支持向量机(SVM)
标签(空格分隔): 监督学习
@author : [email protected]
@time : 2016-07-31
在看这篇文章之间,建议先看一下感知机,这样可以更好的看懂SVM。
一、最大间隔分类器
在之前的文章感知机中提到过,感知机模型对应于特征空间中将实例划分为正负两类的分离超平面,但是,感知机的解却不止一个。对同一个数据集而言,可以计算得到很多的感知机模型,不同的感知机的 训练误差 都是一样的,都为0。
那么,这些训练误差都为0的感知机模型中,如何针对当前数据集,选择一个最好的感知机模型呢?现在就需要考虑模型的 泛化误差 了。即,在所有训练误差为0的感知机中,选择泛化误差最小的那个感知机,这就是SVM算法最初的目的。
基本的SVM(最大间隔分类器)是一种二分类模型,它是定义在特征空间上的间隔最大的线性分类器,间隔最大是SVM和感知机不同的地方,间隔最大化对应于泛化误差最小。
1.1 决策面
面对一个线性可分的二分类问题,将正负样本分开的超平面,称为决策面。
和 线性回归 模型一样,这里一般会使用一些特征函数
这里
这里输出的取值为
如果感觉
ϕ(x) 这种表述方式不太习惯,可以考虑所有的ϕ(x)=x ,这样就和一般的书上的公式一致了。这种表达仅仅是我个人的喜好,式主要是为了强调,在实际问题中,输入空间x 一般不会作为模型的输入,而是要将输入空间通过一定的特征转换算法ϕ(x) ,转换到特征空间,最后在特征空间中做算法学习。而且,在实际问题中,各种算法基本上都是死的,但是,特征变换的这个过程ϕ(x) 却是活的,很多时候,决定一个实际问题能不能很好的解决,ϕ(x) 起着决定性的作用。举个简单的例子,比如Logistics Regression,数据最好要做归一化,如果数据不归一化,那么那些方差特别大的特征就会成为主特征,影响模型的计算,ϕ(x) 就可以做这个事情。再或者后面要降到的核函数问题,核函数SVM能解决非线性可分问题,主要也是基于使用ϕ(x) 来做非线性特征变换。
作为一个决策面:
当样本的标号
当样本的标号
**究竟什么是决策面?
答:决策面就是能够将正负样本分开的点的集合,比如上面的模型中,决策面的数学表达式为:wTϕ(x)+b=0 ,决策面就是这个式子的解集,所以,一般我们就直接用这个式子代表决策面了。可以看到,对于这个决策面的数学表达式而言,w 和b 的数值并不重要。比如,wTϕ(x)+b=0 和2wTϕ(x)+2b=0 ,后一个决策面的参数数值是前一个决策面数值的两倍,但这两个决策面的解是一样的,也就是说其得到的点集是一样的,那么这两个表达式所表示的就是同一个决策面。所以,这里我要强调一点,对于一个线性决策面而言,重要的不是w 和b 的取值,重要的是w 和b 的比值,w 和b 的比值决定了一个决策面的点集,也就决定了一个决策面。**
1.2 最优决策面
对于线性可分的二分类问题而言,使用 感知机 算法,可以得到很多很多满足上述要求的决策面,比如下图中,就是可以将正负两类数据分开的两个决策面。
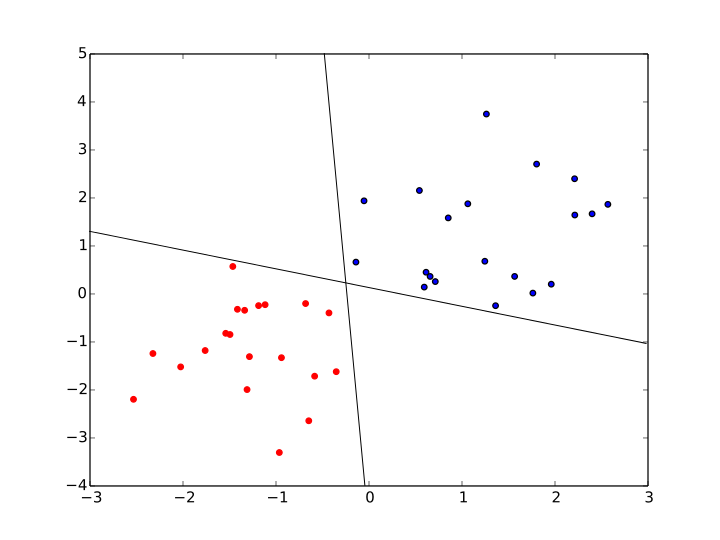
那么,在这些决策面中,哪个决策面,才是最优的决策面呢?首先,需要明确,上述的决策面,都是可以将训练样本正确分类的决策面,也就是说,上述决策面的 训练误差 都为0。要从这些训练误差都为0的模型中,选出一个最好的模型,很自然的,就需要考虑模型的 泛化误差 。
最大间隔分类器认为,决策面的泛化误差可以用训练样本集合中,离决策面最近的样本点到决策面的间隔(margin)来表示,离决策面最近的样本点,到决策面的间隔(margin)越大,那么,这个决策面的泛化误差就越小。直观的来讲,最优决策面差不多就是下面这幅图中,中间的那个决策面。
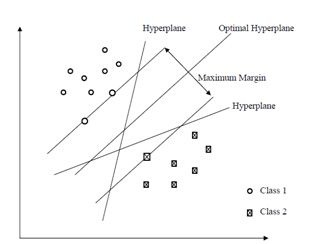
1.3 最小间隔
什么是间隔?
