针对SVM这个概念,先问几个问题,再一一回答。
1. 什么是SVM?为什么叫SVM?
SVM是一种适用性很强并且很有用的机器学习模型,他能完成线性和非线性的分类与回归问题,还可以用于异常值检测问题中。 SVM尤其适合处理关于中小型数据集的复杂分类问题。
2. SVM的原理是什么?
下一篇博客再讨论。
3. SVM有什么好?
4. SVM 要怎么用?
用ScikitLearn
线性SVM分类
SVM分类器是在寻找需要被分开的两类中间的最宽的一条道(large margin classification),右图两条虚线所示。加入更多远离这条街道的数据点并不会影响决策的边界线,这条边界线是由在街道边上的数据点(向量)所决定的(or “supported”)。这些数据点被称为是 support vectors(图中大圆所圈)。
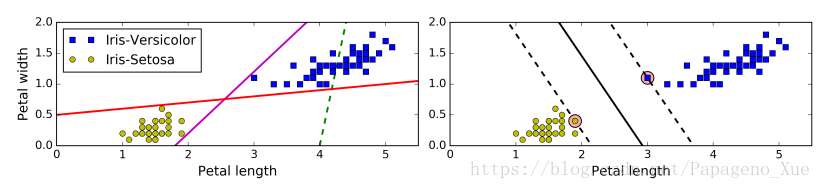
SVM 对数据scale敏感,要记得做feature scaling.
hard margin classification : 要求所有的数据点都被正确的分类并且不在划出的街道上面,被称为 hard margin classification.
- hard margin classification 有两个主要问题:
1) 只能用于线性可分的数据上;
2)对于异常值特别敏感 。
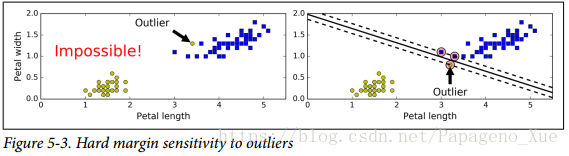
左图不可能完成一个hard margin classification, 右图可以但是决策对异常值过于敏感。
soft margin classification: 因此为了避免这些问题,我们需要做一个妥协,就是在保证街道尽可能宽的前提下同时尽可能减少 margin violations(就是数据点落在街道上甚至是错误的一边)。
在Scikit-Learn 中我们可以通过控制超参数 C 来调节这种妥协程度, C 越小得到的街道就越宽,因此可能的margin violation也就更多.
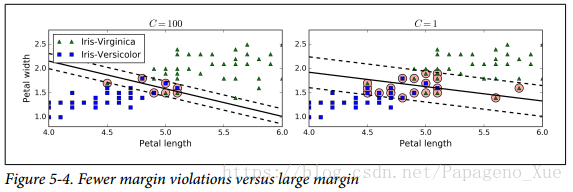
这意味着,如果SVM分类时候过拟合了,你可以通过降低
C来对模型进行正则化。这样有希望增加模型的泛化能力。
非线性SVM分类
并非所有的数据集都是线性可分的;因此,通过类似于多项式拟合的思想来引入更多的多项式 poly 组合作为新的feature,可以将一个非线性分类问题转化为线性问题。
- [注意]:这里也埋下一个问题,在多项式拟合时候也会遇到,如果数据集的结构过于复杂,只引入少数的几阶多项式并不能很好的拟合,引入更高的阶数又会使得feature过多,模型训练会变慢。
在Scikit-Learn里面很容易实现,使用sklearn.preprocessing.中的 PolynomialFeatures来直接生成多项式的features, 举个例子,代码如下:
import numpy as np
from sklearn.preprocessing import PolynomialFeatures
X = np.arange(6.0).reshape(2,-1)
print('Original data:\n',X)
# 假设考虑到二阶
poly_features = PolynomialFeatures(degree=2)
X_poly = poly_features.fit_transform(X)
print('New data with poly features:\n', X_poly )Original data:
[[0. 1. 2.]
[3. 4. 5.]]
New data with poly features:
[[ 1. 0. 1. 2. 0. 0. 0. 1. 2. 4.]
[ 1. 3. 4. 5. 9. 12. 15. 16. 20. 25.]]Kernel Method
你可以把数据进行PolyNonialFeatures之后再做线性SVM,LinearSVC(C=??, loss='hinge'); 你也可以直接用SVM设置其核方法为kernel=poly 如下,
from sklearn.svm import SVC
# X, y = 训练数据和labels
poly_kernel_svm_clf = SVC(kernel='poly', degree=3, coef0=1, C=5)
poly_kernel_svm_clf.fit(X, y)当然你可以有其他kernel的选择, 也就是其他变着法子的新feature产生方法,比如 kernel='rbf', Gaussian Radial Basis Fucntion(RBF).
就是把数据点通过上述高斯函数做个映射
- 可以将数据的每个点都作为landmark (即令 ),这样就会得到 个新的feature, m是数据样例的个数。
- 很明显,训练集很大的话,这个做法不太合适;
- 可以作为超参数用于调节控制模型, 作为正则化调节的话, 越大,高斯峰越尖锐,每个数据样例的影响力变小,那么决策边界会变得更尖锐陡峭;因此,如果过拟合了的话,就减小 值。
Scikit-Learn使用例子,
from sklearn.svm import SVC
# X, y = 训练数据和labels
rbf_kernel_svm_clf = SVC(kernel='rbf', gamma=5, C=0.1)
rbf_kernel_svm_clf.fit(X, y)
- RBF 的数学意义是? 似然函数? 数据样本集往高斯分布上做投影???
- RBF的弊端是什么? 如果数据点关于landmark对称,会出现什么现象?
计算复杂度的问题
LinearSVC是基于liblinear库的,其中对线性SVM应用了优化过的算法。它并不支持kernel参数, 训练的时间复杂度几乎是线性依赖于样本数和feature数的: . (可以通过控制误差超参数 来提高计算的精度,在scikitLearn里参数是tol.)SVC class基于libsvm, 支持核方法,训练的时间复杂度通常在 和 之间。 这可以看出来,如果 比较大的话,这个方法就会比较糟糕了! 但是注意到,它对feature的scale性质比较好,是线性依赖,所以,如果再是稀疏的fearure数据集的话(feature中只有少数的非零值,想想One-Hot编码或者是数字手写体的数据吧),那么对feature的依赖基本是线性依赖于平均的非零feature数!

SVM 回归问题
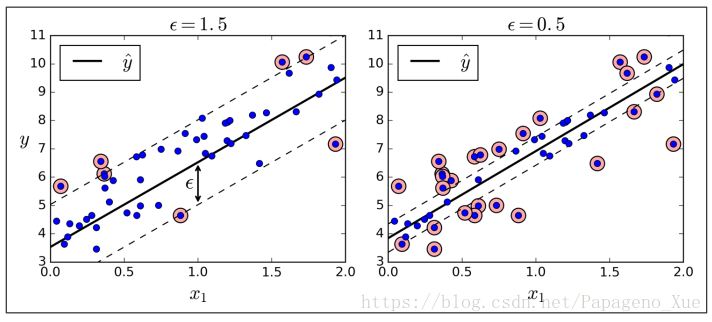
SVM算法的适用性是很强的,它不仅可以用于线性和非线性的分类问题,还可以完成线性和非线性的回归问题。
SVM回归的思路和SVM分类是反过来的,前面提到分类时候是想在最小化分类误差的情况下找到一条最宽的街道把两个类别分开,而回归问题变成了:尽可能找到一条街道把所有的数据都囊括进去,也就是尽可能减少数据点跑出这个街道,并且街道要尽可能地窄。 街道的宽度有超参数 控制。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import LinearSVR, SVR
x = np.linspace(-3.,3.0,30)
noise = np.random.rand(len(x))
y = x**2
y_input = y + 0.1*noise*(1.0-x) + 1.0*noise
X = x.reshape(-1,1)
svm_poly_reg = SVR(kernel='poly',degree=2, C=1, epsilon=0.5)
svm_poly_reg.fit(X, y_input)
y_pred = svm_poly_reg.predict(X)
plt.scatter(x,y_input, label=r'y_inut')
plt.plot(x,y_pred+svm_poly_reg.epsilon,'k--',x,y_pred-svm_poly_reg.epsilon,'k--', label=r'street')
plt.plot(x,y_pred,'r-', label=r'y_prediction')
plt.legend()
plt.show()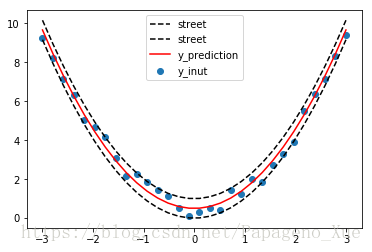
参考书籍: Hands on Machine Learning with Scikit-Learn and TensorFlow, A. Geron.