1 集成学习概述
1.1 概述
在一些数据挖掘竞赛中,后期我们需要对多个模型进行融合以提高效果时,常常会用Bagging,Boosting,Stacking等这几个框架算法,他们不是一种算法,而是一种集成模型的框架。
集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高。目前接触较多的集成学习主要有2种:基于Boosting的和基于Bagging,前者的代表算法有Adaboost、GBDT、XGBOOST、后者的代表算法主要是随机森林。
1.2 主要思想
集成学习的主要思想是利用一定的手段学习出多个分类器,而且这多个分类器要求是弱分类器,然后将多个分类器进行组合公共预测。核心思想就是如何训练处多个弱分类器以及如何将这些弱分类器进行组合。
1.3 弱分类器选择
一般采用弱分类器的原因在于将误差进行均衡,因为一旦某个分类器太强了就会造成后面的结果受其影响太大,严重的会导致后面的分类器无法进行分类。常用的弱分类器可以采用误差率小于0.5的,比如说逻辑回归、SVM、神经网络。
1.4 分类器的生成
可以采用随机选取数据进行分类器的训练,也可以采用不断的调整错误分类的训练数据的权重生成新的分类器。
1.5 多个弱分类区如何组合
基本分类器之间的整合方式,一般有简单多数投票、权重投票,贝叶斯投票,基于D-S证据理论的整合,基于不同的特征子集的整合。
下面就来分别详细讲述Bagging,Boosting,Stcking这三个框架算法。这里我们只做原理上的讲解,不做数学上推导。
2 Bagging
2.1 基本思想
Bagging是对多个弱学习器独立进行学习的方法。bagging方法bootstrap aggregating的缩写。
Bootstrap是指从n个训练样本中随机选取n个,允许重复,生成与原始的训练样本集有些许差异的样本集的方法。
Aggregation:聚集、集成。
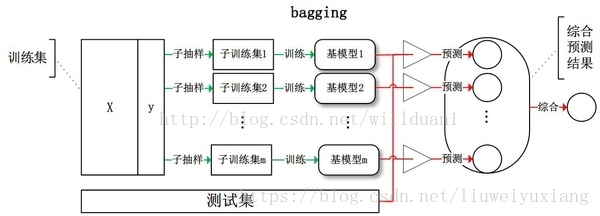
给定一个大小为n的训练集 D,Bagging算法从中均匀、有放回地选出 m个大小为 n’ 的子集Di,作为新的训练集。在这 m个训练集上使用分类、回归等算法,则可得到 m个模型,再通过取平均值、取多数票等方法综合产生预测结果,即可得到Bagging的结果。
Bagging思想的代表算法是随机森林,下面就以随机森林为代表进行讲解。
2.2 随机森林算法概述
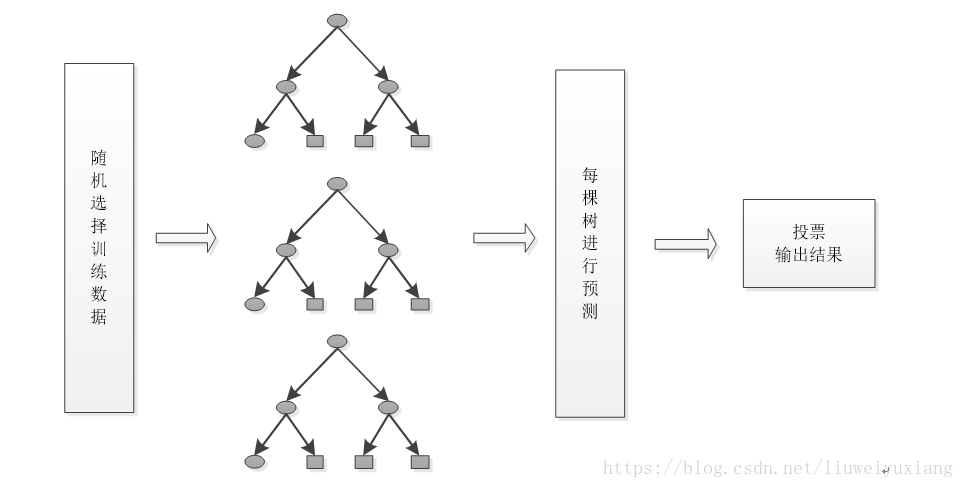
随机森林算法是上世纪八十年代Breiman等人提出来的,其基本思想就是构造很多棵决策树,形成一个森林,然后用这些决策树共同决策输出类别是什么。随机森林算法及在构建单一决策树的基础上的,同时是单一决策树算法的延伸和改进。在整个随机森林算法的过程中,有两个随机过程,第一个就是输入数据是随机的从整体的训练数据中选取一部分作为一棵决策树的构建,而且是有放回的选取;第二个就是每棵决策树的构建所需的特征是从整体的特征集随机的选取的,这两个随机过程使得随机森林很大程度上避免了过拟合现象的出现。
2.3 随机森林算法具体的过程:
1、从训练数据中选取n个数据作为训练数据输入,一般情况下n是远小于整体的训练数据N的,这样就会造成有一部分数据是无法被去到的,这部分数据称为袋外数据,可以使用袋外数据做误差估计。
2、选取了输入的训练数据的之后,需要构建决策树,具体方法是每一个分裂结点从整体的特征集M中选取m个特征构建,一般情况下m远小于M。
3、在构造每棵决策树的过程中,按照选取最小的基尼指数进行分裂节点的选取进行决策树的构建。决策树的其他结点都采取相同的分裂规则进行构建,直到该节点的所有训练样例都属于同一类或者达到树的最大深度。
4、 重复第2步和第3步多次,每一次输入数据对应一颗决策树,这样就得到了随机森林,可以用来对预测数据进行决策。
5、 输入的训练数据选择好了,多棵决策树也构建好了,对待预测数据进行预测,比如说输入一个待预测数据,然后多棵决策树同时进行决策,最后采用多数投票的方式进行类别的决策。
2.4 随机森林算法图示
2.5 随机森林算法的注意点:
1、 在构建决策树的过程中是不需要剪枝的。
2、 整个森林的树的数量和每棵树的特征需要人为进行设定。
3、 构建决策树的时候分裂节点的选择是依据最小基尼系数的。