答:首先,要搞清楚是谁和谁的间隔,在这里指的是一个 训练样本点 和 决策面 之间的间隔。
那么,间隔又如何定义的呢?
答:间隔,就是样本点到决策面之间的距离,由中学的知识就可以知道,一个样本点
但这个距离在数值上会存在正负的问题,由于样本点类别取值
当
当
这样,分类正确的样本点的间隔就永远是正的了。
显然,一旦决策面有了,那么训练集合中的每个样本点
既然
1.4 最小间隔最大化
前面已经说了,要使用决策面在训练样本中的最小间隔
用优化理论的形式重写一下上面的式子,可以得到:
将上面的约束条件变一下型可得:
在前面已经提到过,对于一个决策面
所以,只要有一个决策面,那么,唯一确定的是
也就是说,
那么,上面的式子又可以改写为:
可以看到,上面的式子最大化的目标函数变成了
这里,最小间隔为:
在网上博客还有现有的书籍中,对于最小间隔最大化的解释,都使用了函数间隔和几何间隔的概念,我个人在第一次接触这两个概念的时候,就有些被弄糊涂了,理解了这两个概念之后,又感觉这种解释过于冗余、牵强,完全是为了解释最小间隔最大化而解释最小间隔最大化。所以,这里我直接抛弃函数间隔和几何间隔的概念,给出我个人的一种解释。
最小间隔最大化后得到的决策面,就是我们要找的泛化误差最小的决策面。对于下图中两特征的二分类问题而言,可以看出, 最小间隔为
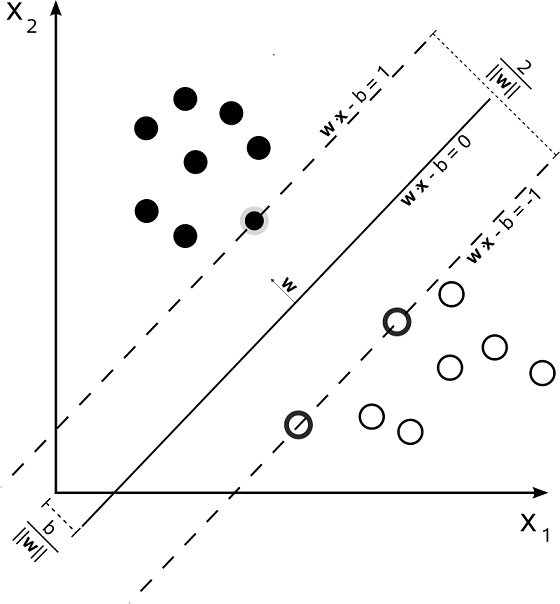
由于间隔最小的样本点
所以,间隔最小的正样本点
间隔最小的负样本点
这里定义,拥有最小间隔的正负样本点为支持向量(support vector),也就是上图中
关于支持向量机的名字,这里可以稍微说一下,因为这个名字并不是特别的好理解。首先是支持(support),根据柯林斯词典,support的主要意思:the activity of providing for or maintaining by supplying with money or necessities,表示的是提供一些必须品的意思。vector指的就是样本点,这个问题不大。那么问题来了,为什么将间隔最小的那些样本点叫做support vector(或者可以直接说是support point)呢?答:从图中可以看出,对于决策面而言,要想唯一的确定这个决策面,就是要根据最小的间隔
r 来得到,也就是说,决策面仅仅和拥有最小间隔的那些样本点相关,和其他那些间隔大于最小间隔的样本点,是没有关系的。即:拥有最小间隔的那些样本点是决策面所必须的,而间隔大于最小间隔的样本点的有无,对决策面并不构成影响。所以将拥有最小间隔的那些样本点叫做support point, 也就是support vector。
1.5 拉格朗日对偶性
在求解约束最优化问题的过程中,我们常常会使用拉格朗日对偶性(Lagrange duality),把原始问题(primal problem)转换为对偶问题(dual problem)来求解,基于对偶问题的求解来得到原始问题的解。这个方法在统计学中经常使用,不仅仅本文的SVM算法用到了拉格朗日对偶性,后面要讲的最大熵模型也用到了拉格朗日对偶性。这里仅仅对拉格朗日对偶性做一个简述,我个人认为,主要知道其概念和结果即可,无需深究。拉格朗日对偶性的详细说明,可以参见Boyd的《Convex Optimization》,该书用一整个章节的篇幅来详细的论述了拉格朗日对偶性的问题。
对于一个线性规划问题,我们称之为原始问题,都有一个与之对应的线性规划问题我们称之为对偶问题。原始问题与对偶问题的解是对应的,得出一个问题的解,另一个问题的解也就得到了。并且原始问题与对偶问题在形式上存在很简单的对应关系:
- 目标函数对原始问题是极大化,对偶问题则是极小化
- 原始问题目标函数中的系数,是对偶问题约束不等式中的右端常数,而原始问题约束不等式中的右端常数,则是对偶问题中目标函数的系数
- 原始问题和对偶问题的约束不等式的符号方向相反
- 原始问题约束不等式系数矩阵转置后,即为对偶问题的约束不等式的系数矩阵
