版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/a987073381/article/details/52167019
昨天面试电话中的一道题,题目如下:
1、给你一个姓名的集合,查找你的名字是否在里面出现。
我的回答是用set,把集合中所有的姓名放到set集合中,直接用find查找我的姓名在这个集合里面是否出现。
2、追问,如果要搜索姓氏为叶的人,输入关键字叶,那么会出现所有姓为叶的人,应该如何设计?
当时的回答是,姓为key,名为value,存放到multimap中,使用multimap中的count函数统计key为叶的个数,然后用find函数找到第一个key为叶的指针,使用迭代器从该指针向后查找count个元素,判断这count个元素中是否有姓名为叶x的人。后来想想我的方法其实可以优化的,网上的思路基本上都是采用字典树,但仅针对英文单词。如果把字典树和我的在面试时候的方法结合起来就非常棒了(可惜当时没想到>_<)。
什么是字典树?
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。Trie的核心思想是空间换时间。利用
字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符。
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
- 每个节点的所有子节点包含的字符都不相同。
对于每个单词,如果直接去查找别的单词是否包括它,那么时间复杂度就是O(n^2),如果采用查找公共前缀,例如对于abcd,只用查找以a为前缀的节点假设为x,对于bcd,只用查找x节点中以b为前缀的节点,依次类推。
下面给出一种常见的英文字典树结构体设计:
#define MAX_CHILD 26
struct trie_node
{
trie_node()
{
count = 0;
for (int i = 0; i < MAX_CHILD; i++)
{
child[i] = NULL;
}
}
int count;//表示以该节点结束的单词的个数
trie_node *child[MAX_CHILD];//存放孩子节点指针的数组
};
对于每个节点都有指向26个英文字母的指针,如果字符串到某个节点(叶子节点)结束了,那么把该节点的count加一,代表从根节点到当前节点路径上出现的字母所组成的字符串出现过一次。如果不存在以该字符串为前缀的字符串,那么该叶子节点上的26个指针均为NULL。比如有字符串ae、b、 b、 bac、c、ca、ceh、ceb、cebg、cebg、f、fi。组成的字典树如下图:
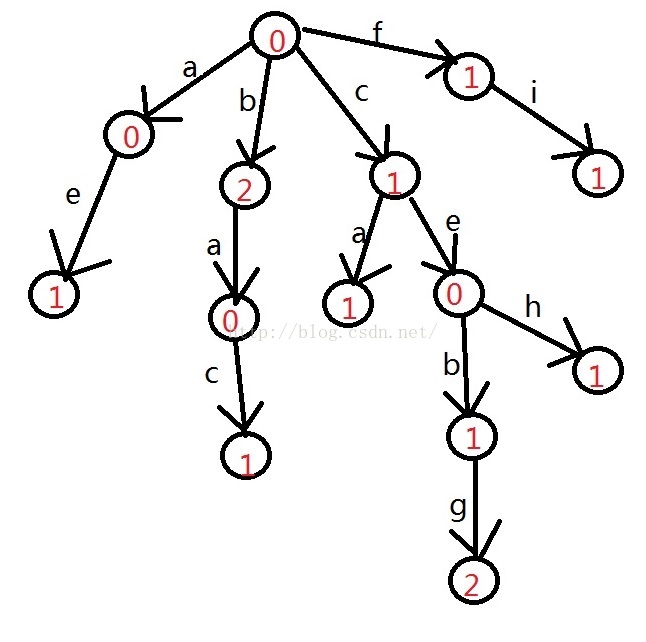
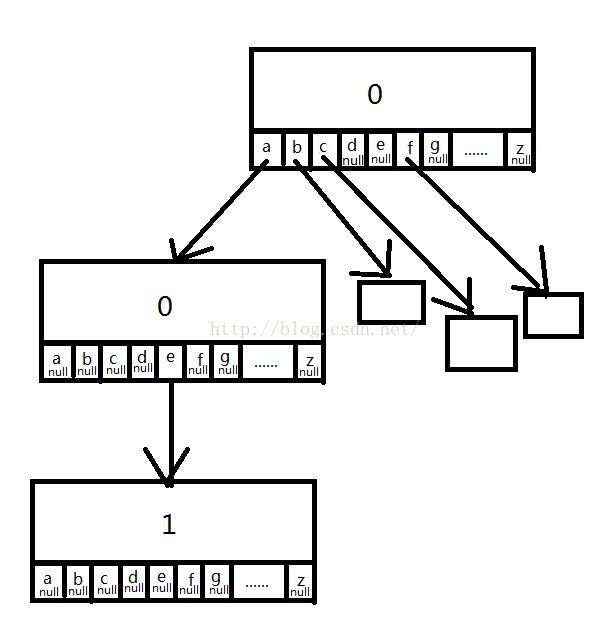
然而,存储中文的时候问题就来了,常见的中文汉字有5W个,如果按照上面的来设计,那么每个节点都要存放5W个节点的指针数组,这样会浪费很多空间,因为对于每个几点的5W个指针只用到了极少部分(其他都为NULL)。
我的设计思路:对于每个节点都有map(或hash_map),键值为前缀汉字(单个),实值为
指向后续汉字节点的指针。和英文字典树一样,从根节点到当前节点所经过的汉字连接起来成为某个
字符串。对于出现过的字符串,该字符串最后一个汉字所在节点的count加一。时间复杂度O((logn)^2)
例如中文字符串:数字、数据、数据集、数据库、数理化、测试、计量、记事本、计算机、计算器。那中文字典树如下:

例如中文字符串:数字、数据、数据集、数据库、数理化、测试、计量、记事本、计算机、计算器。那中文字典树如下:
使用map还是hash_map?
