第八章 深度学习中的优化
在深度学习涉及的诸多优化问题中,最难的是神经网络训练 。
本章主要关注基于梯度的优化问题:寻找神经网络上的一组参数θ,它能显著地降低代价函数J(θ),该代价函数通常包括整个训练集上的性能评估和额外的正则化项。
目前最流行并且使用很高的优化算法包括SGD、具动量的SGD、RMSProp、具动量的RMSProp、AdaDelta和Adam。 此时,选择哪一个算法似乎主要取决于使用者对算法的熟悉程度(以便调节超参数)。
训练算法使用的优化与纯优化有哪些不同
1、机器学习算法优化的目标是降低泛化误差,即
,但事实上pdata我们不知道,我们只知道训练集。因此机器学习问题转化为最优化训练集上的期望损失,即利用训练集上的分布来代替
来替代真实的p(x,y),即最小化经验风险
基于最小化这种平均训练误差的训练过程被称为经验风险最小化(empirical risk minimization)。此时,机器学习仍然和传统的直接优化很相似
2、经验风险最小化很容易导致过拟合。现代优化方法是基于梯度下降的,有些经验损失函数,比如0-1损失,没有有效的导数,因此,我们通常会优化代理损失函数(surrogate loss function),比如交叉熵损失函数。
一般的优化和我们用于训练算法的优化有一个重要不同
- 训练算法通常不会停止在局部极小点。反之,机器学习通常优化代理损失函数,但是在基于提前终止的收敛条件满足时停止。
- 与纯优化不同的是,提前终止时代理损失函数仍然有较大的导数,而纯优化终止时导数较小。
3、机器学习算法中的优化算法在计算参数的每一次更新时通常仅使用代价函数中一部分项来估计代价函数的期望值,在整个数据集的每个样本上的损失来评估模型,代价非常大。实践中,可以从数据集中随机采样少量的样本,然后计算这些样本的平均值。
(1)n个样本均值的标准差为
,基于100个样本和10000个样本,后者需要的计算量是前者的100倍,但是却只降低了10倍的标准差。因此,小批量算法(minibatch)会收敛的更快。
(2)一个原因是训练集中大量样本都对梯度做出相似的贡献
小批量的大小由以下因素决定:
(1)、更大的批量会更精确梯度计算,但是回报是现行的
(2)、极小批量难以充分利用多核架构,更小批量处理不会减少计算时间
(3)、所有样本参与训练,对内存要求过高,硬件不支持
(4)、通常采用2的幂数来作为批量大小可以获得更少的运行时间,一般选32-256
(5)、小批量算法在学习过程中加入了噪声,因此,会有一定的正则化效果。
小批量要求随机抽取,因此常常需要打乱样本顺序
神经网络优化中的挑战
传统机器学习会小心设计目标函数和约束,以确保优化问题是凸的,但训练神经网络时,一定会遇到非凸情况。
总结:在神经网络训练中,我们通常不关注某个函数的精确极小点,而只关注将其值下降到足够小以获得一个良好的泛化误差。
1.病态
什么是病态ill-conditioned?
现在有线性系统: Ax = b, 解方程
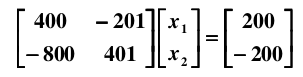
很容易得到解为: x1 = -100, x2 = -200。
如果在样本采集时存在一个微小的误差,比如,将 A 矩阵的系数 400 改变成 401:
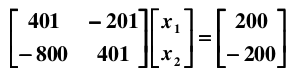
则得到一个截然不同的解: x1 = 40000, x2 = 79800。
当解集 x 对 A 和 b 的系数高度敏感,那么这样的方程组就是病态的 (ill-conditioned)。
线性系统 Ax = b 为什么会病态?