- 原始问题的约束方程数对应于对偶问题的变量数,而原始问题的变量数对应于对偶问题的约束方程数
- 对偶问题的对偶问题是原始问题
1、原始问题
假设,有
这里
上面这种约束优化问题的形式成为原始问题。
现在,引入拉格朗日函数:
这里
现在考虑最大化这个拉格朗日函数,定义:
对于上面的最大化式子有:
- 如果不等式约束
ci(x)<0 ,等式约束hj(x)=0 ,那么上式最大化就会使得αi=0 ,βj 可以取任意值。 此时所有满足约束条件的,并且最大化结果为θp(x)=f(x) 。 - 如果不等式约束
ci(x)=0 ,等式约束hj(x)=0 ,那么上式最大化就会使得αi>0 ,βj 可以取任意值。此时是满足约束条件的,并且最大化结果为θp(x)=f(x) 。 - 如果存在不等式约束
ci(x)>0 , 等式约束hj(x)=0 ,即此时存在不等式约束违反约束条件,那么要使得上式最大化,必然会使得αi=∞ ,进而使得θp(x)=∞ 。 - 如果不等式约束
ci(x)≤0 , 存在hj(x)≠0 ,那么要使得上式最大化,必然会使得βj=∞ ,进而使得θp(x)=∞ 。
综上所述,可以知道:
由于原始最优化问题就是要在满足约束条件下,求解最小化的
也就是说,原始约束最优化问题:
中的
于是乎,原始约束最优化问题就变成了一个极小极大化的问题:
很显然,这个极小极大化问题,和原始问题是等价的。
为了方便,这里定义原始问题(primal problem)的最优解为:
2、对偶问题
对于一块磁铁而言,磁铁有N极和S极,N极和S极只是同一块磁铁的不同表现而已,这两个极性虽然不同,但是却拥有相同的本质:磁。他们是相辅相成的,是同一个事物的两种不同表现。就像有阴必有阳;有光明必有黑暗;而阴阳本为一体,明暗实为一物,他们都是同一个东西的不同表现而已,这个是世间万物的规律。
对偶问题和原始问题也是一样,他们是优化问题的两个不同表现形式而已,他们本质上是一个东西,只是表现的方式相反罢了。
考虑原始问题:
原始问题是以
原始问题最终是被极小化,成为了一个极小极大化的问题:
对偶问题,要和其相反,就需要被极大化,而称为一个极大极小化的问题:
上面的式子,就称为拉个朗日函数的极大极小问题,并定义对偶问题(dual problem)的最优解为:
由于:
所以:
上面这是式子说明,
在我们常见的问题中,只要满足一定的条件,就可以使得
3、KKT条件
对于原始问题 和 对偶问题而言,
上述的KKT条件,看起来很吓人,其实很容易理解:函数
前面已经说明过,函数
而最后一个KKT条件,对应的就是
1.6 最小间隔最大化求解
求解最小间隔最大化,就是要求解式子:
而求解上面的式子,用的到方法,就是拉格朗日对偶性。这里,在原来的最小化的目标函数前面加了
将它作为原始的优化问题,应用拉格朗日对偶性,通过求解对偶问题(dual problem)来得到原始问题(primal problem)的最优解,这个最优解,就对应于最优的决策面。
这样做的优点主要有两个:
一、对偶问题相对来说比较容易求解
二、可以很自然的引入核函数,进而推广到非线性分类器中
首先,构建拉格朗日函数,由于上面的约束优化问题中只有不等式约束,所以为所有的不等式约束添加拉格朗日乘子:
根据前面关于拉格朗日对偶性的说明可以很容易知道,这个原始问题为极小极大问题:
其对应的对偶问题为极大极小问题:
求解内部极小化
这里首先求解内部的极小化问题:
显然,这个极小化问题是以
那么,就有:
将
上面推导的导数第二步使用了:
这里的
求解外部极大化
前面已经将内部的极小化求解得到了
这个就是原问题的对偶问题,当然了,可以将这个对偶问题的目标函数的符号换一下,让它成为一个最小化的问题:
公式推导到这个地方,就可以知道,上面这个最小化问题,就是我们最终要求解的问题,其最小化的目标函数是以
也就是说,假设最优解是
那么,在已知这个最优解的情况下,我们来看一下,基于这个最优解,SVM的决策面是什么样的?
