HBase适用场景
首先在搞HBase之前我们要对其建立感性认识,其适用场景如下:
- 并发、简单、随机查询。
(注:HBase不太擅长复杂join查询,但可以通过二级索引即全局索引的方式来优化性能,后续博文会进行讲解) - 半结构化、非结构化数据存储。
一般我们从数仓中离线统计分析海量数据,将得到的结果插入HBase中用于实时查询。
HBase表结构
这里以一个公司员工表为案例来讲解,此表中包含员工基本信息(员工姓名、年龄),员工详细信息(工资、角色),以及时间戳。整体表结构如下:
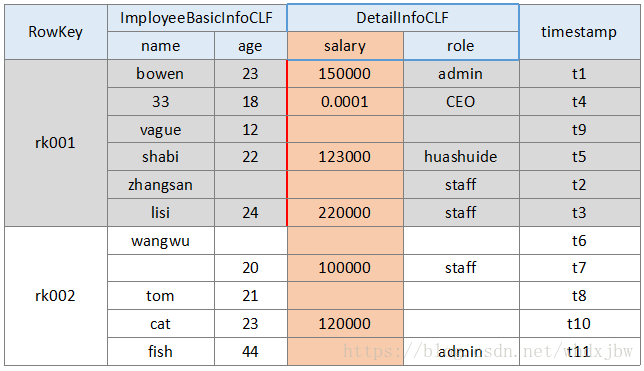
如上,每一行有一个RowKey用于唯一地标识和定位行,各行数据按RowKey的字典序排列。其中ImployeeBasicInfoCLF和DetailInfoCLF是两个列族,列族下又有多个具体列。(员工基本信息列族:姓名、年龄。详细信息列族:薪水、角色)
(注1:图中列族下面每一行中特定列中只画了最新版本的数据,实际上HBase最小存储单元为cell,图中每个单元格中其实有多个MVCC version版本的cell,Hbase的更新操作会带时间戳,对每个数据单元cell,可存取指定数量版本的cell,client端可以指定查询某时间点后的最新数据,也可以一次性得到cell的所有版本。)
(注2:刚刚评论里有同学提到cell的概念,这里详细说一下,cell里可得道的信息包含: row、 column family、 column qualifier(列限定符)、timestamp、type6、MVCC version、value。其中每个cell 由 row、column family、column qualifier、timestamp,、and type唯一标识。
HBase数据模型
- 命名空间
命名空间是对表的逻辑分组,不同的命名空间类似于关系型数据库中的不同的Database数据库。利用命名空间,在多租户场景下可做到更好的资源和数据隔离。
- 表
对应于关系型数据库中的一张张表,HBase以“表”为单位组织数据,表由多行组成。
- 行
行由一个RowKey和多个列族组成,一个行有一个RowKey,用来唯一标示。
- 列族
每一行由若干列族组成,每个列族下可包含多个列,如上ImployeeBasicInfoCLF和DetailInfoCLF即是两个列族。列族是列共性的一些体现。注意:物理上,同一列族的数据存储在一起的。
- 列限定符
列由列族和列限定符唯一指定,像如上的name、age即是ImployeeBasicInfoCLF列族的列限定符。
- 单元格
单元格由RowKey、列族、列限定符唯一定位,单元格之中存放一个值(Value)和一个版本号。
- 时间戳
单元格内不同版本的值按时间倒序排列,最新的数据排在最前面
HBase表特点
- 数据规模大,单表可容纳数十亿行,上百万列。
- 无模式,不像关系型数据库有严格的Scheme,每行可以有任意多的列,列可以动态增加,不同行可以有不同的列,列的类型没有限制。
- 稀疏,值为空的列不占存储空间,表可以非常稀疏,但实际存储时,能进行压缩。
- 面向列族,面向列族的存储和权限控制,支持列族独立查询。
- 数据多版本,利用时间戳来标识版本
- 数据无类型,所有数据以字节数据形式存储
原文:https://blog.csdn.net/whdxjbw/article/details/81101200