和传统的关系型数据库类似,HBase以表(Table)的方式组织数据。HBase的表由行(Row)和列(Column)共同构成,与关系型数据库不同的是HBase有一个列族(ColumnFamily)的概念,它将一列或者多列组织在一起,HBase的列必须属于某一个列族。
行和列的交叉点称为单元格(Cell),单元格是版本化的。单元格的内容也就是列的值是不可分割的字节数组,以二进制形式存储。HBase没有数据类型,任何列值都被转换成字节数组进行存储。
HBase表中的行是通过行键(Rowkey)进行区分的,行键也是用来唯一确定一行的标识,不同的行键代表不同不同的行,行键也是一段字节数组,不论是字符串还是数字,最终都会被转换成字节数组进行存储。
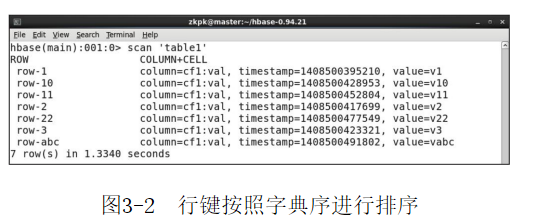
HBase表中的行是按Rowkey排序的,排序方式采用字典顺序,所有表中的行都必须要有Rowkey。
一.两类数据模型
1.1逻辑模型
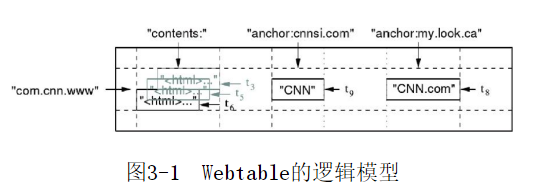
HBase可以理解为是一个稀疏的、长期存储的、多维度的和排序的映射表,表中的每一行可以有不同的列。
HBase中最基本的单位是列,一列或者多列构成了行,行有行键(Rowkey),每一行的行键都是唯一的,相同行键的插入操作被认为是对同一行的操作。
每行有很多列,列中的值有多个版本,每个版本的值称为一个单元格,每个单元存储的是不同时刻该列的值。
列名是由列族前缀和修饰符(Qualifier)连接而成,分隔符是英文冒号。
1.2物理模型
HBase在物理上,表是按列分开存储的。HBase的列是按列族分组的,HFile是面向列的,存放行的不同列的物理文件,一个列族的数据存放在多个HFile中,最重要的是一个列族的数据会被同一个Region管理,物理上存放在一起。空白Cell在物理上是不存储的。
二.数据模型的重要概念
2.1表
用户可以通过命令行或JavaAPI来创建表。表名通常使用JavaString类型或byte[](二进制数组)表示,表名作为HDFS存储路径的一部分来使用,因此必须要符合文件名规范,所以构成表名的字符是有限制的。
可以直接查看底层存储系统,在HDFS中可以看到每个表的表名都作为独立的目录结构,
HBase中表的数量相对RDBMS较少。
从物理结构上看,HBase表存储在不同的分区,即不同的Region。每个Region只在一个RegionServer中提供服务,而Region直接向客户端提供存储和读取服务。
HBase的表没有列定义,没有类型,这就是HBase被称为无模式数据库的原因。
如何与HBase建立连接呢?可以使用Shell,或者通过JavaAPI,与使用JDBC或ODBC访问关系型数据库不同,访问HBase不需要用户名和密码,没有Schema;将hbase-site.xml配置文件复制一份到自己的工程中,HBaseAPI会读取配置文件完成对HBase的连接。
创建连接是一项非常消耗资源的工作,HBase为我们提供了一个连接池,可以更好地管理资源重用。
2.2行键
行键,即Rowkey,行键是按字典排序由低到高存储在表中的,以一个空的数组来标识表空间的起始或者结尾。
为了高效检索数据,应该仔细设计Rowkey以获得最高的查询性能:
首先Rowkey长度不宜过长,过长的Rowkey将会占用大量的空间同时会降低检索效率;其次Rowkey应该尽量分布均匀,这样不会产生热点现象;最后是Rowkey唯一原则,必须在设计上保证其唯一性。
2.3列族
HBase中的列族是一些列的集合。一个列族中所有列成员有着相同的前缀。冒号(:)是列族的分隔符,Column前缀必须是可打印的字符,剩下的部分(称为ColumnQualifier),可以由任意字节数组组成。
在物理上,一个列族的成员在文件系统上都是存储在一起的。
在创建表的时候至少要指定一个列族,新的列族可以随后按需、动态地加入,但是修改列族要先停用表。应该将经常一起查询的列放在一个列族中,合理划分列族将减少查询时加载到缓存的数据,提高查询的效率,但也不要有太多的列族,因为跨列族访问是非常低效的。
2.4单元格
HBase中的单元格由行键、列族、列、时间戳唯一确定。单元格的内容是不可分割的字节数组。每个单元格都保存着同一份数据的多个版本,不同时间版本的数据按照时间顺序倒序排序,最新时间的数据排在最前面,时间戳是64位的整数,可以由客户端在写入数据时赋值,
也可以由RegionServer自动赋值。
三.数据模型的操作
HBase对数据模型的4个主要操作包括Get、Put、Scan和Delete。
所有修改数据的操作都保证行级别的原子性,多个客户端或线程对同一行的读写操作都不会影响该行数据的原子性,要么读到最新的数据,要么等待系统允许写入该行的修改。
创建HTable实例是有代价的。每个实例都需要扫描.META.表,以检查该表是否存在,是否可用。
因此,推荐用户只创建一次HTable实例,而且是每个线程创建一个,如果用户需要使用多个HTable实例,应考虑使用HTablePool类,它可以复用多个HTable实例。
3.1读GET
HTable类中提供了get()方法,同时还有与之对应的Get类,Get操作返回一行或多行数据。get()方法默认一次取回该行全部列的数据,我们可以限定只取回某个列族对应的列的数据,或者进一步限定只取回某些列的数据,之前也说过HBase的列的数据是多版本的,
我们可以限定取回该列全部版本的数据或者限定只取回最新的一个或几个版本的数据。get()方法返回的结果将被封装在一个Result实例中返回给用户。用Result类提供的方法,可以从服务器端获取匹配指定行的特定返回值,这些值包括列族、列限定符和时间戳等。
3.2写PUT
Put操作要么向表增加新行(如果Key是新的)或更新行(如果Key已经存在)。如果要频繁修改某些行的数据,用户应该创建一个RowLock实例来防止其他用户对该行数据进行修改。
Put操作每次都会发起一次到服务器的RPC操作,HBase客户端有一个缓冲区,负责将数据批量地仅通过一次RPC操作发送到服务端,这样可大大提高写入性能,默认客户端写缓冲区是关闭的,需要显式打开该选项。
当将一个Put集合提交到服务端的时候,可能会出现部分成功部分失败的情况,失败的数据会被保存到缓存区中进行重试。
HBase还提供了一个compare-and-set操作,这个操作先进行检查,条件满足后再执行,这个操作对于行是原子性的。HBase没有Update操作,是通过Put操作完成对数据的修改的。
3.3扫描Scan
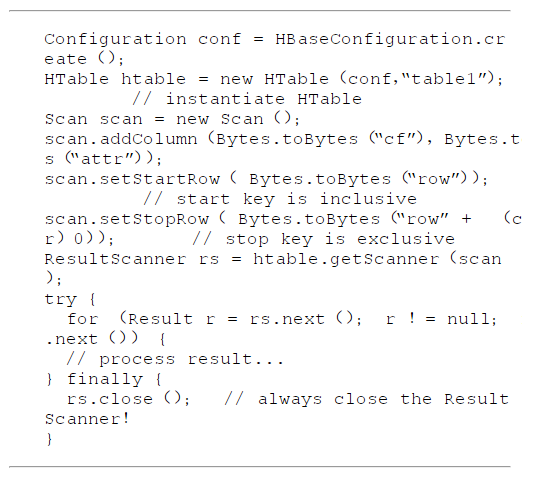
Scan操作允许多行特定属性迭代,其使用与get()方法非常类似。工作方式类似于迭代器,可以指定startRow参数来定义扫描读取HBase表的起始行键,同时可选stopRow参数来限定读取到何处停止。
扫描操作执行后将得到执行结果,此结果被封装在一个ResultScanner实例中。
3.4删除Delete
Delete用于从表中删除数据,除了此方法还有一个与之对应的类Delete,用户可以通过多种方法限定要删除的列。
与关系型数据库的Delete操作不同,HBase的Delete操作可以指定删除某个列族或者某个列,或者指定某个时间戳,删除比这个时间早的数据。HBase的Delete操作并不是真正地从磁盘删除数据。而是通过创建墓碑(tomb stones)标志进行处理。这些墓碑标记的值和小于该时间版本的单元格在大合并(major compact)时被清除。
四.数据模型的特殊属性
4.1版本
Rowkey、Column(列族和列)、Version组合在一起称为HBase中的一个单元格。有可能会有很多单元的行和列是相同的,要区分不同的单元可以使用版本。
Rowkey和Column的值是用字节数组表示的,Version则是用一个长整型表示的。
这个长整型值是使用java.util.Date.getTime()或者System.currentTimeMillis()产生的,
HBase中版本是如何工作的。
4.1.1含版本的操作
(1)Get/ScanGet是在Scan的基础上实现的。在默认情况下,如果没有指定版本,一旦使用Get操作,会返回最近版本的Cell
如果想要返回两个以上的版本,可以使用Get类的setMaxVersions(),如果想要返回的版本不只是最近的,可以使用Get类的setTimeRange()。
要想查询的最新版本小于或等于给定的这个值,这就意味着给定的“最近”的值可以是某一个时间点。可以使用0到想要的时间来设置,还要把MaxVersions设置为1。
默认Get例子如下,其中的Get操作会只获得最新的一个版本。

含有版本的Get例子如下,其中的Get操作会获得最近的3个版本。

(2)Put
一个Put操作会为一个Cell创建一个版本,默认使用当前时间戳,当然也可以自己设置时间戳,这就意味着可以把时间设置在过去或者未来,或者随意使用一个长整型值。
覆盖一个现有的值,就意味着新写入Cell的Rowkey、ColumnFamily、ColumnQulifier和Version必须和原来的完全相同。相当于update操作。
下面是不指明版本的例子,其中的Put操作不指明版本,所以HBase会将当前时间作为版本。

下面是指明版本的例子,其中的Put操作指明了版本。

(3)Delete
内部删除标记有三种不同类型:
·Delete:删除列的指定版本。
·DeleteColumn:删除列的所有版本。
·DeleteFamily:删除特定列族所有列。
当删除一行时,HBase将内部为每个列族创建墓碑(非每个单独列)标记。删除操作的实现是创建一个墓碑标记。
例如,要删除一个版本,HBase不会去改那些数据,数据不会立即从文件中删除。它使用删除标记来屏蔽掉这些值。如果被标记的是最新一个版本的数据,就意味着这一行中的所有数据都会被删除。
4.1.2现有的限制
(1)删除标记后错误读取新数据删除标记操作可能会标记其后Put的数据。注意,在写下一个墓碑标记后,只有下一个主合并(major compact)操作发起之后,墓碑标记才会清除。假设删除所有小于等于时间T的数据,但之后又执行了一个Put操作,
其时间戳小于等于T,那么就算这个Put发生在删除操作之后,该数据也会被打上墓碑标记。这个Put并不会失败,但你做Get操作时,则无法查询刚刚Put进去的数据。只有一个主合并(major compact)执行后,一切才会恢复正常。所以使用一系列时间戳一直增长的Put操作就不会发生该问题。
(2)主合并改变查询的结果一个Cell有三个版本数据t1、t2和t3,maxVersion设置为2,当请求获取全部版本的时候,只会返回两个:t2和t3。如果将t2和t3删除,就会返回t1。但是如果在删除之前,发生了major compaction操作,t1的值将会从磁盘上被彻底删除,结果是什么值都不会返回了。
4.2排序
Get和Scan操作返回的是经过排序的数据。
返回的数据首先按行字典序排序,其次是列族,然后是列修饰符(columnqualifier),最后是时间戳反向排序,最新的在最前面。
4.3列的元数据