2.6 随机森林有很多的优点:
a. 在数据集上表现良好,两个随机性的引入,使得随机森林不容易陷入过拟合。
b. 在当前的很多数据集上,相对其他算法有着很大的优势,两个随机性的引入,使得随机森林具有很好的抗噪声能力。
c. 它能够处理很高维度(feature很多)的数据,并且不用做特征选择,对数据集的适应能力强:既能处理离散型数据,也能处理连续型数据,数据集无需规范化。
d. 在创建随机森林的时候,对generlization error使用的是无偏估计。
e. 训练速度快,可以得到变量重要性排序。
f. 在训练过程中,能够检测到feature间的互相影响。
g 容易做成并行化方法。
h. 实现比较简单。
3 Boosting
Boosting是对多个弱学习器依次进行学习的方法。Boosting有很多种,比如AdaBoost(Adaptive Boosting), Gradient Boosting等,这里以AdaBoost为典型讲解一下。
Boosting也是集合了多个决策树,但是Boosting的每棵树是顺序生成的,每一棵树都依赖于前一颗树。顺序运行会导致运行速度慢。
3.1 AdaBoosting基本思想
首先介绍下AdaBoost的思想,而不去阐述Boosting决策树的构建构建方法和数学公式推导。
AdaBoost,运用了迭代的思想。每一轮都加入一个新训练一个预测函数,直到达到一个设定的足够小的误差率,或者达到最大的树的数目。
①开始的时候每一个训练样本都被赋予一个初始权重,用所有样本训练第一个预测函数。计算该预测函数的误差,然后利用该误差计算训练的预测函数的权重系数(该预测函数在最终的预测函数中的权重,此处忽略公式)。接着利用误差更新样本权重(此处忽略公式)。如果样本被错误预测,权重会增加;如果样本被正确预测,权重会减少。通过权重的变化,使下轮的训练器对错误样本的判断效果更好。
②以后每轮训练一个预测函数。根据最后得出的预测函数的误差计算新训练的预测函数在最终预测中的权重,然后更新样本的权重。权重更新之后,所有样本用于下轮的训练。
③如此迭代,直到误差小于某个值或者达到最大树数。
这里涉及到两个权重,每轮新训练的预测函数在最终预测函数中所占的权重和样本下一轮训练中的权重。这两个权重都是关于 每轮训练的预测函数产生的误差 的函数。
3.2 Adaboost的算法流程:
假设训练数据集为T={(X1,Y1),(X2,Y2),(X3,Y3),(X4,Y4),(X5,Y5)} 其中Yi={-1,1}
1、初始化训练数据的分布
训练数据的权重分布为D={W11,W12,W13,W14,W15},其中W1i=1/N。即平均分配。
2、选择基本分类器
这里选择最简单的线性分类器y=aX+b ,分类器选定之后,最小化分类误差可以求得参数。
3、计算分类器的系数和更新数据权重
误差率也可以求出来为e1.同时可以求出这个分类器的系数。基本的Adaboost给出的系数计算公式为
上面求出的
就是这个分类器在最终的分类器中的权重。然后更新训练数据的权重分布。如果样本被错误预测,权重会增加;如果样本被正确预测,权重会减少。
总而言之:Boosting每次迭代循环都是利用所有的训练样本,每次迭代都会训练出一个分类器,根据这个分类器的误差率计算出该分类器的在最终的分类器中的权重,并且更新训练样本的权重。这就使得每次迭代训练出的分类器都依赖上一次的分类器,串行速度慢。
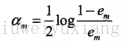
3.3 Boosting最终的组合弱分类器方式:
通过加法模型将弱分类器进行线性组合,比如AdaBoost通过加权多数表决的方式,即增大错误率小的分类器的权值,同时减小错误率较大的分类器的权值。
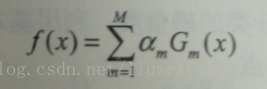
4 Stacking
以Adaboost为代表的Boosting和以RandomForest为代表的Bagging,它们在集成学习中属于同源集成(homogenous ensembles)方法。Stacking 也就是Stacked Generalization(SG),翻译为堆栈泛化的方法(属于异源集成(heterogenous ensembles)的典型代表)。
4.1 堆栈泛化(Stacked Generalization)的概念
