一类问题:对于一个整数n,将n进行质因数分解
算法1:
根据定义直接枚举,直接给出代码:
void Decom(int n) {
int i;
vector<int> res;
for(i = 2; i <= n; i++) {
while(n%i == 0) {
res.push_back(i);
n /= i;
}
}
for(i = 0; i < res.size()-1; i++) printf("%d*", res[i]);
printf("%d\n", res.back());
}算法2:
考虑到若有
n % i == 0,则必有n % (n/i) == 0,所以可以仅枚举
void Decom(int n) {
int i;
vector<int> res;
for(i = 2; i*i <= n; i++) {
while(n%i == 0) {
res.push_back(i);
n /= i;
}
}
for(i = 0; i < res.size()-1; i++) printf("%d*", res[i]);
printf("%d\n", res.back());
}Pollard-Rho算法:
该算法需要使用的大素数判定的
Miller-Rabin算法戳这里
对于一个大整数n,我们取任意一个数
对于满足
其中判断素数就使用
那么我们怎样不断取得
x[i]=(x[i-1]*x[i-1]%n+c)%n推算出来,其中
代码如下:
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
const int MAXN = 65;
long long x[MAXN];
vector<long long> f;
long long multi(long long a, long long b, long long p) {
long long ans = 0;
while(b) {
if(b&1LL) ans = (ans+a)%p;
a = (a+a)%p;
b >>= 1;
}
return ans;
}
long long qpow(long long a, long long b, long long p) {
long long ans = 1;
while(b) {
if(b&1LL) ans = multi(ans, a, p);
a = multi(a, a, p);
b >>= 1;
}
return ans;
}
bool Miller_Rabin(long long n) {
if(n == 2) return true;
int s = 20, i, t = 0;
long long u = n-1;
while(!(u & 1)) {
t++;
u >>= 1;
}
while(s--) {
long long a = rand()%(n-2)+2;
x[0] = qpow(a, u, n);
for(i = 1; i <= t; i++) {
x[i] = multi(x[i-1], x[i-1], n);
if(x[i] == 1 && x[i-1] != 1 && x[i-1] != n-1) return false;
}
if(x[t] != 1) return false;
}
return true;
}
long long gcd(long long a, long long b) {
return b ? gcd(b, a%b) : a;
}
long long Pollard_Rho(long long n, int c) {
long long i = 1, k = 2, x = rand()%(n-1)+1, y = x;
while(true) {
i++;
x = (multi(x, x, n) + c)%n;
long long p = gcd((y-x+n)%n, n);
if(p != 1 && p != n) return p;
if(y == x) return n;
if(i == k) {
y = x;
k <<= 1;
}
}
}
void find(long long n, int c) {
if(n == 1) return;
if(Miller_Rabin(n)) {
f.push_back(n);
return;
}
long long p = n, k = c;
while(p >= n) p = Pollard_Rho(p, c--);
find(p, k);
find(n/p, k);
}
若仍然不能理解,戳这里
以下可以略去:
关于此算法名称的来历:
由于该算法在推算
如下图:
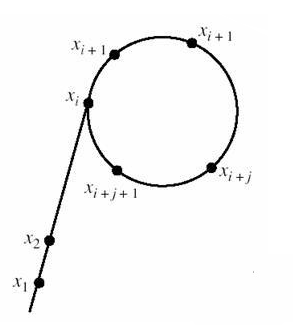
然后发明者叫做