根据原始问题
那么,就有:
这里,根据已经求得的
在前面讨论过,SVM是间隔最大化的决策面,支持向量对应的就是间隔最小的那些点,由前面关于间隔最大化的讨论可以知道,支持向量满足下面这个公式:
而根据前面对原始问题的讨论,可以知道,满足这个公式的点
同时,需要注意:
当然,为了稳妥起见,很多时候,我们会将所有的支持向量
这样,就可以求得最终的决策超平面为:
分类决策函数可以写为:
这里就可以发现:
- 在预测的时候,
w∗ 和b∗ 仅仅依赖于训练集合中α∗i>0 的那些样本点,而其他样本点对w∗ 和b∗ 没有影响。但是,为了求得w∗ 和b∗ ,在训练阶段,还是需要整个样本集合。也就是说,在做预测的时候,支持向量机需要的内存空间是非常小的,只需要存储支持向量即可,预测过程和非支持向量无关。 - 分类决策函数仅仅依赖于输入
x 和 训练样本之间的內积。这个內积是后面核函数的雏形,也是SVM得以广泛应用的关键。
1.7 SVM、LDA、Logistics Regression 算法比较
在之前的文章线性判别分析(Linear Discriminant Analysis)中就说过:凡是分类算法,必定有决策面,而这些分类算法所不同的是:决策面是线性的还是非线性的;以及如果得到这个决策面。
对于Logistics Regression
对于一个二分类问题,在Logistics Regression中,假设后验概率为Logistics 分布:
这里,使用一个单调的变换函数,logit 函数:
所以Logistics Regression的决策面就是:
对于Linear Discriminant Analysis
这里假设
LDA假设
这里,特征
LDA和前面提到的Logistics Regression采用的单调变换函数一样,都是logit 函数:
所以LDA的决策面就是:
显然,在LDA中,和Logistics Regression不同的是,LDA的决策面是由各个数据分布的方差和类别中心决定的。
对于SVM
对于SVM而言,我么假设,最大间隔会带来最小的泛化误差。但是,反过来思考,这个假设真的是真确的吗?在讨论LDA和Logistics Regression的时候,我们其实也是说他们的决策面是最优的。那么,到底那个算法得到的决策面才是最好的呢?
说到这个问题,让我突然想起来前段时间的一件事情,一同学面试,面试官问他:Logistics Regression对数据分布有什么要求?他并不知道怎么回答,后来回来和他们实验室的人讨论了许久,也没有结果。其实这个回答非常的简单:
我们所面对的所有的机器学算法,都是有适用范围的,或者说,我们所有的机器学习算法都是有约束的优化问题。而这些约束,就是我们在推导算法之前所做的假设。
比如:Logistics Regression,上面已经明确说明了,在Logistics Regression中,假设后验概率为Logistics 分布;再比如:LDA假设
而对于SVM而言,它并没有对原始数据的分布做任何的假设,这就是SVM和LDA、Logistics Regression区别最大的地方。这表明SVM模型对数据分布的要求低,那么其适用性自然就会更广一些。如果我们事先对数据的分布没有任何的先验信息,即,不知道是什么分布,那么SVM无疑是比较好的选择。
但是,如果我们已经知道数据满足或者近似满足高斯分布,那么选择LDA得到的结果就会更准确。如果我们已经知道数据满足或者近似满足Logistics 分布,那么选择Logistics Regression就会有更好的效果。
通过这三个方法的比较,我只想说明一件事情:机器学习算法是死的,但,人是活的。使用什么机器学习算法,是根据实际问题要求,和数据的具体分布而定的。