看情况而定,如果出现姓名特别多,而且普遍比较短(比如中文名一般是两三个汉字),用hash_map,这样整个树基本只要2~3层就能搞定,如果姓名很长,还是用map吧,毕竟每个汉字出现频率低,使用hash_map会浪费太多空间,得不偿失。
代码如下:
#include <string>
#include <map>
#include <vector>
#include <iostream>
#define CH_SIZE 3//汉字大小linux为3,win为2
using namespace std;
struct trie_node
{
trie_node()
{
count = 0;
}
int count;//表示以该汉字结束的字符串个数
map<string, trie_node *> child;//键值为当前汉字,实值为后面汉字节点的指针
};
class trie
{
public:
trie();
~trie();
void insert_str(string str);//插入字符串
trie_node *search_str(string str);//查询字符串
trie_node *search_str_pre(string str_pre);//查询字符串前缀
void delete_str(string str);//删除字符串
vector<string> get_str_pre(string str);//返回所有前缀为str的字符串
void clear();//清空
private:
void add_str(trie_node *root, string pre_str, vector<string> &ret); //递归添加以pre_str为前缀的字符串到ret集合
private:
struct trie_node *root;
};
trie::trie()
{
root = new trie_node();
}
trie::~trie()
{
}
//插入字符串
void trie::insert_str(string str)
{
if (root == NULL || str == "")
{
return ;
}
trie_node *cur_node = root;
for (int i = 0; i < str.size();)
{
string sub_str = str.substr(i, CH_SIZE);
map<string, trie_node *>::iterator iter = cur_node->child.find(sub_str);
if (iter == cur_node->child.end())//如果在map中没有找到则插入新节点
{
trie_node *tmp_node = new trie_node();
cur_node->child.insert(pair<string, trie_node *>(sub_str, tmp_node));
cur_node = tmp_node;
}
else//如果找到了value即为指向下一个节点的指针
{
cur_node = iter->second;
}
i = i + CH_SIZE ;
}
cur_node->count++;
}
//删除字符串
void trie::delete_str(string str)
{
trie_node *find_node = search_str(str);
if (find_node)
{
find_node->count--;
}
}
//查询字符串前缀
trie_node * trie::search_str_pre(string str)
{
if (str == "")
{
return root;
}
if (NULL == root )
{
return NULL;
}
trie_node *cur_node = root;
int i;
for ( i = 0; i < str.size(); )
{
string sub_str = str.substr(i, CH_SIZE);
map<string, trie_node *>::iterator iter = cur_node->child.find(sub_str);
if (iter == cur_node->child.end())
{
return NULL;
}
else
{
cur_node = iter->second;
}
i = i + CH_SIZE;
}
if (i == str.size())
{
return cur_node;
}
else
{
return NULL;
}
}
//查询字符串
trie_node * trie::search_str(string str)
{
trie_node * find_pre_node = search_str_pre(str);
if (find_pre_node != NULL)
{
if (find_pre_node->count == 0)
{
return NULL;
}
else
{
return find_pre_node;
}
}
}
//清空
void trie::clear()
{
vector<trie_node *> que;
que.push_back(root);
while (!que.empty())
{
for (map<string, trie_node *>::iterator iter = root->child.begin(); iter != root->child.end(); iter++)
{
que.push_back(iter->second);
}
trie_node *del_node = que.front();
que.pop_back();
delete del_node;
}
}
//递归添加以pre_str为前缀的字符串到ret集合
void trie::add_str(trie_node *root, string pre_str, vector<string> &ret)
{
for (map<string, trie_node *>::iterator iter = root->child.begin(); iter != root->child.end(); iter++)
{
add_str(iter->second, pre_str + iter->first, ret);
}
if (root->count != 0)
{
ret.push_back(pre_str);
}
}
//返回所有前缀为str的字符串
vector<string> trie::get_str_pre(string str)
{
vector<string> ret;
trie_node *find_node = search_str_pre(str);
if (find_node != NULL)
{
add_str(find_node, str, ret);
}
return ret;
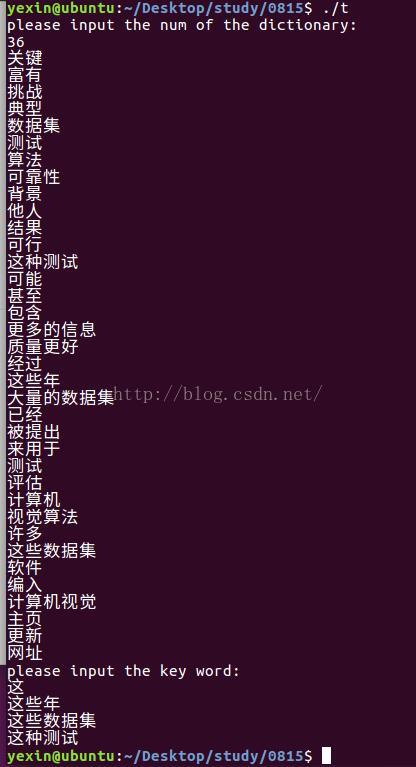
} int main()
{
trie t;
int n;
string str;
vector<string> ret;
cout << "please input the num of the dictionary:" << endl;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> str;
t.insert_str(str);
}
cout << "please input the key word:" << endl;
cin >> str;
ret = t.get_str_pre(str);
for (vector<string>::iterator iter = ret.begin(); iter != ret.end(); iter++)
{
cout << *iter << endl;
}
return 0;
}
参考: