涉及WGAN的论文总共三篇:
WGAN前作:Towards Principled Methods for Training Generative Adversarial Networks
WGAN:Wasserstein GAN
改进的WGAN:Improved Training of Wasserstein GANs
代码:各种GAN的实现
这三篇论文理论性都比较强,尤其是第一篇,涉及到比较多的理论公式推导。知乎郑华滨的两个论述令人拍案叫绝的Wasserstein GAN,Wasserstein GAN最新进展:从weight clipping到gradient penalty,更加先进的Lipschitz限制手法在理论方面已经做了一个很好的介绍。不过对于很多数学不太好的同学(包括我自己),看着还是不太好理解,所以这里尽量站在做工程的角度,理一下这三篇文章的思路,这样可以对作者的思路有一个比较清晰的理解。
GAN的Loss存在的问题
判别器的Loss:
原始生成器Loss:
Ian Goodfellow提出的改进的判别器Loss:
总结起来,就是,不管判别器的Loss是第一种设计还是第二种设计,训练到后面,判别器肯定是越来越好的,越来越趋近最优判别器的。可是问题就在于这里,为了得到最优判别器,这会导致梯度消失,collapse mode的现象。于是,作者提出了一个解决方案:
WGAN前作针对分布重叠问题提出了一个过渡解决方案,通过对生成样本和真实样本加噪声使得两个分布产生重叠,理论上可以解决训练不稳定的问题,可以放心训练判别器到接近最优,但是未能提供一个指示训练进程的可靠指标,也未做实验验证。 ------令人拍案叫绝的Wasserstein GAN
上面的一大段介绍不太可能看懂,总之就是作者通过一大堆数学推导,发现原始GAN的判别器Loss有问题,作者提了一个凑合的方案,但是也没实验,不知道行不行。我们接下来重点关注WGAN,也就是作者给出的解决方案是什么?至于作者给出的方案为什么能解决前面分析的问题,就需要去仔细琢磨公式了。
WGAN原理
前面提到了原始GAN使用的loss本质上来说是最小化KS散度,或者KL散度,这样是不合理的,于是作者就提出用Wasserstein距离来作为衡量两个分布之间的距离。作者根据Wasserstein距离又推导出了相应的Loss:
WGAN生成器Loss:
WGAN判别器Loss:
具体到代码实现层面:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
第四点是作者的经验得出的,前面三点都是有理论推导的。具体代码实现如下,注意判别器最后一层不要sigmoid,loss设计的时候不要log:
# 生成器loss
errG = -netD(inputNegative)
# 判别器loss
errD_real = netD(inputPostive)
errD_fake = netD(inputNegative)
errD = -errD_real + errD_fake
其实从代码实现上来看很直观,就是按照作者说的上面几个要点,把原始GAN的Loss改一下就好了。不过这样改的理由,作者却花了两篇论文来论述。
WGAN存在的问题
实际实验过程发现,WGAN没有那么好用,主要原因在于WAGN进行梯度截断。梯度截断将导致判别网络趋向于一个二值网络,造成模型容量的下降。
于是作者提出使用梯度惩罚来替代梯度裁剪。公式如下:
由于上式是对每一个梯度进行惩罚,所以不适合使用BN,因为它会引入同个batch中不同样本的相互依赖关系。如果需要的话,可以选择Layer Normalization。具体代码实现如下:
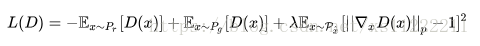
gradients = tf.gradients(pred, x)[0]
slopes = tf.sqrt(tf.reduce_sum(tf.square(gradients),reduction_indices=range(1, x.shape.ndims)))
gp = tf.reduce_mean((slopes - 1.)**2)
d_loss = errD + gp * lambda
总结
总的来说,WGAN的三篇论文,前两篇讨论loss设计导致的问题,提出了新的loss设计方式,公式推导比较复杂。不过代码实现起来很简答。本博客也重点关注其实现,以及简要说了一下loss公式的形式,忽略了许多中间的理论细节。有兴趣深挖的同学可以去翻一下论文原文。