一、背景与环境搭建
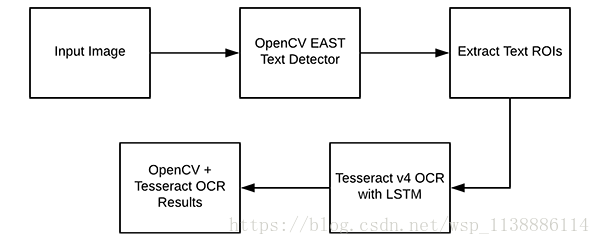
OpenCV的文本识别流程:
- OpenCV EAST 文本检测器执行文本检测,
- 我们提取出每个文本 ROI 并将其输入 Tesseract,从而构建完整的 OpenCV OCR 流程!
- 环境搭建
Tesseract (v4) 最新版本支持基于深度学习的 OCR,准确率显著提高。底层的 OCR 引擎使用的是一种循环神经网络(RNN)——LSTM 网络。
pip install tesseract
pip install opencv-python
pip install pillow
pip install pytesseract
pip install imutils
安装 tesseract-ocr 下载地址:https://digi.bib.uni-mannheim.de/tesseract/
由于 tesseract-ocr安装地址(如下左):
故添加环境变量(如上右):C:\Program Files (x86)\Tesseract-OCR
故需改 pytesseract.py :tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract.exe'

- OpenCV OCR 文本识别流程图
我们使用 OpenCV 的 EAST 文本检测器来检测图像中的文本。- EAST 文本检测器将提供文本 ROI 的边界框坐标。
- 我们将提取每个文本 ROI,将其输入到 Tesseract v4 的 LSTM 深度学习文本识别算法。LSTM 的输出将提供实际 OCR 结果。
- 我们将在输出图像上绘制 OpenCV OCR 结果。
整个过程中使用到的 Tesseract 命令必须在 pytesseract 库下调用。在调用 tessarct 库时,我们需要提供大量 flag。(tessarct --help)
最重要的三个 flag 是 -l、–oem 和 --ism。
$ tesseract --help-oem
OCR Engine modes:
0 Legacy engine only.
1 Neural nets LSTM engine only.
2 Legacy + LSTM engines.
3 Default, based on what is available.
-l flag 控制输入文本的语言,本教程示例中使用的是 eng(英语),在这里你可以看到 Tesseract 支持的所有语言:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
–oem(OCR 引擎模式)控制 Tesseract 使用的算法类型。执行以下命令即可看到可用的 OCR 引擎模式:
–psm 控制 Tesseract 使用的自动页面分割模式:
$ tesseract --help-psm
Page segmentation modes:
0 Orientation and script detection (OSD) only.
1 Automatic page segmentation with OSD.
2 Automatic page segmentation, but no OSD, or OCR.
3 Fully automatic page segmentation, but no OSD. (Default)
4 Assume a single column of text of variable sizes.
5 Assume a single uniform block of vertically aligned text.
6 Assume a single uniform block of text.
7 Treat the image as a single text line.
8 Treat the image as a single word.
9 Treat the image as a single word in a circle.
10 Treat the image as a single character.
11 Sparse text. Find as much text as possible in no particular order.
12 Sparse text with OSD.
13 Raw line. Treat the image as a single text line,
bypassing hacks that are Tesseract-specific.
对文本 ROI 执行 OCR,我发现模式 6 和 7 性能较好,但是如果你对大量文本执行 OCR,那么你可以试试 3(默认模式)。
如果你得到的 OCR 结果不正确,那么我强烈推荐调整 --psm,它可以对你的输出 OCR 结果产生极大的影响。
$ tree --dirsfirst
.
