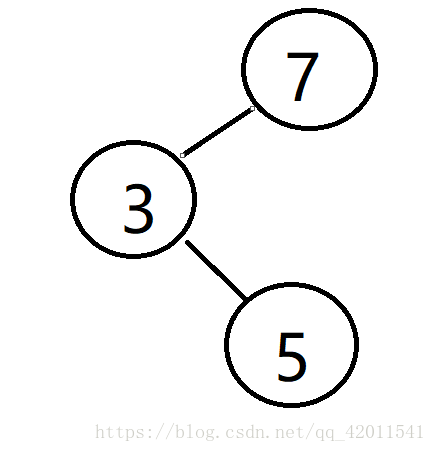
然后7干掉了3 就让3连向7 但是5还是连着3的 ip[3] = 7;
然后find查找5的时候 发现5的老大是3 然后p = 3 然后ip[3] != 3;说明 3还有老大 继续寻找3的老大
然后p=7; 发现7的老大就是7 所以出循环 并且返回7
这样的时间复杂度只取决于 这棵连接起来的树的高度
完整代码
public class QuickUnion {
private int[] id;
private int count;
publicQuickUnion(int N) {
count = N;
id = new int[N];
for(int i = 0; i < N; i++) id[i] = i;
}
public int getCount() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
while(p != id[p]) p = id[p];
return p;
}
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
id[pRoot] = qRoot;
count--;
}
}
去掉了循环 id[pRoot] = qRoot; 这句话只是表示 p的真正老大 是q 这样用find()方法就能找到
这里需要理解一下 不理解的先不要往下看
加权值quick-union
第二个方法已经快了很多
但是会出现这样一种情况
5伙强盗 分别0 1 2 3 4
然后联合的顺序是
0 1
0 2
0 3
0 4
这会造成什么
一开始 0被1先干掉了
然后 2要干0 发现 0有老大 1 然后2把0的老大1干掉了
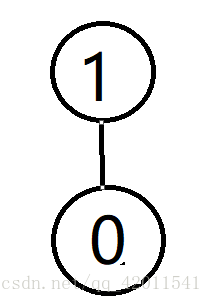
然后都是一样的
最后一个就不画了 3上面连个4
你会发现这样的情况遍历还是很多 树的高度呈线性增长
我们在实际的应用只关心两者联合在一起了 也就是两个团伙结盟在一起的问题
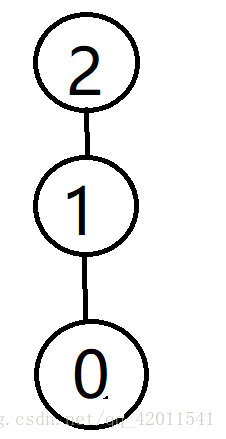
所以我们何不让小团伙依附于大团伙呢?
所以我们要在API里加一个成员变量
private int[] sz;
这个代表各个强盗有几个小弟
初始化构造器也要变了
类名为: public class WeightedQuickUnion
public WeightedQuickUnion(int N) {
count = N;
id = new int[N];
sz = new int[N];
for(int i = 0; i < N; i++) {
id[i] = i;
sz[i] = 1;
}
}
一开始 各自为营 小弟数量都是1 也就是自己
这次find()方法也不变
唯一改变的就是union()方法
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
if(sz[pRoot] < sz[qRoot]) { id[pRoot] = qRoot; sz[qRoot] += sz[pRoot]; }
else { id[qRoot] = pRoot; sz[pRoot] += sz[qRoot]; }
count--;
}
判断里也就是 如果p团伙的强盗数量 小于 q团伙强盗数量 就让p团伙的真正老大变成 q团伙的老大
并且q团伙的数量扩增 也就是 加上p老大的小弟数
否则 反之
你可以好好验证一下这样就解决了上一种的最坏情况
完整代码
public class WeightedQuickUnion {
private int[] id;
private int count;
private int[] sz;
public WeightedQuickUnion(int N) {
count = N;
id = new int[N];
sz = new int[N];
for(int i = 0; i < N; i++) {
id[i] = i;
sz[i] = 1;
}
}
public int getCount() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
while(p != id[p]) p = id[p];
return p;
}
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
if(sz[pRoot] < sz[qRoot]) { id[pRoot] = qRoot; sz[qRoot] += sz[pRoot]; }
else { id[qRoot] = pRoot; sz[pRoot] += sz[qRoot]; }
count--;
}
}
路径压缩加权值quick-union
上一种还有优化方式
你想一想 如果你是那个小弟 你有了个老大你的老大还有老大 那个真正的老大能让你的小弟还有小弟吗?
我都把你打掉了 你还有小弟这可不行
那我们能不能在找老大时候找到了以后都挨个告诉他们 真正的老大变成谁了呢 没问题
所以这就是路径压缩所在了
你想我们上一个版本去找老大的时候 还要一层一层的寻找 是不是很麻烦呢? 如果每一次找到了以后 小弟是老大就变成了真正的老大 那么我们每次去寻找的时候是不是只需要找一次
3是5的老大 然后 ip[5] = 3 来了个7干掉了3 ip[3] = 7; 再来了一个人需要打5的时候 去找找老大 找到3后 发现3存的是7 那我自己也存7 那下次再访问的时候是不是直接就是7了 就直接跳过3 如果还有更多的比如再来个9
9干掉了7 ip[7] = 9 继续找5的时候发现 我的老大7怎么存的是9 那我也是9 下下次 直接找7 是不是3和7都跳过了
所以这就是路径压缩的魅力所在
实现方法也简单 其他的不变修改find就行
public int find(int p) {
if(p != id[p]) id[p] = find(id[p]);
return id[p];
}
这里递归调用 层层返回
最后路径之上的所有强盗的老大 都是最后找到的那个老大了
是不是很Nice呢?
最终版代码 路径压缩加权值quick-union
public class UnionFind {
private int[] id;
private int count;
private int[] sz;
public UnionFind(int N) {
count = N;
id = new int[N];
sz = new int[N];
for(int i = 0; i < N; i++) {
id[i] = i;
sz[i] = 1;
}
}
public int getCount() {
return count;
}
public boolean connected(int p, int q) {
return find(p) == find(q);
}
public int find(int p) {
if (p != id[p]) id[p] = find(id[p]);
return id[p];
}
public void union(int p, int q){
int pRoot = find(p);
int qRoot = find(q);
if(pRoot == qRoot) return;
if(sz[pRoot] < sz[qRoot]) { id[pRoot] = qRoot; sz[qRoot] += sz[pRoot]; }
else { id[qRoot] = pRoot; sz[pRoot] += sz[qRoot]; }
count--;
}
}
最后的最后让我们分析一下时间复杂度
存在N伙强盗增长数量级(最坏情况)
算法 构造函数 union() find()
union-find算法 O(n) O(n) O(1)
quick-union算法 O(n) 树的高度 树的高度
加权quick-union算法 O(n) O(lgn) O(lgn)
路径压缩的加权quick-union算法 O(n) 非常接近O(1) 非常接近O(1)
理想情况 O(n) O(1) O(1)