版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u012848709/article/details/83066019
楔子
学习了解hive
hive常用交互命令
[root@hadoop102 ~]# hive -help
usage: hive
-d,--define <key=value> Variable subsitution to apply to hive
commands. e.g. -d A=B or --define A=B
--database <databasename> Specify the database to use
-e <quoted-query-string> SQL from command line
-f <filename> SQL from files
-H,--help Print help information
--hiveconf <property=value> Use value for given property
--hivevar <key=value> Variable subsitution to apply to hive
commands. e.g. --hivevar A=B
-i <filename> Initialization SQL file
-S,--silent Silent mode in interactive shell
-v,--verbose Verbose mode (echo executed SQL to the
console)
-- -e 不进入hive交互窗口执行sql
[root@hadoop102 ~]# hive -e "select * from student"
-- -f 执行脚本中的sql
[root@hadoop102 ~]# hive -f /opt/module/data/hive_student.sql
-- 退出
exit -- 先隐形提交数据,在退出
quit --不提交数据,退出
-- 在hive cli命令窗口查看hdfs 文件系统
hive (default)> dfs -ls /;
-- 在hive cli命令查看本地文件
hive (default)> ! ls /usr/local;
-- 查看 当前用户执行的 历史命令 (在当前用户目录下 .hivehistory 中 )
[grq@hadoop102 ~]$ pwd
/home/grq
[grq@hadoop102 ~]$ ll -a .h*
-rw-rw-r--. 1 grq grq 71 10月 15 15:29 .hivehistory
DDL数据定义
- 创建数据库
hive (default)> create database if not exists db_hive;
创建的数据库默认存储在
/user/hive/warehouse/${DB_NAME}.db
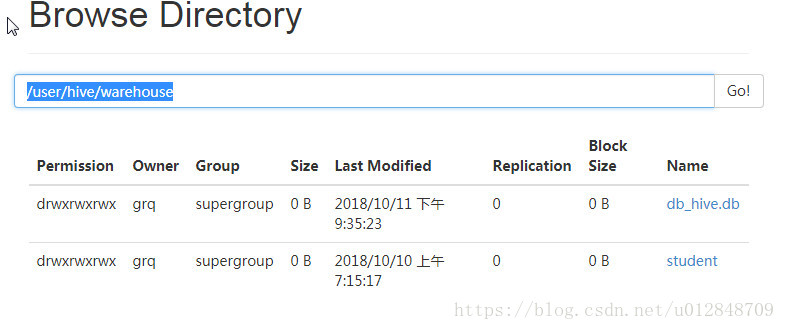
- 创建数据指定位置
hive (default)> create database if not exists db_hive2 location '/db_hive2.db'; - 修改数据库
hive (default)> alter database db_hive set dbproperties('createtime'='201810');– 注意属性和值的单引号
hive (default)> desc database extended db_hive;

查询数据库
hive (default)> show databases;# 显示数据库信息
OK
database_name
db_hive
db_hive2
default
Time taken: 0.285 seconds, Fetched: 3 row(s)
hive (default)> show databases like 'db_hiv*';# 过滤显示数据库信息
OK
database_name
db_hive
db_hive2
Time taken: 0.102 seconds, Fetched: 2 row(s)
hive (default)> desc databases db_hive;
FAILED: SemanticException [Error 10001]: Table not found databases
hive (default)> desc database db_hive;# 显示数据库详情
OK
db_name comment location owner_name owner_type parameters
db_hive hdfs://hadoop102:9000/user/hive/warehouse/db_hive.db grq USER
Time taken: 0.166 seconds, Fetched: 1 row(s)
hive (default)> use db_hive;# 切换数据库
OK
Time taken: 0.17 seconds
hive (db_hive)> drop database db_hive2;# 删除数据库
OK
Time taken: 1.067 seconds
hive (db_hive)> drop database if exists db_hive2;