├── images
│ ├── example_01.jpg
│ ├── example_02.jpg
│ ├── example_03.jpg
│ ├── example_04.jpg
│ └── example_05.jpg
├── frozen_east_text_detection.pb
└── text_recognition.py
1 directory, 7 files
项目包含一个目录和两个重要文件:
- images/:该目录包含六个含有场景文本的测试图像。我们将使用这些图像进行 OpenCV OCR 操作。
- frozen_east_text_detection.pb:EAST 文本检测器。该 CNN 已经经过预训练,可用于文本检测。它是由 OpenCV 提供的,你也可以在「Downloads」部分下载它。
- text_recognition.py:我们的 OCR 脚本。我们将逐行 review 该脚本。它使用 EAST 文本检测器找到图像中的文本区域,然后利用 Tesseract v4 执行文本识别。
- EAST 文本检测器生成两个变量:
scores:文本区域的概率。
geometry:文本区域的边界框位置。
关于脚本参数
- 我们的脚本需要两个命令行参数:
–image:输入图像的路径。
–east:预训练 EAST 文本检测器的路径。 - 下列命令行参数是可选的:
–min-confidence:检测到的文本区域的最小概率。
–width:图像输入 EAST 文本检测器之前需要重新调整的宽度,我们的检测器要求宽度是 32 的倍数。
–height:与宽度类似。检测器要求调整后的高度是 32 的倍数。
–padding:添加到每个 ROI 边框的(可选)填充数量。如果你发现 OCR 结果不正确,那么你可以尝试 0.05、0.10 等值。
二、文本检测与识别
from imutils.object_detection import non_max_suppression
import numpy as np
import pytesseract
import argparse
import cv2
"""
EAST 文本检测器生成两个变量:
scores:文本区域的概率。
geometry:文本区域的边界框位置。
"""
def decode_predictions(scores, geometry):
# grab the number of rows and columns from the scores volume, then
# initialize our set of bounding box rectangles and corresponding
# confidence scores
(numRows, numCols) = scores.shape[2:4]
rects = []
confidences = []
for y in range(0, numRows):
#提取分数(概率),然后是几何数据,用于导出围绕文本的潜在边界框坐标
scoresData = scores[0, 0, y]
xData0 = geometry[0, 0, y]
xData1 = geometry[0, 1, y]
xData2 = geometry[0, 2, y]
xData3 = geometry[0, 3, y]
anglesData = geometry[0, 4, y]
for x in range(0, numCols): # 循环列数
if scoresData[x] < args["min_confidence"]: # 忽略低置信度
continue
# 计算偏移因子作为我们的结果特征
# maps will be 4x smaller than the input image
(offsetX, offsetY) = (x * 4.0, y * 4.0)
# 提取预测的旋转角并计算
angle = anglesData[x]
cos = np.cos(angle)
sin = np.sin(angle)
# 使用几何体来推导bounding box的宽度和高度
h = xData0[x] + xData2[x]
w = xData1[x] + xData3[x]
# 计算文本预测bounding box的起始和结束(x,y)坐标
endX = int(offsetX + (cos * xData1[x]) + (sin * xData2[x]))
endY = int(offsetY - (sin * xData1[x]) + (cos * xData2[x]))
startX = int(endX - w)
startY = int(endY - h)
# 将 bounding box坐标和概率得分添加到各自的列表中
rects.append((startX, startY, endX, endY))
confidences.append(scoresData[x])
return (rects, confidences) #返回bounding boxes的元组及其置信度
"""
构造参数分析器并解析参数
"""
ap = argparse.ArgumentParser()
ap.add_argument("-i", "--image", type=str,
help="path to input image")
ap.add_argument("-east", "--east", type=str,
help="path to input EAST text detector")
ap.add_argument("-c", "--min-confidence", type=float, default=0.5,
help="minimum probability required to inspect a region")
ap.add_argument("-w", "--width", type=int, default=320,
help="nearest multiple of 32 for resized width")
ap.add_argument("-e", "--height", type=int, default=320,
help="nearest multiple of 32 for resized height")
ap.add_argument("-p", "--padding", type=float, default=0.0,
help="amount of padding to add to each border of ROI")
args = vars(ap.parse_args())
"""
加载+预处理我们的图像并初始化关键变量
"""
image = cv2.imread(args["image"])
orig = image.copy()
(origH, origW) = image.shape[:2]
# 设置新的宽度和高度,然后确定宽度和高度的变化比。
(newW, newH) = (args["width"], args["height"])
rW = origW / float(newW)
rH = origH / float(newH)
# 调整图像大小并获取新的图像尺寸
image = cv2.resize(image, (newW, newH))
(H, W) = image.shape[:2]
"""
EAST文本检测器:
EAST检测器模型定义两个输出层名称:
第一个是输出概率,
第二个可以用来导出文本的边框坐标
"""
layerNames = [
"feature_fusion/Conv_7/Sigmoid",
"feature_fusion/concat_3"]
# 加载预训练的EAST文本检测器
print("[INFO] loading EAST text detector...")