作为一个在kaggle比赛中高分选手常用的技术,SG在部分情况下,甚至可以让错误率相比当前最好的方法进一步降低30%之多。
以下图为例,简单介绍一个什么是SG:
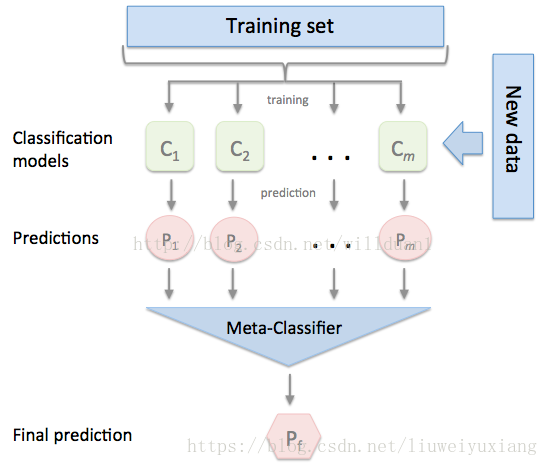
① 将训练集分为3部分,分别用于让3个基分类器(Base-leaner)进行学习和拟合
② 将3个基分类器预测得到的结果作为下一层分类器(Meta-learner)的输入
③ 将下一层分类器得到的结果作为最终的预测结果
这个模型的特点就是通过使用第一阶段(level 0)的预测作为下一层预测的特征,比起相互独立的预测模型能够有**更强的非线性表述能力,降低泛化误差。**它的目标是同时降低机器学习模型的Bias-Variance。
总而言之,堆栈泛化就是集成学习(Ensemble learning)中Aggregation方法进一步泛化的结果, 是通过Meta-Learner来取代Bagging和Boosting的Voting/Averaging来综合降低Bias和Variance的方法。 譬如: Voting可以通过kNN来实现, weighted voting可以通过softmax(Logistic Regression), 而Averaging可以通过线性回归来实现。
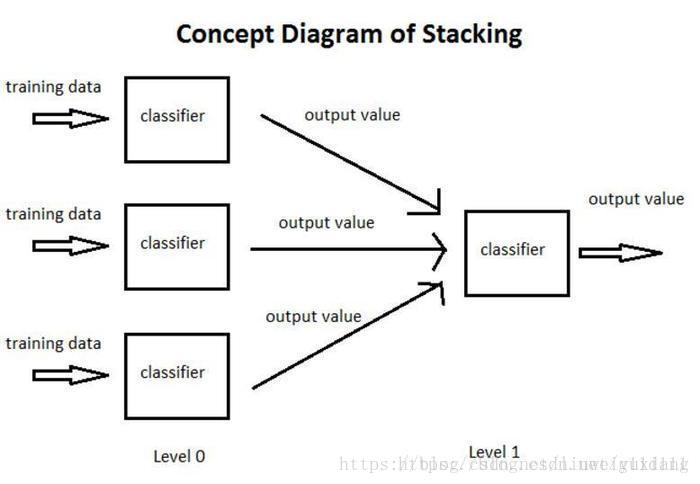
4.2 Stacking 集成思想
将训练好的所有基模型对整个训练集进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
4.3 mlxtend库的Stacking 三种集成方式实现
下面我们介绍一款功能强大的stacking利器,mlxtend库,它可以很快地完成对sklearn模型地stacking。
主要有以下几种使用方法吧:
I. 最基本的使用方法,即使用前面分类器产生的特征输出作为最后总的meta-classifier的输入数据
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
II. 另一种使用第一层基本分类器产生的类别概率值作为meta-classfier的输入
这种情况下需要将StackingClassifier的参数设置为 use_probas=True。如果将参数设置为 average_probas=True,那么这些基分类器对每一个类别产生的概率值会被平均,否则会拼接。
例如有两个基分类器产生的概率输出为:
classifier 1: [0.2, 0.5, 0.3]
classifier 2: [0.3, 0.4, 0.4]
1) average = True :
产生的meta-feature 为:[0.25, 0.45, 0.35]
2) average = False:
产生的meta-feature为:[0.2, 0.5, 0.3, 0.3, 0.4, 0.4]
from sklearn import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
use_probas=True,
average_probas=False,
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = model_selection.cross_val_score(clf, X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label))
III. 另外一种方法是对训练基中的特征维度进行操作的
这次不是给每一个基分类器全部的特征,而是给不同的基分类器分不同的特征,即比如基分类器1训练前半部分特征,基分类器2训练后半部分特征(可以通过sklearn 的pipelines 实现)。最终通过StackingClassifier组合起来。
from sklearn.datasets import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data
y = iris.target
pipe1 = make_pipeline(ColumnSelector(cols=(0, 2)),
