现在逐渐的开始接触深度学习的知识,最近看了Ng老师的深度学习视频,看到里面介绍了几种经典的卷积神经网络其中就包含LeNet-5所以就照葫芦画瓢,用tensorflow实现了一下最原始的LeNet-5模型,顺便也是为了学习tensorflow。虽然代码很简单,由于是新手遇到了很多意想不到的坑。所以写篇博客记录一下。
开始一定要牢记的一句话,一定要把模型分析透了再去写代码,每一层的输入是什么shape,输出是什么shape。最好写纸上,要不写着写着就乱了。(笑哭)
模型的结构很简单,上图:
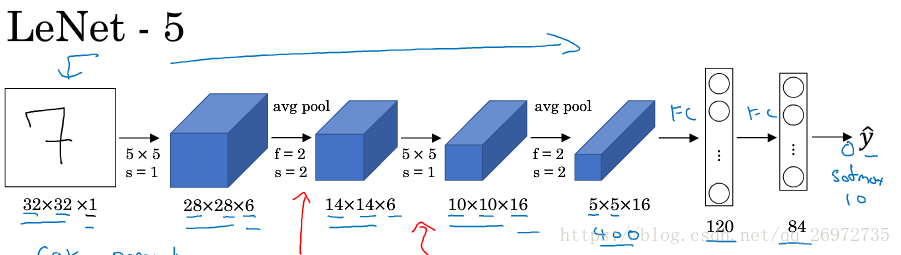
模型一共进行了两次卷积,每次卷积后面有一层平均池化层,最后再加两层全连接层。 实验用的数据是手写数字。每一层具体如下:
卷积层:
输入层:输入的图片大小为:28*28*1
第一层卷积:filter_size为5*5,步长(s)为1,卷积核的个数为6,no padding,激活函数为relu
第一层平均池化:filter_size为2*2,步长(s)为2(这种池化会使输入的feature map长和宽缩小一倍),no padding
第二层卷积:filter_size为5*5,步长(s)为1,卷积核的个数为16, no padding,激活函数为relu
第二层平均池化:filter_size为2*2,步长(s)为2,no padding
全连接层:
第一层120个节点,激活函数为relu
第二层84个节点,激活函数为relu
输出层10个节点,没有激活函数
def inference(self, input_tensor):
with tf.variable_scope("layer1-conv1"):
conv1_weight = tf.get_variable(name = "conv1_variable", shape=[5,5,1,6], initializer=tf.truncated_normal_initializer())
conv1_bias = tf.get_variable(name = "conv1_bias", shape = [6], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input = input_tensor, filter = conv1_weight, strides = [1, 1, 1, 1], padding = "VALID")
relu1 = tf.nn.relu(tf.add(conv1, conv1_bias))
pool1 = tf.nn.avg_pool(relu1, ksize = [1, 2, 2, 1], strides = [1, 2, 2, 1], padding = "VALID")
with tf.variable_scope("layer2-conv2"):
conv2_weight = tf.get_variable(name = "conv2_variable", shape=[5,5,6,16], initializer=tf.truncated_normal_initializer())
conv2_bias = tf.get_variable(name = "conv2_bias", shape = [16], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(input = pool1, filter = conv2_weight, strides = [1, 1, 1, 1], padding = "VALID")
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_bias))
pool2 = tf.nn.avg_pool(relu2, ksize = [1,2,2,1], strides = [1,2,2,1], padding = "VALID")
with tf.variable_scope("layer3-fc1"):
conv_layer_flatten = tf.layers.flatten(inputs = pool2) #[batch_size, 256]
fc1_variable = tf.get_variable(name = 'fc1_variable', shape = [256, 120], initializer = tf.random_normal_initializer()) * 0.01
fc1_bias = tf.get_variable(name = 'fc1_bias', shape = [1, 120], initializer = tf.constant_initializer(value=0))
fc1 = tf.nn.relu(tf.add(tf.matmul(conv_layer_flatten, fc1_variable), fc1_bias)) #[batch_size, 120]
with tf.variable_scope("layer4-fc2"):
fc2_variable = tf.get_variable(name = "fc2_variable", shape=[120,84], initializer=tf.random_normal_initializer()) * 0.01 #[batch_size, 84]
fc2_bias = tf.get_variable(name = "fc2_bias", shape=[1, 84],initializer = tf.constant_initializer(value=0))
fc2 = tf.nn.relu(tf.add(tf.matmul(fc1, fc2_variable), fc2_bias)) #[batch_size, 84]
with tf.variable_scope("layer5-output"):
output_variable = tf.get_variable(name = "output_variable", shape = [84, 10],initializer = tf.random_normal_initializer()) * 0.01
output_bias = tf.get_variable(name = "output_bias", shape = [1, 10],initializer = tf.constant_initializer(value=0))
output = tf.add(tf.matmul(fc2, output_variable), output_bias) #[batch_size, 10]
return output在模型训练的过程中出现了一些问题,开始我为了让初始化的权值尽量都小一些,让每一层的卷积核的权重初始化时都乘以0.01,但是发现如果这么做损失函数收敛的很慢甚至都不会收敛。刚开始的时候我以为是我代码有问题,那个费劲的找bug啊!都是泪。我原来一直认为神经网络权值初始化时应该尽量小一些,看来也不是这样的。经过了千辛万苦模型终于训练好了。
最终在训练集、测试集、验证集上的精度如下:
if __name__ == "__main__":
model = LeNet5()
# model.train(iter_num=200)
#evaluate model on trainSet
images_train = model.mnist.train.images
y_true_train = model.mnist.train.labels
images_train = images_train.reshape([-1, 28,28,1])
y_true_train = np.argmax(y_true_train, axis=1).reshape(-1, 1)
model.evaluate(images_train, y_true_train) #accuracy is 0.9611818181818181
#evaluate model on testSet
images_test = model.mnist.test.images.reshape([-1, 28,28,1])
y_true_test = model.mnist.test.labels
y_true_test = np.argmax(y_true_test, axis = 1).reshape(-1, 1)
model.evaluate(images_test, y_true_test) #accuracy is 0.9645
#evaluate model on validate
images_validation = model.mnist.validation.images.reshape([-1, 28,28,1])
y_true_validation = model.mnist.validation.labels
y_true_validation = np.argmax(y_true_validation, axis = 1).reshape(-1, 1)
model.evaluate(images_validation, y_true_validation) #accuracy is 0.9648完整代码在我的github中,地址:https://github.com/NewQJX/DeepLearning/tree/master/LeNet5