
日萌社
人工智能AI:Keras PyTorch MXNet TensorFlow PaddlePaddle 深度学习实战(不定时更新)
什么是神经网络的梯度消失/梯度爆炸问题,如何解决
(1)定义:
如下图所示:C表示的是代价函数,前一层的输出和后一层的输入关系

1)使用sigmoid函数的导数,导数最大值为1/4,而我们一般会使用标准方法来初始化网络权重,即使用一个均值为0标准差为1的高斯分布。因此,初始化的网络权值通常都小于1。但是由于上面的图中或者更深的网络导致层数越多,求导结果越小,最终导致梯度消失的情况出现。
2)但是当sigma(z)*w>1的时候,也就是w比较大的情况。前面的网络层比后面的网络层梯度变化更快,引起了梯度爆炸的问题。
但是梯度爆炸问题在使用sigmoid激活函数时,出现的情况较少,不容易发生。因为需要|w|>4才会造成这样的效果。(sigmoid导数的最大值0.25)
解决办法:
(2)、梯度消失问题解决
1)用ReLU、Leaky ReLU、(PRelu、RRelu)等替代sigmoid函数。
2)使用BN层,减少网络的训练难度,同时减少输入数据大小
3)输入数据x的标准化策略,参数初始化策略使用一个均值为0标准差为1的高斯分布
4)使用现有预训练模型进行微调,减缓网络训练难度
(3)梯度爆炸问题:梯度剪切(超过指定的范围,梯度值进行剪切)、权重正则化手段
神经网络的过拟合问题怎么解决
(1)L1与L2正则化



(2)Dropout正则化
1、训练过程
神经元随机失效,概率为P。并且在神经元存在且工作的状态下,权重才会更新,权重更新的越多理论上会变得更大
2、测试过程
神经元随机失效,概率为0。所有的神经元都会参与计算,大于训练时候的任意一个模型的计算量
实现
def dropout(x, level):
if level < 0. or level >= 1:
raise Exception('dropout保持概率在0到1之间')
sample = np.random.binomial(n=1, p=level, size=x.shape)
print(sample)
x *= sample
x /= level
return x
x = np.asarray([1, 2, 3, 4, 5, 6, 7, 8, 9, 10], dtype=np.float32)
dropout(x, 0.8)3.为什么需要去做rescale

(3)BN结构

1、Batch Normalization的作用就是减小Internal Covariate Shift 所带来的影响,让模型变得更加健壮,鲁棒性(Robustness)更强。
2 、Batch Normalization 的作用,使得均值和方差保持固定(由每一层γ和β决定),不同层学习到不同的分布状态
3、因此后层的学习变得更容易一些。Batch Normalization 减少了各层 W 和 b 之间的耦合性,让各层更加独立,实现自我训练学习的效果
(4)早停止法
通常不断训练之后,损失越来越小。但是到了一定之后,模型学到的过于复杂(过于拟合训练集上的数据的特征)造成测试集开始损失较小,后来又变大。模型的w参数会越来越大,那么可以在测试集损失减小一定程度之后停止训练。
(5)数据增强
剪切、旋转/反射/翻转变换、缩放变换、平移变换、尺度变换、对比度变换、噪声扰动、颜色变换等一种或多种组合数据增强变换的方式来增加数据集的大小
请写出卷积网络的大小计算公式和感受野计算的公式
(1)卷积网络计算公式
输入大小:H1,W1,C1
输出大小:H2,W2,C2
卷积核参数:FxF(核大小),S(步长),P(零填充大小), N(卷积核个数)
H2 = (H1-F+2P)/S +1
W2 = (W1-F+2P)/S + 1
C2 = N
(2)感受野计算

计算案例(初始的感受野大小为1),我们的结构顺序为(卷积、池化、卷积、卷积):
3x3的卷积(stride=1):r=1 + (3 -1)=3,感受野大小为3x3
2x2的池化(stride=2):r = 3 + (2 - 1)*1 = 4,感受野为4x4
3x3的卷积(stride=3):r = 4 + (3-1)*2*1=8,感受野为8x8
3x3的卷积(stride=2):r = 8 + (3-1)*3*2*1=20,感受野为20x20
有哪些激活函数可以使用?详细说明每种激活函数的特点
(1)sigmoid

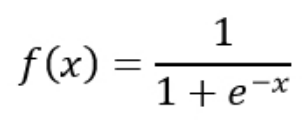
1.Sigmoid函数饱和使梯度消失。sigmoid神经元有一个不好的特性,就是当神经元的激活在接近0或1处时会饱和:在这些区域,梯度几乎为0。
2.指数函数的计算是比较消耗计算资源的
(2)Tanh

Tanh:和sigmoid神经元一样,它也存在饱和问题,依然指数运算。但是和sigmoid神经元不同的是,它的输出是零中心的。
(3)Relu

优点:
1相较于sigmoid和tanh函数,ReLU对于随机梯度下降的收敛有巨大的加速作用,这是由它的线性,非饱和的公式导致的。
2sigmoid和tanh神经元含有指数运算等耗费计算资源的操作,而ReLU可以简单地通过对一个矩阵进行阈值计算得到。
缺点:在训练的时候,ReLU单元比较脆弱并且可能“死掉”。
(4)Leaky ReLU:

Leaky ReLU是为解决“ReLU死亡”问题的尝试。ReLU中当x<0时,函数值为0。而Leaky ReLU则是给出一个很小的负数梯度值,比如0.01。
优化方法 sgd, momentum, rmsprop, adam的区别和联系
(1)SGD
相对于批量梯度和mini-batch梯度下降,随机梯度下降在每次更新时用1个样本,随机也就是说我们用样本中的一个例子来近似我所有的样本,来调整参数。
问题:

虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。但是相比于批量梯度,这样的方法更快,更快收敛,虽然不是全局最优,但很多时候是我们可以接受的。当然理论上来讲SGD会很难去解决鞍点等优化问题,需要后面的算法去进行求解。
(2)momentum
动量梯度下降(Gradient Descent with Momentum)是计算梯度的指数加权平均数,并利用该值来更新参数值。动量梯度下降法的整个过程为,其中β通常设置为0.9:

下面两种都是能够适应性地对学习率调参的方法,甚至是逐个参数适应学习率调参。
(3)RMSProp
不同于AdaGrad算法里状态变量st是截至时间步t所有小批量随机梯度gt按元素平方和。
RMSProp(Root Mean Square Prop)算法将这些梯度按元素平方做指数加权移动平均

(4)Adam算法
Adam 优化算法(Adaptive Moment Estimation,自适应矩估计)将 Momentum 和 RMSProp 算法结合在一起。Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均。