OK
Time taken: 0.117 seconds
hive (db_hive)> drop database if exists db_hive2 cascade;# 如果数据库不为空,使用cascade命令,强制删除
OK
Time taken: 0.215 seconds
hive (db_hive)>
创建表例子
创建普通表
create table if not exists student2(
id int,name string
)
row format delimited fields terminated by '\t'
stored as textfile
location '/opt/module/data/stu.txt';
-- 加载数据
load data local inpath '/opt/module/data/stu.txt' into table student2;
根据查询结果创建表
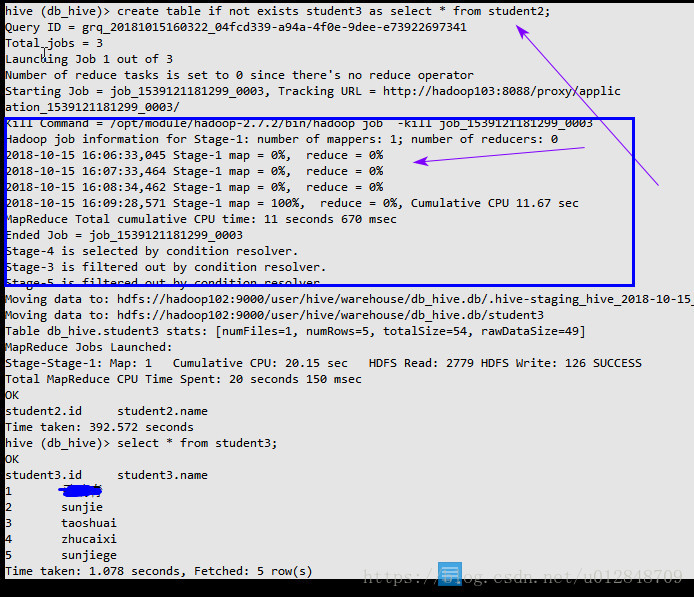
create table if not exists student3 as select * from student2;
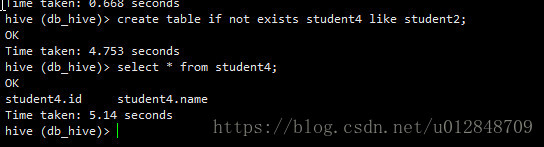
根据已经存在的表结构创建表(不会执行mapreduce)
create table if not exists student4 like student2;
查询表类型
desc formatted student4;
外部表
外部表。hive并非完全拥有这份数据,删除表并不会删除这份数据,不过描述表的源数据信息会被删除。
使用场景
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
案例
创建部门、员工表
创建部门表
create external table if not exists default.dept(
deptno int,
dname string,
loc int
)
row format delimited fields terminated by '\t';
员工表
create external table if not exists default.emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)
row format delimited fields terminated by '\t';
导入数据
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept;
hive (default)> load data local inpath '/opt/module/data/emp.txt' into table default.emp;
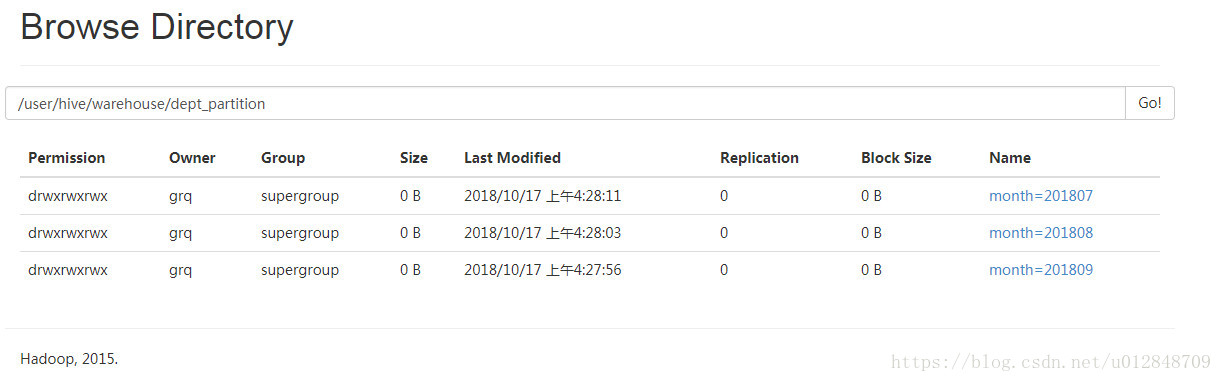
分区表
分区表实际上就是对应一个HDFS文件系统上的独立的文件夹,该文件夹下是该分区所有的数据文件。Hive中的分区就是分目录,把一个大的数据集根据业务需要分割成小的数据集。在查询时通过WHERE子句中的表达式选择查询所需要的指定的分区,这样的查询效率会提高很多。
创建分区表 加载数据
create table dept_partition(
deptno int, dname string, loc string
)
partitioned by (month string)
row format delimited fields terminated by '\t';
加载数据
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept_partition partition(month='201809');
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept_partition partition(month='201808');
hive (default)> load data local inpath '/opt/module/data/dept.txt' into table default.dept_partition partition(month='201807');
查询数据
hive (default)> select * from dept_partition where month='201809';
-- 联合查询
select * from dept_partition where month='201809'
union
select * from dept_partition where month='201808'
union
select * from dept_partition where month='201807';
查看有多少分区
show partitions dept_partition;
创建二级分区
create table dept_partition2(
deptno int, dname string, loc string
)
partitioned by (month string, day string)
row format delimited fields terminated by '\t';