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1, 2, 3)),
LogisticRegression())
sclf = StackingClassifier(classifiers=[pipe1, pipe2],
meta_classifier=LogisticRegression())
sclf.fit(X, y)
4.4 StackingClassifier 使用API及参数解析:
StackingClassifier(classifiers, meta_classifier, use_probas=False, average_probas=False, verbose=0, use_features_in_secondary=False)
参数:
classifiers : 基分类器,数组形式,[cl1, cl2, cl3]. 每个基分类器的属性被存储在类属性 self.clfs_.
meta_classifier : 目标分类器,即将前面分类器合起来的分类器
use_probas : bool (default: False) ,如果设置为True, 那么目标分类器的输入就是前面分类输出的类别概率值而不是类别标签
average_probas : bool (default: False),用来设置上一个参数当使用概率值输出的时候是否使用平均值。
verbose : int, optional (default=0)。用来控制使用过程中的日志输出,当 verbose = 0时,什么也不输出, verbose = 1,输出回归器的序号和名字。verbose = 2,输出详细的参数信息。verbose > 2, 自动将verbose设置为小于2的,verbose -2.
use_features_in_secondary : bool (default: False). 如果设置为True,那么最终的目标分类器就被基分类器产生的数据和最初的数据集同时训练。如果设置为False,最终的分类器只会使用基分类器产生的数据训练。
属性:
clfs_ : 每个基分类器的属性,list, shape 为 [n_classifiers]。
meta_clf_ : 最终目标分类器的属性
方法:
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True),如果是使用sklearn的GridSearch方法,那么返回分类器的各项参数。
predict(X)
predict_proba(X)
score(X, y, sample_weight=None), 对于给定数据集和给定label,返回评价accuracy
set_params(params),设置分类器的参数,params的设置方法和sklearn的格式一样
5 一个例子说明集成学习为什么可以提高准确率
上面提到了同源集成经典方法中的Voting和Averaging,这里以分类任务为例,对Voting进行说明,那么什么是Voting呢?
Voting,顾名思义,就是投票的意思,假设我们的测试集有10个样本,正确的情况应该都是1:
我们有3个正确率为70%的二分类器记为A,B,C。你可以将这些分类器视为伪随机数产生器,即以70%的概率产生”1”,30%的概率产生”0”。
下面我们可以根据从众原理(少数服从多数),来解释采用集成学习的方法是如何让正确率从70%提高到将近79%的。
All three are correct 0.7 * 0.7 * 0.7 = 0.3429
Two are correct 0.7 * 0.7 * 0.3 + 0.7 * 0.3 * 0.7 + 0.3 * 0.7 * 0.7 = 0.4409
Two are wrong 0.3 * 0.3 * 0.7 + 0.3 * 0.7 * 0.3 + 0.7 * 0.3 * 0.3 = 0.189
All three are wrong 0.3 * 0.3 * 0.3 = 0.027
我们看到,除了都预测为正的34,29%外,还有44.09%的概率(2正1负,根据上面的原则,认为结果为正)认为结果为正。大部分投票集成会使最终的准确率变成78%左右(0.3429 + 0.4409 = 0.7838)。
注意,这里面的每个基分类器的权值都认为是一样的。