net = cv2.dnn.readNet(args["east"])
"""
至少 OpenCV 3.4.2 才能调用 cv2.dnn.readNet
见证【奇迹】的第一步:确定文本位置
从图像中构建一个BLOB(团),然后执行模型的前向传递以获得两个输出层集合。
"""
blob = cv2.dnn.blobFromImage(image, 1.0, (W, H),
(123.68, 116.78, 103.94), swapRB=True, crop=False)
net.setInput(blob)
(scores, geometry) = net.forward(layerNames)
# 解码预测,然后应用非极大值抑制来抑制弱重叠的 bounding boxes(包围盒)。
(rects, confidences) = decode_predictions(scores, geometry)
boxes = non_max_suppression(np.array(rects), probs=confidences)
'''
识别文本
遍历边界框,并处理结果
'''
results = []
for (startX, startY, endX, endY) in boxes: # 遍历 bounding box
# 根据相应比例缩放 bounding box 坐标
startX = int(startX * rW)
startY = int(startY * rH)
endX = int(endX * rW)
endY = int(endY * rH)
# 填充边界框:同时计算x和y方向的增量
dX = int((endX - startX) * args["padding"])
dY = int((endY - startY) * args["padding"])
# 将边界分别填充到边界框的每一侧。
startX = max(0, startX - dX)
startY = max(0, startY - dY)
endX = min(origW, endX + (dX * 2))
endY = min(origH, endY + (dY * 2))
# 提取被填充的 ROI
roi = orig[startY:endY, startX:endX]
# 设置 Tesseract config 参数(英语、LSTM神经网络和单行文本)。
config = ("-l eng --oem 1 --psm 7")
text = pytesseract.image_to_string(roi, config=config)
# 将边界框坐标和OCR文本添加到结果列表中
results.append(((startX, startY, endX, endY), text))
"""
输出结果:
"""
# 将结果框的坐标从上到下排序
results = sorted(results, key=lambda r:r[0][1])
for ((startX, startY, endX, endY), text) in results:
print("OCR TEXT")
print("========")
print("{}\n".format(text))
# 剥离非ASCII文本,利用OpenCV的图像绘制文本,然后绘制文本和bounding box边框
text = "".join([c if ord(c) < 128 else "" for c in text]).strip()
output = orig.copy()
cv2.rectangle(output, (startX, startY), (endX, endY),
(0, 0, 255), 2)
cv2.putText(output, text, (startX, startY - 20),
cv2.FONT_HERSHEY_SIMPLEX, 1.2, (0, 0, 255), 3)
cv2.imshow("Text Detection", output)
cv2.waitKey(0)
cv2.destroyAllWindows()
python text_recognition.py --east frozen_east_text_detection.pb \
--image images/example_01.jpg
[INFO] loading EAST text detector...
OCR TEXT
========
OH OK
关于代码运行:Anaconda | python3.6 | OpenCV_tf
我的OpenCV有关的库全都安装在OpenCV_tf 环境中,故我需要在此环境运行代码。
权重及完整代码:https://download.csdn.net/download/wsp_1138886114/10724564
该代码运行可能会因为依赖而报错,请安装完整依赖
关于文本位置确定:请查看https://www.pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/

特别鸣谢
https://www.pyimagesearch.com/2018/09/17/opencv-ocr-and-text-recognition-with-tesseract/