归根到底是由于 A 矩阵列向量线性相关性过大,表示的特征太过于相似以至于容易混淆所产生的。举个例子, 现有一个两个十分相似的列向量组成的矩阵 A:
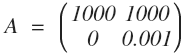
在二维空间上,这两个列向量夹角非常小。
假设第一次检测得到数据
, 这个点正好在第一个列向量所在的直线上,解集是 [1, 0]T。
现在再次检测,由于有轻微的误差,得到的检测数据是 b = [1000, 0.001]T, 这个点正好在第二个列向量所在的直线上,解集是 [0, 1]T。
两次求得到了差别迥异的的解集。
在优化凸函数时,会遇到一些挑战。 这其中最突出的是Hessian矩阵 的病态。 这是数值优化、凸优化或其他形式的优化中普遍存在的问题。
病态问题一般被认为存在于神经网络训练过程中。 病态体现在随机梯度下降会”卡”在某些情况,此时即使很小的更新步长也会增加代价函数。
我们可以通过监测平方梯度范数 和 ,来判断病态是否不利于神经网络训练任务。
2.局部极小点
优化一个凸问题时,若发现了任何形式的临界点,我们都会知道已经找到了一个不错的可行解(局部最小即全局最小)。对于非凸函数时,如神经网络,有可能会存在多个局部极小值。
一种能够排除局部极小值是主要问题的检测方法是画出梯度范数随时间的变化。 如果梯度范数没有缩小到一个微小的值,那么该问题既不是局部极小值,也不是其他形式的临界点。
在高维空间中,很难明确证明局部极小值是导致问题的原因。 许多并非局部极小值的结构也具有很小的梯度。
3.高原、鞍点和平坦区域
由于神经网络参数维度非常高,局部极小点出现的机会非常小,鞍点则更常见,鞍点附近的梯度非常小,但实验中梯度下降似乎可以逃离鞍点。除了鞍点和极小点,也可能存在高原、平坦区域,此时梯度和Hessian矩阵都是零,这是所有优化问题的主要问题。
4.悬崖和梯度爆炸
训练非常深的神经网络或循环神经网络时,会出现像悬崖一样的斜率较大的区域,这是由于几个较大的权重相乘导致的,遇到斜率较大的悬崖结构是,梯度更新会很大程度改变参数值,我们可以采用启发式的梯度截断来避免,传统梯度下降至说明无限小区域内的最佳方向,但没有说明最佳步长,当梯度下降提议更新很大一步时,梯度截断会干涉以减小步长,循环神经网络中非常常见。
5.长期依赖
当计算图变得极深时,由于变深的结构使得模型丧失了学习到先前信息的能力,让优化变得及其困难,因为循环神经网络要在很长时间序列的各个时刻重复应用相同操作来构建非常深的计算图,并且模型参数共享,问题会更严重。
例如,假设某个计算图中包含一条反复与矩阵W相乘的路径,经过t步后,相当于乘以 ,假设W可分解为 ,则 ,
- 当t比较大时,λi大于1,会发生
梯度爆炸(exploding gradient) - λi小于1,则会出现
梯度消失(vanishing gradient) 。
梯度消失会使得我们难以知道朝那个方向移动能改进代价函数,而梯度爆炸会使得学习不稳定。 随着t的增加,最终会丢失点x中的有效信息(稳定状态只与W有关)。
6.非精确梯度
大多数优化算法的先决条件都是我们知道精确的梯度或是 Hessian 矩阵。
在实践中,通常这些量会有噪声,甚至是有偏的估计。几乎每一个深度学习算法都需要基于采样的估计,至少使用训练样本的小批量来计算梯度。
各种神经网络优化算法的设计都考虑到了梯度估计的缺陷。我们可以选择比真实损失函数更容易估计的代理损失函数来避免这个问题。
7.局部和全局结构间的弱对应–寻找良好的初始点
迄今为止,我们讨论的许多问题都是关于损失函数在单个点的性质——若 是当前点 的病态条件,或者 在悬崖中,或者 是一个下降方向不明显的鞍点,那么会很难更新当前步。
如果该方向在局部改进很大,但并没有指向代价低得多的遥远区域,那么我们有可能在单点处克服以上所有困难,但仍然表现不佳。
大多数优化研究的难点集中于训练是否找到了全局最小点、局部极小点或是鞍点,但在实践中神经网络不会到达任何一种临界点。神经网络通常不会到达梯度很小的区域。甚至,这些临界点不一定存在。
许多现有研究方法在求解具有困难全局结构的问题时,旨在寻求良好的初始点,而不是开发非局部范围更新的算法。如果存在一个区域,我们遵循局部下降便能合理地直接到达某个解,并且我们能够在该良好区域上初始化学习,那么这些问题都可以避免。最终的观点还是建议在传统优化算法上研究怎样选择更佳的初始化点,以此来实现目标更切实可行。
8.优化的理论限制
一些理论结果表明,我们为神经网络设计的任何优化算法都有性能限制。通常这些结果不影响神经网络在实践中的应用。
在神经网络训练中,我们通常不关注某个函数的精确极小点,而只关注将其值下降到足够小以获得一个良好的泛化误差。对优化算法是否能完成此目标进行理论分析是非常困难的。因此,研究优化算法更现实的性能上界仍然是学术界的一个重要目标。
