通过学习周志华老师的机器学习一书,对集成学习做一些笔记。
集成学习(ensemble learning)是通过构建并结合多个学习器来完成学习任务的,因此有写文章中也称其为多分类器系统(multi-classifier system)或者是委员会学习(committee-based learning)。
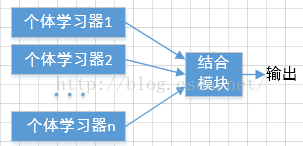
下图是集成学习的一般结构,将一组“个体学习器”(individual learner)用一些何理的策略结合起来,这些个体学习器可以是各种弱分类器,例如决策树算法,BP神经网络等。若所有的个体学习器是同种类型的,则称这样的集成是“同质”的(homogeneous),此时的学习器也可以称作是“基学习器”(base learner),相应的学习算法则为“基学习算法”(base learning algorithm).若集成中的个体学习器包含不同的学习器,则称这样的集成为“异质”的(heterogenous),此时的个体学习器则被称为是“组件学习器”(component learner)也可以被直接称为个体学习器。
弱学习器:指泛化性能略优于随机猜测的学习器;例如在二分类问题中精确度略高于50%的分类器。
集成学习的很多研究都是针对弱学习器进行的,通过集成多个学习器进行结合,通常可以获得比单一学习器显著优越的泛化性能。但是这也不是确定的,有些情况下也会产生不理想的分类效果,例如下图,test1,2,3,指三种测试用例,h1,2,3指不同的弱分类器,如果集成学习的结果通过投票法产生,即“少数服从多数”,那么在下图1中,h1,2,3的正确率均为66.6%,集成后的效果为100%,此时集成学习是有效的。但是图2中三个分类器对三个测试用例的判别无差别,集成之后的性能也没有得到提升,此时集成是不起作用的。图3中每个分类器的精确度只有33。3%,集成后的结果则变得更差。因此如果要获得好的集成结果,那么就要求个体学习器应该“好而不同”,即个体学习器要有一定的“准确性”,不能太差的同时又要有多样性,如图1中三个分类器。

- 通过二分类问题作简要分析,标签y属于{-1,1},真是函数f,假设个体分类器的错误率为\[\varepsilon \],即对每个基分类器\[{h_i}\],有
- 假设集成通过上述投票法结合T各个体分类器,即有一半的个体分类器正确,则集成分类正确:
- 如果假设基分类器的错误率是相互独立的,那么根据Hoeffding不等式可得,集成的错误率为
- 由上式可得随着集成中个体分类器T的数目的增大,集成的错误率则呈指数级下降,最终趋于零。