对于HBase表中的列族,除了KeyValue实例以外,没有关于元数据的描述,KeyValue对象表示HBase的最小单位是Cell。HBase的表不仅在一行中支持很多列,而且支持行之间有不同的列,所以需要单独维护行和列之间的关系。
4.4连接查询
简单来说是不支持,至少不像传统RDBMS那样支持。正如前面描述的,读数据模型只有Get和Scan两种操作。但这并不表示Join查询不能在应用程序中使用,只是必须用户自己实现。一般来讲,实现方法有两种:要么写入HBase的时候已经做好连接;
要么查询表并在应用层实现连接。哪个更好?依赖于准备做什么,所以没有一个准确的答案适合所有情况。
4.5计数器
IncrementColumnValue(简称ICV)是HBase的计数器,可以把ICV等同于Java的AtomicLong.addAndGet()方法。
4.6原子操作
类似Java的原子类,HTableInterface接口也提供checkAndPut()和checkAndDelete()方法,它们可以在维持原子语义的同时提供更精细的控制。可以用checkAndPut()来实现上一节提到的incrementColumnValue()方法:

4.7事务特性ACID
传统的SQL数据库的事务通常都是支持ACID的强事务机制。而HBase这种NoSQL数据库仅提供对行级别的原子性保证,也就是说同时对同一个Key下的数据进行的两个操作,在实际执行的时候是会串行的执行,保证了每一个KeyValue对不会被破坏。
同一Region有多行原子性,因此对一个多Region表来说,还是无法保证每次修改都能封装为一个事务。HBase不是一个具备完整ACID特性的数据库,它只实现了某些属性。
4.8行锁
RegionServer提供了一个行锁特性,这个特性保证了只有一个客户端能获取一行数据相应的锁,同时对该行进行修改。
4.9自动分区
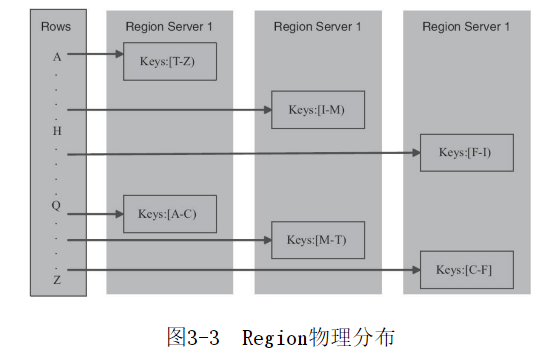
Region实际上是行键排序后的按规则分割的连续的存储空间。如果Region太大,会被动态拆分,相反,多个Region会合并成一个较大的Region,以减少HDFS上存储文件的数量。这两个过程就是HBase的split和compaction,
刚刚创建的表只有一个Region,随着数据的写入,达到Region上限配置值时,Region会按照中间键自动地拆分成两个大致相等的Region,每个Region由一个RegionServer管理,一个RegionServer处理器管理着许多的Region。
每个RegionServer可以管理大约100~1000个Region,每个Region的大小可以是1~20GB。
五.CAP原理与最终一致性
CAP原理是数据库软件的理论基础,它指出对于一个数据库系统来说,不可能同时满足以下三点:
·一致性(Consistency):所有节点在同一时间具有相同的数据。
·可用性(Availability):保证每个请求不管成功或者失败都有响应。
·分区容忍性(Partitiontolerance):系统中任意信息的丢失或失败不会影响系统的继续运作。
分布式数据库系统也只能满足三项中的两项。而由于当前的网络硬件肯定会出现延迟丢包等问题,所以分区容忍性是我们必须需要实现的,因此只能在一致性和可用性之间进行权衡,大多数的分布式数据库系统选择了牺牲一致性提高可用性。
HBase的设计基于这样一些方面考虑,首先不要求严格的数据库事务,保证数据最终一致即可;其次数据库的写入可能在几秒之后读取出来用户也是能够忍受的,也就是说不能实时地读取刚刚写入的数据,另外就是复杂SQL的查询在产品设计阶段就避免了,更多的查询集中在针对主键的查询。